The LANGUAGE variable is broken for English as main language
by Leandro Lucarella on 2020- 11- 18 11:38 (updated on 2020- 11- 18 11:38)- with 0 comment(s)
The LANGUAGE environment variable can accept multiple fallback languages (at least if your commands are using gettext), so if your main LANG is, say, es, but you also speak fr, then you can use LANGUAGE=es:fr.
But what happens when you main LANG is en, so for example your LANGUAGE looks like en:es:de? You'll notice some message that used to be in perfect English before using the multi-language fallback now seem to be shown randomly in es or de.
Well, it is not random. The thing is, since English tends to be the de-facto language for the original strings in a program, it looks like almost nobody provides an en translation, so when fallback is active, almost no programs will show messages in English.
For example, this is my Debian testing system with roughly 3.5K packages installed:
$ dpkg -l |wc -l 3522 $ ls /usr/share/locale/en/LC_MESSAGES/ | wc -l 12
Only 12 packages have a plain English locale. en_GB does a bit better:
$ ls /usr/share/locale/en_GB/LC_MESSAGES/ | wc -l 732
732 packages. This is still lower than both en and de:
$ ls /usr/share/locale/es/LC_MESSAGES/ | wc -l 821 $ ls /usr/share/locale/de/LC_MESSAGES/ | wc -l 820
The weird thing is packages as basic as psmisc (providing, for example, killall) and coreutils (providing, for example, ls) don't have an en locale, and psmisc doesn't provide es. This is why at some point it seemed like a random locale was being used. I had something like LANGUAGE=en_GB:en_US:en:es:de and I use KDE as my desktop environment. KDE seems to be correctly translated to en_GB, so I was seeing most of my desktop in English as expected, but when using killall, I got errors in German, and when using ls, I got errors in Spanish.
If you don't provide other fallback languages, gettext will automatically fall back to the C locale, which is the original strings embedded in the source code, which are usually in English, and this is why if you don't provide fallback languages (other than English at least), all will work in English as expected. Of course if you use C in your fallback languages, before any non-English language, then they will be ignored as the C locale should always be present, so that's not an option.
I find it very curious that this issue has almost zero visibility. At least my searches for the issue didn't throw any useful results. I had to figure it all out by myself like in the good old pre-stackoverflow times...
Note
I know is not a typical use case, as since almost all software use English for the C locale it hardly makes any sense to use fallback languages in practice if your main language is English. But theoretically it could happen, and providing an en translation is trivial.
Elephone P9000
by Leandro Lucarella on 2020- 11- 18 11:10 (updated on 2020- 11- 18 11:10)- with 0 comment(s)
Note
This post is really old (May 2016), but was never published for some reason. I'm publishing it now just as an archeological artifact :)
I usually don't do reviews for anything, but I want to write a few points about this phone, in part for folks out there to know, but also as some sort of internal reminder of the things I've been finding.
I should say before anything else that I'm basically comparing this phone against my previous one, a Samsung Galaxy S4 (I9505) using CyanogenMod.
The Elephone P900 is a super tempting device. Here are the main reasons why I chosen this phone (in bold my hard requirements, in italics things I didn't really care about but it was a good opportunity to try out):
- It has 4GB of RAM and fast CPU (octacore)
- It supports memory expansion (micro SD up to 256GB 8-)
- It has a very high screen to body ratio (about 83%, for comparison the Nexus 5 has 71% and the iPhone 5s has 61%). I was looking for a 5 inch phone, so to go for a 5.5 inch one, the overall size of the phone had to be as small as possible.
- It has USB Type-C (I thought if I'm getting a new phone, better to have the new shiny no-non-sense connector)
- It comes with Android 6 (I want either that or to be supported by CM)
- Decent battery (3000mAh, which I expected to last for a full day of intensive use)
- It has at least one "navigation button" (I don't want to lose part of my screen with software buttons)
- It has a Sony camera sensor with f/2.0 and laser focus, which is supposed to be of decent quality really fast to do focus. That said, I read some reviews not speaking well about the camera
- It has a rouged back (my S4 was a bit slippery)
- It costs less than €250 (here in Germany)
- It has wireless charging and quick charging
- It has a fingerprint reader
- It has a quite high-res frontal camera (8 megapixel)
- It supports dual-SIM although the second SIM shares the slot with the memory expansion, so is not something I'll be able to use anyway
So, after using it for about a couple of days, these are my findings:
The good:
- The build quality is very nice, it really looks like a high end phone. More than my old S4 (which is made of plastic, while the P9000 is metallic).
- Is very light, even when it's a few grams extra compared to the S4, you can't really feel it. For offering 0.5 extra inches of screen is quite impressive.
- It is fast. I wasn't expecting to notice a difference with the S4 really, basically because I don't feel the S4 is slow. But you can tell the difference. The P9000 is snappier.
- It looks beautiful (at least for my minimalistic taste). I never care much about looks, but I really like this phone (much more than the S4).
- Despite the big screen and feeling a bit too big at first, the size seems manageable and the extra screen space is useful.
- Now having a fingerprint reader will probably be a requirement for my next phone. I encrypt my phone and use a longish password to unlock it. Being able to unlock it securely with just one touch is a huge gain.
- It can be rooted. It took me a while to find the right flasher for Linux (you need the latest version of it), but I could do it, and even TWRP is available for it already, which gives me some hope about better ROMs, and maybe even CM, appearing in the future.
The Bad:
- The fingerprint reader sucks. I've seen a video review complaining about it, and even for this guy complaining it worked much better than for me. I would say in my case it succeeds reading my fingerprint about less than 20% of the time. I even registered my fingerprint like five 5 times, using different finger positions and it still fails most of the time, and after 3 or 5 failures you have to wait 30 seconds before being able to retry.
- The screen is not bright enough for a sunny day. You can still see the screen, but it's not as bright as the one in my old S4.
- The camera pretty much sucks too. The f/2.0 I don't know where is it, pictures are always quite noisy. The auto-focus is not faster than my old S4. The sensor is supposed to be good, so I guess they just screwed it with the lenses. Or maybe is a firmware thing? But I doubt it.
- The sound really SUCKS. I never thought about it before. Even when I listen to music a lot, I never had a good year and never could pick up on bad quality recordings for example. Is a blessing. But with this phone I noticed. It sounds like crap (and I'm not talking about the speaker, which is understandable, I'm talking about plugging earphones). When I noticed I thought it might be the album. I tried another one, and another one, and finally I compared the same files in my old S4 and... Oh boy. This new phone's audio just SUCKS SO BAD. It's the phone. I would say this was the final deal breaker for me.
- The battery can't take an intense full day of usage. It's basically the same as my old S4 (and I want an improvement on this area). If I use it just for a few messages and most of the time inside with WiFi, it can last 2 full days. If I take it outside using mobile data, and listen to music during a hold day, it barely last for a day. If I add to that using maps and the GPS having the screen on more time, like when I'm traveling, it can barely last more than half a day.
- The Android version is missing some features that I thought it was pure Android (not CM), like the Ambient Display (shows notifications in a dimmed screen), the LiveDisplay (adjust the screen color temperature according to the time of the day) and the Do Not Disturb mode(s). The keyboard doesn't support swiping (major drawback for me).
- The touchscreen is not very sensitive. I can tell the difference with the S4. Maybe the one in the S4 is too sensitive, sometimes it reacts without even contacting the glass, but in the P9000 sometimes I feel I have to press the glass too much to get it reacting. Some gestures are harder to do because of this (like swipe-up to unlock).
- Only one navigation button. Even when is better than nothing, I found much more convenient having 3 navigation buttons like the S4 provides.
- No multicolor notification light. The navigation button on the bottom also serves as a notification light, but it has only one color and the frequency can't be configured either (AFAIK). The S4 has a multi-color led, which let you know what kind of notification is there before you even look at the screen.
- USB Type-C is not popular enough yet. Even when this is not the phone's fault, I realized we are not there yet. Micro USB cables are everywhere out there. You'll never miss one. With Type-C you better carry your cable everywhere or buy a bunch, because you are all alone now.
So, even when the external quality is amazing and, even when I never cared about looks, it looks extremely nice too, it looks like the low price tag has to come from somewhere, and that somewhere is the internal components, which seems like they are not the best.
Still the quality-price ratio is quite impressive IMHO, on paper you have the same specs as an iPhone 6, or Samsung S7, at less than half the price. But I think I prefer to spend an extra few bucks to get higher internal components qualities (specially with the sound), so I will probably return this phone and continue looking for one. Also I miss my CM too much. I think I will have to settle for an older phone that's is supported by CM.
TODO:
- Fingerprint unlock and screen gestures makes the phone never enter deep sleep, nice features but until it's fixed it might be better to disable them, at least when you know you'll need some juice.
- Fingerprint starts working better after some use (only 2 or 3 attempts are needed)
- WiFi consumes more battery than mobile data (WTF!?)
- RoDrIgUeZsTyLe™ MODPACK V1.1
- Sound is saved (probably is not amazing, but I don't notice the obvious creepiness anymore). Praise the Lord!
- Touchscreen is more sensitive, not as the S4 but definitely an appreciable improvement.
- Battery life improved a lot. One day of moderate activity (for me) and still about 65% battery left. I used the phone for 12 hours after fully charged, and my usage pattern was: about 6 hours outside (using mobile data), about 40 minutes of music playing + GPS working in high accuracy mode. The rest inside using WiFi. I also did some messaging and internet use, but nothing too intensive. BetterBatteryStats reports: 66% (~8h) deep sleep (which is still low, I wonder what this phone could last if it were more aggressive about going to deep sleep), 8% (~1h) screen on. Wifi running 100% of the time (~12h). Battery consumption average was 3%/h. My guess is that with a similar usage, the S4 I would probably ended the day with not more than 30% or 40% battery.
- Ways to improve the battery life and fix other stuff: Xposed framework, but not supported yet. For example with "Amplify Battery Extender" I could disable the wakelock for the fingerprint or NlpWakelock. Wakelock Terminator might also help (also needs Xposed)
- For now using DisableService to disable NlpService from MTK NLP Service, the location seems to keep working fine. Another option is to put the GPS in device-only mode to avoid the NPL service from running.
- Install Xposed using Eragon 2.0 ROM:
- Install Xposed Material installer (3.0 alpha4) http://forum.xda-developers.com/xposed/material-design-xposed-installer-t3137758
- Edit /etc/init.d/07permissive and comment out the sleep 60
- Install Xposed framework v82 (not a newer one otherwise settings will force close)
- Battery life saved via update from 2016-05-31. Fingerprint reader and WiFi don't keep the phone awake anymore (5~10% awake when screen is off with both enabled).
Simplicity
by Leandro Lucarella on 2016- 04- 01 22:58 (updated on 2016- 04- 01 22:58)- with 0 comment(s)
This is mostly an article I want to save for myself about simplicity. It was originally written by Mark Ramm in the context of a Python web framework I used (TurboGears). The original article seems to be gone, but you can still find it in the Archive.org's Wayback Machine.
Here is a transcription:
What is Simplicity?(May 31st, 2006 by Mark Ramm)Simplicity is knowing when one more rock would be too many, and one less rock would be too few. But it’s not just knowing the right number of rocks, it’s also knowing which rocks are right, and how to arrange them.
As Brad reminds us, simplicity is not achieved merely by making something easier, or less complex.
Take away all the complexity, all the difficulty, and all of the details from anything and what you are left with is not simple: it’s just boring.
On the other hand, Simplicity embraces exactly the right details, the right difficulties, the right complexity, but because everything is tied together in the right way, you are left with a sense of clarity, and a sense that everything belongs exactly where it is. Simplicity is achieved when everything means something.
In other words, simplicity is defined by what you add — clarity, purpose, and intentionality — not by what you remove.
For those of us who write software, simplicity is not a simple thing to learn. Writing the TurboGears book and working with the amazing group of people who contribute to the project has been a learning experience for me. Everybody is focused on making the web development simpler — and it’s amazing how much experience and depth of understanding is necessary to create a simple interface. It’s easy to build an interface that solves 80% of the problem, or an interface that solves 200% of the problem, but it is hard to solve just the right problem, and to do it in a clean, clear, way.
Of course, every project has warts, and TurboGears re-uses other projects which also have warts. So there’s no way I can say that TurboGears has arrived. But the will is there, and the journey sure has been productive for me.
Incredible Machine - Hurricane Heart Attacks
by Leandro Lucarella on 2015- 08- 25 08:12 (updated on 2015- 08- 25 08:12)- with 0 comment(s)
The Black Keys - Turn incompressible
by Leandro Lucarella on 2014- 05- 06 22:33 (updated on 2014- 05- 06 22:33)- with 0 comment(s)
Maybe you heard about the new album from The Black Keys. Maybe you didn't. In any case, I don't want to talk about the album (which is good BTW), I want to talk about the album cover:

See how bad it looks? Now click on the image and see how good it looks (in terms of quality, the album cover is pretty ugly anyway :P). The thing is, this stupid pattern is very hard to compress, so even using a JPG quality of 90%, you get a quite big file size and a pretty crappy image quality (126KB for a 500x500 image is quite a lot, 294KB for PNG using compression 9). If you look at the big image, even the colors are different, so the image makes resizing algorithms also go nuts, the image looks darker (or is this just an ilusion because of the changed relationship between both colors?).
Try it yourself, download the image, resize it, save it with different formats and qualities.
Coincidence? I guess not.
The Day We Fight Back
by Leandro Lucarella on 2014- 02- 10 18:59 (updated on 2014- 02- 10 18:59)- with 0 comment(s)
On Anniversary of Aaron Swartz's Tragic Passing, Leading Internet Groups and Online Platforms Announce Day of Activism Against NSA Surveillance.
Participants including Access, Demand Progress, the Electronic Frontier Foundation, Fight for the Future, Free Press, BoingBoing, Reddit, Mozilla, ThoughtWorks, and more to come, will join potentially millions of Internet users to pressure lawmakers to end mass surveillance -- of both Americans and the citizens of the whole world.
Oscar
by Leandro Lucarella on 2013- 12- 17 20:26 (updated on 2013- 12- 17 20:26)- with 0 comment(s)
First Flattr
by Leandro Lucarella on 2013- 11- 16 00:24 (updated on 2013- 11- 16 00:24)- with 0 comment(s)
9 months ago I decided to try Flattr. I created an account, put some money on it, started flattring and made myself flattrable. But nothing happened. Also sometimes you don't know if the people you are flattring will even reclaim your flattrs (in services that automatically provides flattr links).
Conclusion, I got quite disappointed. But today I see the light again, as I received my first and only flattr (for eventxx). Thanks whoever you are, anonymous hero, you brought hope again to humanity :P
Anyway, I'll try to give it a shot again, and try to keep the wheel moving.
You should do that too.
Radiohead Nude via zx80+printer+scanner+hdd
by Leandro Lucarella on 2013- 04- 13 20:53 (updated on 2013- 04- 13 20:53)- with 0 comment(s)
Fucking awesome, be patient for the first minute...
The Money Myth
by Leandro Lucarella on 2013- 02- 21 21:13 (updated on 2013- 02- 21 21:13)- with 0 comment(s)
Flattr
by Leandro Lucarella on 2013- 02- 17 21:02 (updated on 2013- 02- 17 21:02)- with 0 comment(s)
I learned that Flattr, a social micropayment service that I've been overlooking for a long time, was created by some of the founders of The Pirate Bay after watching TPB AFK.
I'm trying to donate (or pay) more and more to people using alternative means to produce stuff, like artists using CC licenses or software developers working with free licenses (I already bought a copy of the movie :). I feel like I have to get more involved to keep the wheel spinning and help people keep doing stuff, cutting the intermediaries as much as possible.
I don't know why I had some resistance to get into Flattr, maybe is because Facebook made me hate anything that have a thumbs up, or a +1 or counter, but knowing the history behind it a little better encouraged me to finally get an account and start using Flattr. And is really nice. Is much easier than going through Paypal each time a want to give some bucks to someone, and allows you to even make very small donations.
I recommend to see this introductory video:
I also decided to flattr-ize all my website, each project individually and even this blog. Not exactly for economical reasons (I think very few people know about anything I do so I don't really expect to earn any money from this), but as another way to spread the word. Also, I'm really curious about what I just said, I really wonder if there is someone out there grateful enough to make even a micro-donation to anything I do or did :)
Anyway, I would like to recommend to do the same, if you do something great, add a Flattr button to what you do, and if you like something out there and it has a Flattr, click it. Let's see if it helps to keep the wheel spinning :)
TPB AFK
by Leandro Lucarella on 2013- 01- 13 20:01 (updated on 2013- 01- 13 20:01)- with 0 comment(s)
Toshiba Satellite/Portege Z830/R830 frequency lock (and BIOS upgrade)
by Leandro Lucarella on 2012- 11- 28 23:21 (updated on 2012- 11- 28 23:21)- with 0 comment(s)
Fuck! I bought this extremely nice ultrabook, the Toshiba Satellite Z830-10J, about an year ago, and I've been experiencing some problems with CPU frequency scaling.
At one point I looked and looked for kernel bugs without much success. I went through several kernel updates in the hope of this being fixed, but never happened.
It seemed that the problem wasn't so bad after all, because I only got the CPU frequency locked down to the minimum when using the ondemand scaling governor, but the conservative was working apparently OK.
Just a little more latency I thought, is not that bad.
Recently I received an update on a related bug and I thought about giving it another shot. This mentioned something about booting with processor.ignore_ppc=1 to ignore some BIOS warning about temperature to overcome some faulty BIOS, so I thought on trying that.
But before doing, if this were a real BIOS problem, I thought about looking for some BIOS update. And there was one. The European Toshiba website offered only a Windows program to do the update though, but fortunately I found in a forum a suggestion about using the non-European BIOS upgrade instead, which was provided also as an ISO image. The problem is I don't have a CD-ROM, but that shouldn't stop me, I still have USB sticks and hard-drives, how hard could it be? I failed with UNetbootin but quickly found a nice article explaining how to boot an ISO image directly with grub.
BIOS upgraded, problem not fixed. So I was a about to try the kernel parameter when I remembered I saw some other article when googling desperately for answers suggesting changing some BIOS options to fix a similar problem.
So I though about messing with the BIOS first instead. The first option I saw that looked a little suspicious was in:
PowerManagement
-> BIOS Power Management
-> Battery Save Mode (using custom settings)
-> Processor Speed
<Low>
That is supposed to be only for non-ACPI capable OS, so I thought it shouldn't be a problem, but I tried with <High> instead.
WOW!!!
I start noticing the notebook booting much faster, but I thought maybe it was all in my mind...
But no, then my session opened way faster too, and everything was extremely faster. I think maybe about twice as fast. Everything feels a lot more responsive too. I can't believe I spend almost an year with this performance penalty. FUCKING FAULTY BIOS. I didn't make any battery life comparisons yet, but my guess is everything will go well, because it should still consume very little power when idle.
Anyway, lesson learned:
Less blaming to the kernel, more blaming to the hardware manufacturers.
But I still want to clarify that I love this notebook. I found it a perfect combination between features, weight and battery life, and now that it runs twice as fast (at least in my brain), is even better.
Hope this is useful for someone.
SecurityKiss + Dante == bye bye censorship
by Leandro Lucarella on 2012- 11- 25 20:00 (updated on 2012- 11- 28 21:28)- with 3 comment(s)
I live in Germany, and unfortunately there is something in Germany called GEMA, which basically censor any content that "might have copyrighted music".
Among the sites being censored are Grooveshark (completely banned) and YouTube (only banned if the video might have copyrighted music according to some algorithm made by Google). Basically this is because GEMA want these company to pay royalties for each time some copyrighted song get streamed). AFAIK Grooveshark don't want to pay at all, and Google want to pay a fixed fee (which is what it does in every other country), because it makes no sense to do otherwise, since anyone can just endlessly get a song streamed over and over again just to be paid.
Even when the model is debatable, there is a key aspect and why I call this censorship: not all the banned content is copyrighted or protected by GEMA.
- In Grooveshark there are plenty of bands that release their music using more friendly license, like CC.
- There are official videos posted in YouTube by the bands themselves and embedded in the band official website that is banned by GEMA.
- There are videos in YouTube that doesn't have copyrighted music at all, but they have to cover their asses and ban everything suspicious just in case.
- The personal videos that do have copyrighted music get banned completely, not only muted.
These are just the examples that pop on my mind now.
There are plenty of ways to bypass this censorship and they are the only way to access legal content in Germany that gets unfairly banned, not only harming the consumers, but also the artists, because most of the time having their music exposed in YouTube only spreads the word and do more good than harm.
HideMyAss is a popular choice for a web proxy. But I like SecurityKiss, a free VPN (up to 300MB per day), because it gives a more comprehensive solution.
But here comes the technical chalenge! :) I don't want to route all my traffic through the VPN, or to have to turn the VPN on and off again each time I want to see the censored content. What I want is to see some websites through the VPN. A challenge that proved to be harder than I initially thought and why I'm posting it here.
So the final setup I got working is:
- OpenVPN to use SecurityKiss free VPN service.
- Dante Socks Server to route any application capable of using a socks server through the VPN.
- FoxyProxy Firefox extension to selectively route YouTube and Grooveshark through the Socks proxy.
And here is how I did it (in Ubuntu 12.10):
OpenVPN server
Install the package:
sudo apt-get install openvpn
Get the configuration bundle generated for you account in the control panel and then create a /etc/openvpn/sk.conf file with this content:
client dev tunsk proto udp # VPN server IP : PORT # (pick the server you want from the README file in the bundle) remote 178.238.142.243 123 nobind ca /etc/ssl/private/openvpn-sk/ca.crt cert /etc/ssl/private/openvpn-sk/client.crt key /etc/ssl/private/openvpn-sk/client.key comp-lzo yes persist-key persist-tun user openvpn group nogroup auth-nocache script-security 2 route-noexec route-up "/etc/openvpn/sk.setup.sh up" down "/usr/bin/sudo /etc/openvpn/sk.setup.sh down"
Install the certificate and key files from the bundle in /etc/ssl/private/openvpn-sk/ with the names specified in the sk.conf file.
Create the tun device:
mknod /dev/net/tunsk c 10 200
Start the VPN at system start (optional):
echo 'AUTOSTART="sk"' >> /etc/default/openvpn
Add the openvpn system user:
adduser --system --home /etc/openvpn openvpn
Now we need to route some specific traffic only through the VPN. I choose to discriminate traffic by the uid/gid of the application that generated it. So with the route-up and down script we will do all the special routing. I also want my default route table to be untouched, that's why I used route-noexec. Here is how the /etc/openvpn/sk.setup.sh script looks for me:
#!/bin/sh
# Based on:
# http://serverfault.com/questions/345111/iptables-target-to-route-packet-to-specific-interface
#exec >> /tmp/log
#exec 2>> /tmp/log.err
#set -x
# Config
uid=skvpn
gid=skvpn
mark=100
table=$mark
priv_dev=br-priv
env_file="/var/run/openvpn.sk.env"
umark_rule="OUTPUT -t mangle -m owner --uid-owner $uid -j MARK --set-mark $mark"
gmark_rule="OUTPUT -t mangle -m owner --gid-owner $gid -j MARK --set-mark $mark"
masq_rule="POSTROUTING -t nat -o $dev -j SNAT --to-source $ifconfig_local"
up()
{
# Save environment
env > $env_file
# Route all traffic marked with $mark through route table $table
ip rule add fwmark $mark table $table
# Make all traffic go through the VPN gateway in route table $table
ip route add table $table default via $route_vpn_gateway dev $dev
# Except for the internal traffic
ip route | grep "dev $priv_dev" | \
xargs -n1 -d'\n' echo ip route add table $table | sh
# Flush route tables cache
ip route flush cache
# Mark packets originated by processes with owner $uid/$gid with $mark
iptables -A $umark_rule
iptables -A $gmark_rule
# Prevent the packets sent over $dev getting the LAN addr as source IP
iptables -A $masq_rule
# Relax the reverse path source validation
sysctl -w "net.ipv4.conf.$dev.rp_filter=2"
}
down()
{
# Restore and remove environment
. $env_file
rm $env_file
# Since the device is already removed, there is no need to clean
# anything that was referencing the device because it was already
# removed by the kernel.
# Delete iptable rules
iptables -D $umark_rule
iptables -D $gmark_rule
# Delete route table and rules for lookup
ip rule del fwmark $mark table $table
# Flush route tables cache
ip route flush cache
}
if test "$1" = "up"
then
up
elif test "$1" = "down"
then
down
else
echo "Usage: $0 (up|down)" >&2
exit 1
fi
I hope this is clear enough. Finally we need to add the skvpn user/group (for which all the traffic will be routed via the VPN) and let the openvpn user run the setup script:
sudo adduser --system --home /etc/openvpn --group skvpn sudo visudo
In the editor, add this line:
openvpn ALL=(ALL:ALL) NOPASSWD: /etc/openvpn/sk.setup.sh
Now if you do:
sudo service openvpn start
You should get a working VPN that is only used for processes that runs using the user/group skvpn. You can try it with:
sudo -u skvpn wget -qO- http://www.securitykiss.com | grep YOUR.IP
Besides some HTML, you should see the VPN IP there instead of your own (you can check your own by running the same without sudo -u skvpn).
Dante Socks Server
This should be pretty easy to configure, if it weren't for Ubuntu coming with an ancient (1.x when there is a 1.4 beta already) BROKEN package. So to make it work you have to compile it yourself. The easiest way is to get a sightly more updated package from Debian experimental. Here is the quick recipe to build the package, if you want to learn more about the details behind this, there is always Google:
cd /tmp for suffix in .orig.tar.gz -3.dsc -3.debian.tar.bz2 do wget http://ftp.de.debian.org/debian/pool/main/d/dante/dante_1.2.2+dfsg$suffix done sudo apt-get build-dep dante-server dpkg-source -x dante_1.2.2+dfsg-3.dsc cd dante_1.2.2+dfsg dpkg-buildpackage -rfakeroot cd .. dpkg -i /tmp/dante-server_1.2.2+dfsg-3_amd64.deb
Now you can configure Dante, this is my configuration file as an example, it just allow unauthenticated access to all clients in the private network:
logoutput: syslog
internal: 10.1.1.1 port = 1080
external: tunsk
clientmethod: none
method: none
user.privileged: skvpn
user.unprivileged: skvpn
user.libwrap: skvpn
client pass {
from: 10.1.1.0/24 port 1-65535 to: 0.0.0.0/0
log: error # connect disconnect
}
client pass {
from: 10.1.1.0/24 port 1-65535 to: 0.0.0.0/0
}
#generic pass statement - bind/outgoing traffic
pass {
from: 0.0.0.0/0 to: 0.0.0.0/0
command: bind connect udpassociate
log: error # connect disconnect iooperation
}
#generic pass statement for incoming connections/packets
pass {
from: 0.0.0.0/0 to: 0.0.0.0/0
command: bindreply udpreply
log: error # connect disconnect iooperation
}
I hope you get the idea...
Now just start dante:
sudo service danted start
And now you have a socks proxy that output all his traffic through the VPN while any other network traffic goes through the normal channels!
FoxyProxy Addon
Setting up FoxyProxy should be trivial at this point (just create a new proxy server pointing to dante and set it as SOCKS v5), but just as a pointer, here are some example rules (set them as Whitelist and Regular Expression):
^https?://(.*\.)?youtube\.com/.*$ ^https?://(.*\.)?grooveshark\.com/.*$
PulseAudio flat volumes
by Leandro Lucarella on 2012- 11- 06 20:57 (updated on 2012- 11- 06 20:57)- with 0 comment(s)
Just a quick note because it took me ages to find out how to do it.
I don't really use the feature of pulseaudio that gives every application their own volume instead of manipulating the master volume directly, and lately it became more and more a problem, as I want to use applications like mpd or xbmc that allow remote controlling, and for that having separate volumes makes no sense.
I managed to fix it in mpd once, by using a mixed setup, using pulse as output, but the hardware alsa mixer, but for xbmc I couldn't find a way.
So that made me think if I really wanted the split volumes thingy, and the answer was no. After looking for hours for how to do it, the answer is pretty trivial. Just edit /etc/pulse/daemon.conf and change the flat-volumes option to yes.
You are welcome.
George Carlin on religion and God
by Leandro Lucarella on 2012- 10- 19 13:10 (updated on 2012- 10- 19 13:10)- with 0 comment(s)
A little old, but always fun!
F.A.T.
by Leandro Lucarella on 2012- 10- 15 10:44 (updated on 2012- 10- 15 22:40)- with 0 comment(s)
Reminds me a little of The Yes Men.
Update
You might want to take a look at the other videos from the PBS Off Book series if you liked this one.
Declassified U.S. Nuclear Test Film #55
by Leandro Lucarella on 2012- 10- 09 10:11 (updated on 2012- 10- 09 13:11)- with 0 comment(s)
Update
I'm sorry, youtube related feature is too dangerous :P. This is a timeline of all the nuclear bombs dropped between 1945 and 1998. It starts slow, but don't worry, it will speed up to reach the 2000+ bombs dropped in that period, more than 50% by USA. Is funny they use "might have weapons of mass destruction" as an excuse to invade countries when they are by far the country that dropeed the most nuclear bombs. Maybe they dropped them all and now they have none :P
Stuart Murdoch stake on Spotify and music streaming companies
by Leandro Lucarella on 2012- 10- 04 22:45 (updated on 2012- 10- 04 22:45)- with 0 comment(s)
OK, first of all, this is pretty old (more than one year) but I just bumped into it and it seems interesting enough for me to post it.
Belle & Sebastian's singer, Stuart Murdoch, have posted his mind about Spotify and music streaming services, which apparently are ripping off artists way worse even than traditional record companies (see graph below).
I'll transcribe the part of the post found most interesting (well, it's actually almost the whole post) for convenience (bold added by me), but you can read the whole post for unbiased and complete information :)
[...] Ok, now my point, and probably my only important point: I’m certainly not against ‘the generation who no longer pay for music.’ That horse has bolted. And hey, I like that horse! It’s free and young and happy and doing its horsey thing.
What has had me conflicted is Spotify itself. Overnight, this thing appeared called Spotify, claiming it was a great idea, innovative, the saviour of the industry. From what I can gather, and no one has been able to tell me differently, it’s financed by a gathering of the top (ie. richest) people, from the top (ie. richest) record labels.
Overnight, the whole Belle And Sebastian back catalogue became available to stream, for anybody, for free, for good. We weren’t asked about it.
“How were you not asked?” I can imagine you would say. That’s exactly what I asked the record label. Their answer was not that informative. They mumbled something about a distribution company, that was under some umbrella; that it wasn’t up to them.
Can I just stress that Rough Trade is certainly not one of the aforementioned ‘richest’ record companies. I feel a bit bad for them. I’m gathering that they thought they had nothing to lose with the Spotify thing, that they had to try something new. (Kids, if there’s a less viable career choice than ‘independent recording artist’ at the minute, I would certainly say it was ‘independent record label.’)
Anyway, that’s enough of the angst. I’ve said it to the rest of the band, and I’ll say it again, “just because we’re in a band, it doesn’t make it a bloody pension plan”. We’ve had, and continue to have, a brilliant time making music and playing music and dreaming, and just about getting away with it. If it just got harder, then that’s because it should be hard. I think in the end it will make the music, the art, better.
I’m not even so much against Spotify. If they can get their model right, ie pay the bands something approaching appropriate amounts, then it will be all ok. I’m ready to throw my lot in with them; I mean, I use it now. And if I was 19 I would have used it too. (Would have used it to decide which vinyl/music to buy/see, as I’m sure lots of people still do)
It just seemed rich of them that they decided to charge everyone. They lured everyone in with ‘Our’ music (the royal ‘Our’), which they didn’t pay for, and now, probably because a shareholder somewhere is sitting in a Porsche, crying for a dividend, they’re going to charge money in our name. And I will eat my beloved black hat if we ever see a share. [...]
Another very interesting bit of information is the one provided in one of the comments, a nice graph about how much money artists get according to the distribution method, which I will also put here for convenience (I hope the author don't mind).
It would be nice to see an update including more open-license friendly services like Bandcamp, Magnatunes or Jamendo.

The hipsterest garage sale ever
by Leandro Lucarella on 2012- 10- 02 18:37 (updated on 2012- 10- 02 18:37)- with 0 comment(s)

The hipsterest garage sale ever
Firefox advertisment in Berlin's public transport
by Leandro Lucarella on 2012- 10- 01 17:14 (updated on 2012- 10- 01 23:01)- with 0 comment(s)
This is in the subway, there are huge banners in the bigger train stations too.
Esto está en el subte, también hay carteles enormes en las estaciones más grandes de tren.

Big ideals for small screens / Grandes ideales para pequeñas pantallas

We work for you, not for shareholders / Trabajamos para usted, no para accionistas
Translation of e-mails using Mutt
by Leandro Lucarella on 2012- 09- 24 12:45 (updated on 2012- 10- 02 12:58)- with 0 comment(s)
Update
New translation script here, see the bottom of the post for a description of the changes.
I don't like to trust my important data to big companies like Google. That's why even when I have a GMail, I don't use it as my main account. I'm also a little old fashion for some things, and I like to use Mutt to check my e-mail.
But GMail have a very useful feature, at least it became very useful since I moved to a country which language I don't understand very well yet, that's not available in Mutt: translation.
But that's the good thing about free software and console programs, they are usually easy to hack to get whatever you're missing, so that's what I did.
The immediate solution in my mind was: download some program that uses Google Translate to translate stuff, and pipe messages through it using a macro. Simple, right? No. At least I couldn't find any script to do the translation, because Google Translate API is now paid.
So I tried to look for alternatives, first for some translation program that worked locally, but at least in Ubuntu's repositories I couldn't find anything. Then for online services alternatives, but nothing particularly useful either. So I finally found a guy that, doing some Firebuging, found how to use the free Google translate service. Using that example, I put together a 100 SLOC nice general Python script that you can use to translate stuff, piping them through it. Here is a trivial demonstration of the script (gt, short for Google Translate... Brilliant!):
$ echo hola mundo | gt hello world $ echo hallo Welt | gt --to fr Bonjour tout le monde
And here is the output of gt --help to get a better impression on the script's capabilities:
usage: gt [-h] [--from LANG] [--to LANG] [--input-file FILE]
[--output-file FILE] [--input-encoding ENC] [--output-encoding ENC]
Translate text using Google Translate.
optional arguments:
-h, --help show this help message and exit
--from LANG, -f LANG Translate from LANG language (e.g. en, de, es,
default: auto)
--to LANG, -t LANG Translate to LANG language (e.g. en, de, es, default:
en)
--input-file FILE, -i FILE
Get text to translate from FILE instead of stdin
--output-file FILE, -o FILE
Output translated text to FILE instead of stdout
--input-encoding ENC, -I ENC
Use ENC caracter encoding to read the input (default:
get from locale)
--output-encoding ENC, -O ENC
Use ENC caracter encoding to write the output
(default: get from locale)
You can download the script here, but be warned, I only tested it with Python 3.2. It's almost certain that it won't work with Python < 3.0, and there is a chance it won't work with Python 3.1 either. Please report success or failure, and patches to make it work with older Python versions are always welcome.
Ideally you shouldn't abuse Google's service through this script, if you need to translate massive texts every 50ms just pay for the service. For me it doesn't make any sense to do so, because I'm not using the service differently, when I didn't have the script I just copy&pasted the text to translate to the web. Another drawback of using the script is I couldn't find any way to make it work using HTTPS, so you shouldn't translate sensitive data (you shouldn't do so using the web either, because AFAIK it travels as plain text too).
Anyway, the final step was just to connect Mutt with the script. The solution I found is not ideal, but works most of the time. Just add these macros to your muttrc:
macro index,pager <Esc>t "v/plain\n|gt|less\n" "Translate the first plain text part to English" macro attach <Esc>t "|gt|less\n" "Translate to English"
Now using Esc t in the index or pager view, you'll see the first plain text part of the message translated from an auto-detected language to English in the default encoding. In the attachments view, Esc t will pipe the current part instead. One thing I don't know how to do (or if it's even possible) is to get the encoding of the part being piped to let gt know. For now I have to make the pipe manually for parts that are not in UTF-8 to call gt with the right encoding options. The results are piped through less for convenience. Of course you can write your own macros to translate to another language other than English or use a different default encoding. For example, to translate to Spanish using ISO-8859-1 encoding, just replace the macro with this one:
macro index,pager <Esc>t "v/plain\n|gt -tes -Iiso-8859-1|less\n" "Translate the first plain text part to Spanish"
Well, that's it! I hope is as useful to you as is being to me ;-)
Update
Since picking the right encoding for the e-mail started to be a real PITA, I decided to improve the script to auto-detect the encoding, or to be more specific, to try several popular encodings.
So, here is the help message for the new version of the script:
usage: gt [-h] [--from LANG] [--to LANG] [--input-file FILE]
[--output-file FILE] [--input-encoding ENC] [--output-encoding ENC]
Translate text using Google Translate.
optional arguments:
-h, --help show this help message and exit
--from LANG, -f LANG Translate from LANG language (e.g. en, de, es,
default: auto)
--to LANG, -t LANG Translate to LANG language (e.g. en, de, es, default:
en)
--input-file FILE, -i FILE
Get text to translate from FILE instead of stdin
--output-file FILE, -o FILE
Output translated text to FILE instead of stdout
--input-encoding ENC, -I ENC
Use ENC caracter encoding to read the input, can be a
comma separated list of encodings to try, LOCALE being
a special value for the user's locale-specified
preferred encoding (default: LOCALE,utf-8,iso-8859-15)
--output-encoding ENC, -O ENC
Use ENC caracter encoding to write the output
(default: LOCALE)
So now by default your locale's encoding, utf-8 and iso-8859-15 are tried by default (in that order). These are the defaults that makes more sense to me, you can change the default for the ones that makes sense to you by changing the script or by using -I option in your macro definition, for example:
macro index,pager <Esc>t "v/plain\n|gt -IMS-GREEK,IBM-1148,UTF-16BE|less\n"
Weird choice of defaults indeed :P
The day CouchSurfing died
by Leandro Lucarella on 2012- 09- 13 16:08 (updated on 2012- 09- 14 13:54)- with 0 comment(s)
Some time ago CouchSurfing announced that they will become a socially responsible B-Corporation. In case you forgot about it, here is what the creators of this utopic project said then:
I believed them, and when everybody went bananas about it I thought there was some extremism and overreaction. After all, you need money to maintain the structure for a service like CS and if this change would help, it was fine with me as long as the spirit of the community was the same.
Unfortunately, now I think all these people were right. A few days ago CS announced a change in the terms of usage and privacy policy. The new ones include terms as stupid and abusive as:
5.3 Member Content License. If you post Member Content to our Services, you hereby grant us a perpetual, worldwide, irrevocable, non-exclusive, royalty-free and fully sublicensable license to use, reproduce, display, perform, adapt, modify, create derivative works from, distribute, have distributed and promote such Member Content in any form, in all media now known or hereinafter created and for any purpose, including without limitation the right to use your name, likeness, voice or identity.
They also removed all mention about being a socially responsible B-Corp, so, where is this heading at? I don't have a Facebook account because I appreciate my privacy and feel like FB never cared about it (among other things), but this terms of CS makes FB looks like the EFF!
Here is one of the many related discussions about the issue inside CS forums:
http://www.couchsurfing.org/group_read.html?gid=7621&post=13000298
People are even making complaints in their's respective country data protection and privacy agencies. But I see little sense in it, at least from a point of view of being part of CS. Even if they fix now the terms to be more reasonable, I don't want to be part of it any more.
So, from tomorrow all the content you leave in CS will be theirs forever, irrevocably. Unfortunately there is no way to opt out, or keep the old content under the old terms, so they give me no option but to remove all the content I don't want to give them perpetual, irrevocable, sublicensable, etc. rights to. And that's what I'm doing right now.
I think for now I will keep my account open (with fake information about me, even when I'm violation the terms and conditions which says I should provide truthful information about me) because there is still a great community behind it and I don't want to loose all contact with it. But my plan is to start using BeWelcome.org instead, hoping they don't eventually follow the same path CS did (their website is open source so at least there is a chance to clone the service if they do).
So, thanks for all the good times CS, and RIP!
Update
It looks like CS needs more time to see the situation, in the terms and conditions page now says the new terms are going to be applicable starting on the 21st instead of the 14th of September.
Also, the issue hit the media, at least in Germany (Google translate is your friend):
- http://www.fr-online.de/digital/datenschutz-couchsurfing-will-nutzerdaten-weitergeben,1472406,17241654.html
- http://www.zeit.de/digital/datenschutz/2012-09/couchsurfing-nutzungsbedingungen-datenschutz
- http://www.heise.de/newsticker/meldung/Datenschuetzer-kritisiert-neue-Nutzungsbedingungen-von-CouchSurfing-org-1706833.html
- http://www.bfdi.bund.de/DE/Oeffentlichkeitsarbeit/Pressemitteilungen/2012/18_CouchSurfing.html?nn=408908
Anyway, as I said before, even if they fix the terms, is game over for me, all trust in CS being a community rather than just another company trying to do data mining is gone.
Escaleascensor mecánico
by Leandro Lucarella on 2012- 08- 09 13:29 (updated on 2012- 08- 09 13:29)- with 0 comment(s)
Está en el edificio donde está la Embajada Argentina en Berlín.
Release: Status Area Display Blanking Applet 1.0 for Maemo
by Leandro Lucarella on 2012- 08- 05 12:54 (updated on 2012- 08- 05 12:54)- with 0 comment(s)
Finally 1.0 is here, and in Extras-devel! The only important change since last release is a bug fix that prevented display blanking inhibition from properly work in devices configured with a display blanking timeout of less than 30 seconds (thanks cobalt1 for the bug report).
For more information and screenshots, you can visit the website.
You can download this release (binary package and sources) from here:
- https://llucax.com.nyud.net/proj/sadba/files/1.0/
- http://maemo.org/packages/view/status-area-displayblanking-applet/
But now you just might want to simply install it using the application manager.
You can also get the source from the git repository:
https://git.llucax.com/w/software/sadba.git
Please feel free to leave your comments and suggestions here or in the Maemo Talk Thread..
Release: Status Area Display Blanking Applet 0.9 (beta) for Maemo
by Leandro Lucarella on 2012- 07- 30 22:35 (updated on 2012- 07- 30 22:35)- with 0 comment(s)
Final beta release for the Status Area Display Blanking Applet. Changes since last release:
- Show a status icon when display blanking is inhibited.
- Improve package description and add icon for the Application Manager.
- Add a extended description for display blanking modes.
- Update translation files.
- Code cleanup.
Also now the applet have a small home page and upload to Extras is on the way!
This is how this new version looks like:
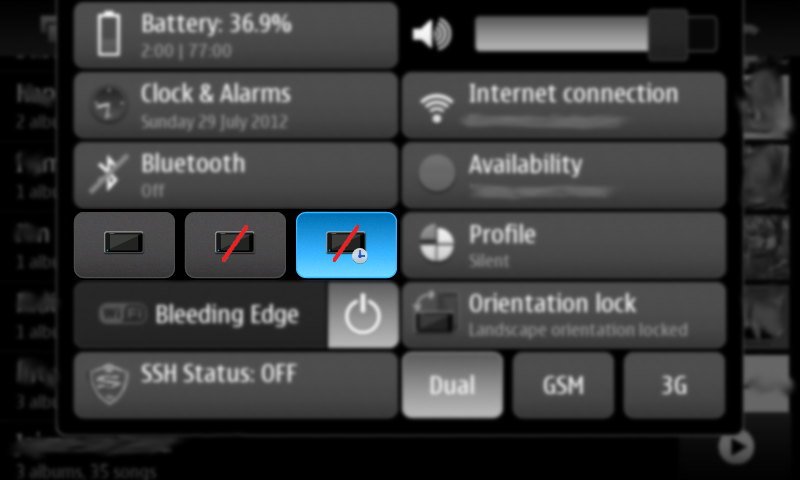
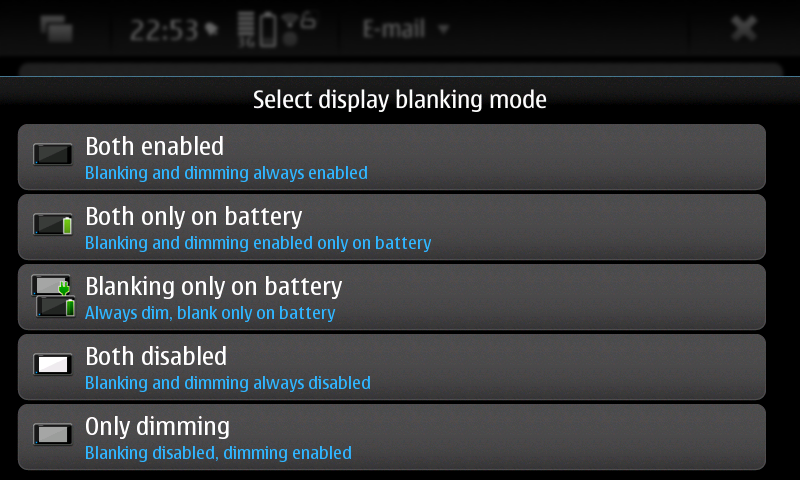
You can download this 0.9 beta release (binary package and sources) from here: https://llucax.com.nyud.net/proj/sadba/files/0.9/
You can also get the source from the git repository: https://git.llucax.com/w/software/sadba.git
Please feel free to leave your comments and suggestions here or in the Maemo Talk Thread..
Release: Status Area Display Blanking Applet 0.5 for Maemo
by Leandro Lucarella on 2012- 07- 29 18:55 (updated on 2012- 07- 29 18:55)- with 0 comment(s)
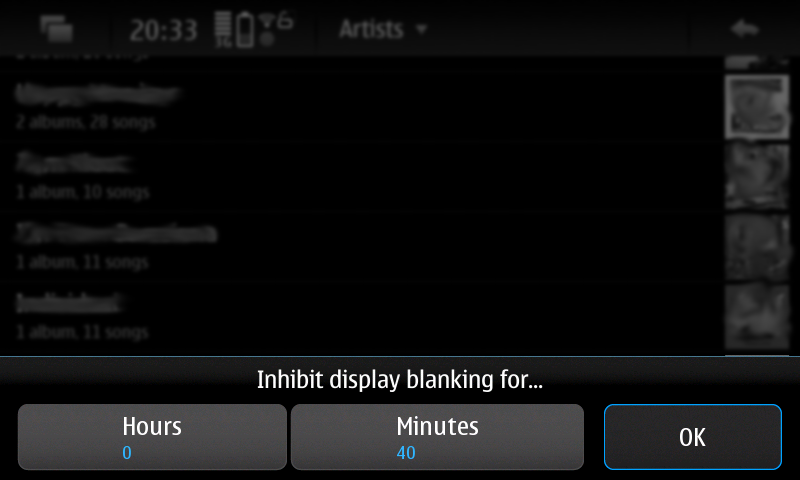
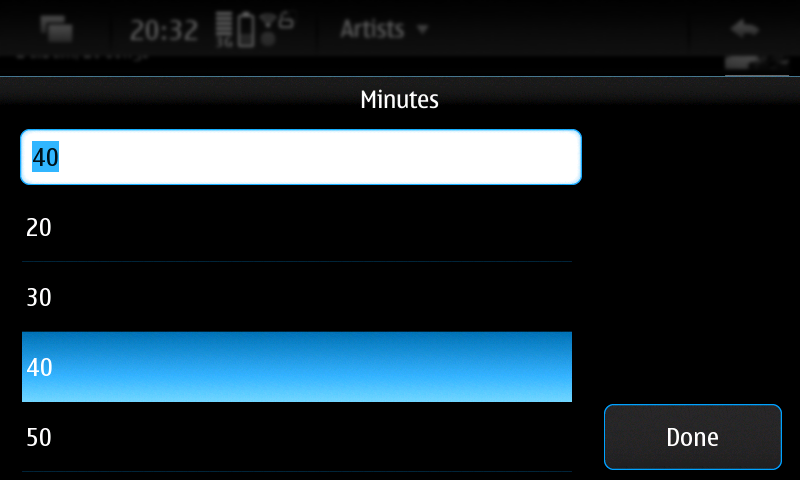
New pre-release for the Status Area Display Blanking Applet. New timed inhibition button that inhibit display blanking for an user-defined amount of time. Also there's been some code cleanup since last release.
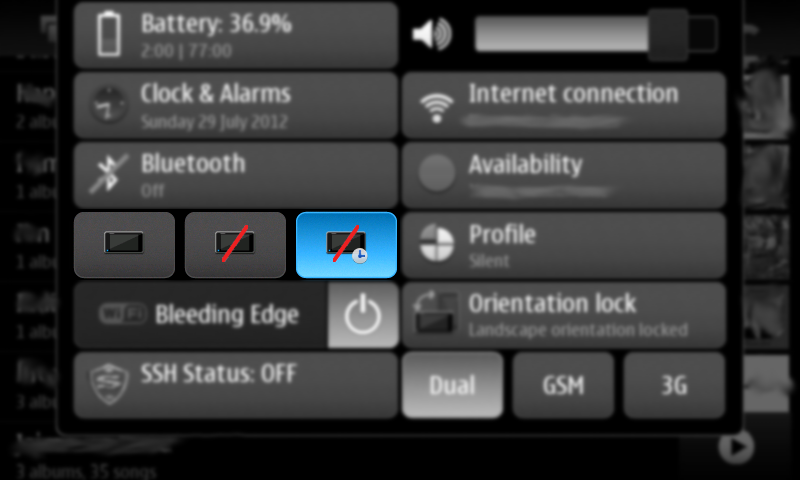
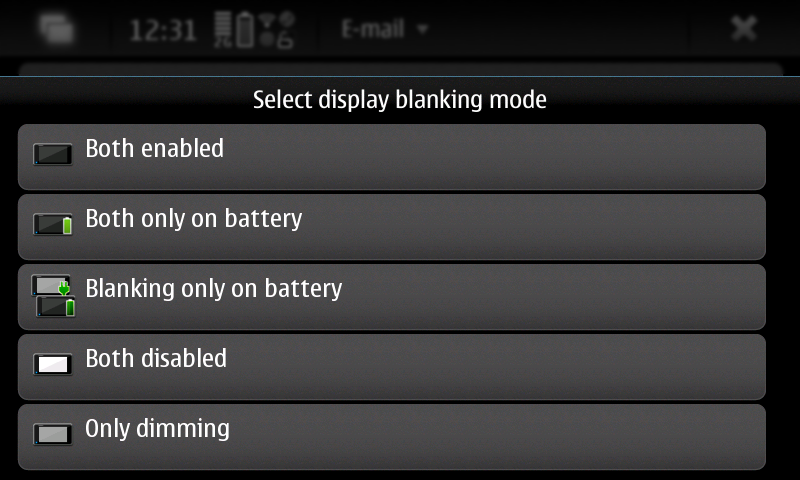
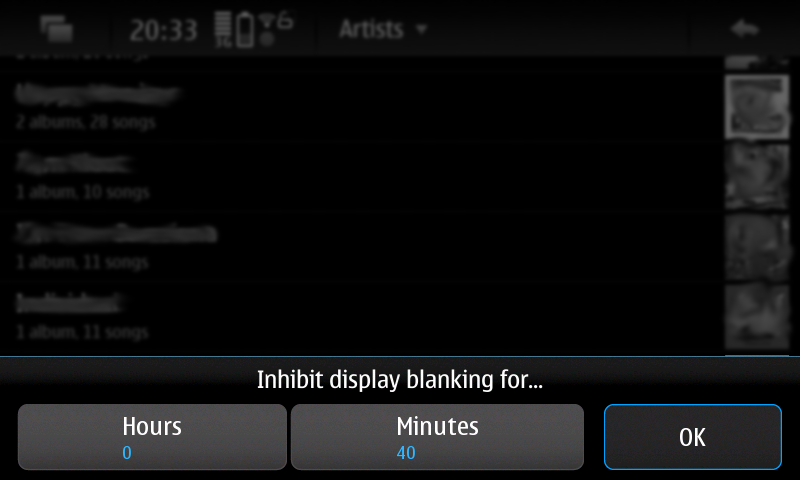
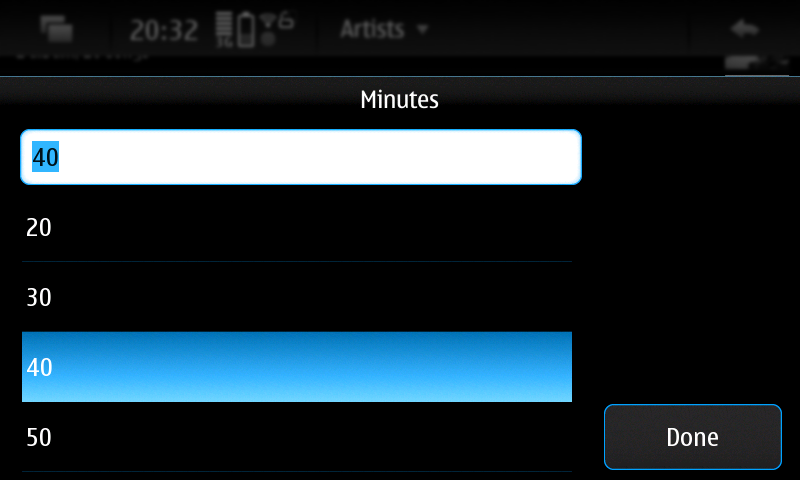
You can download this 0.5 pre-release (binary package and sources) from here: https://llucax.com.nyud.net/proj/sadba/files/0.5/
You can also get the source from the git repository: https://git.llucax.com/w/software/sadba.git
Please feel free to leave your comments and suggestions here or in the Maemo Talk Thread..
Release: Status Area Display Blanking Applet 0.4 for Maemo
by Leandro Lucarella on 2012- 07- 27 18:12 (updated on 2012- 07- 27 18:12)- with 0 comment(s)
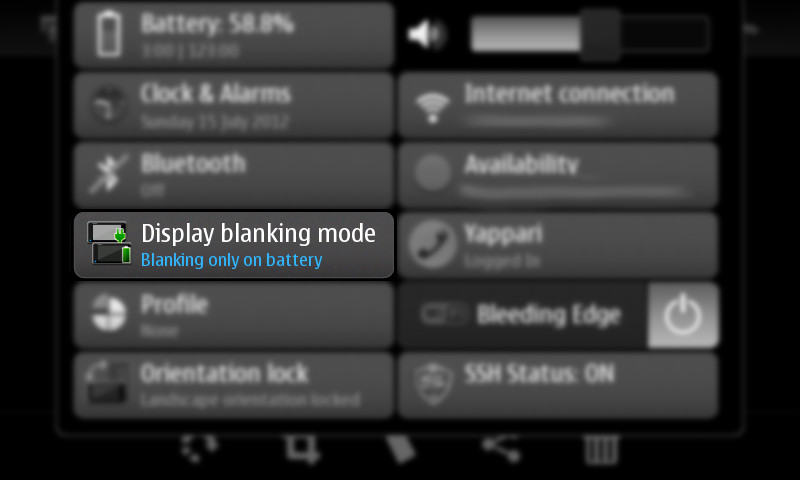
New pre-release of my first Maemo application: The Status Area Display Blanking Applet. Now you inhibit display blanking without changing the display blanking mode. The GUI is a little rough compared with the previous version but it works. :)
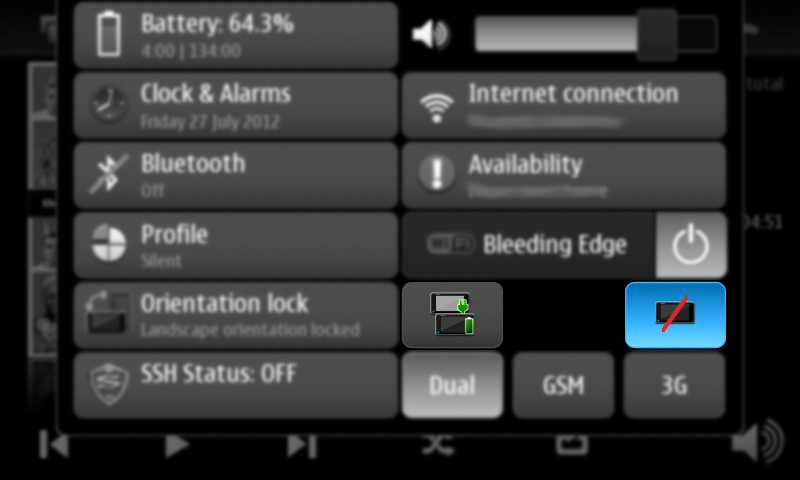
You can download this 0.4 pre-release (binary package and sources) from here: https://llucax.com.nyud.net/proj/sadba/files/0.4/
You can also get the source from the git repository: https://git.llucax.com/w/software/sadba.git
Please feel free to leave your comments and suggestions here or in the Maemo Talk Thread..
Release: Status Area Display Blanking Applet 0.3 for Maemo
by Leandro Lucarella on 2012- 07- 26 10:51 (updated on 2012- 07- 27 18:13)- with 0 comment(s)
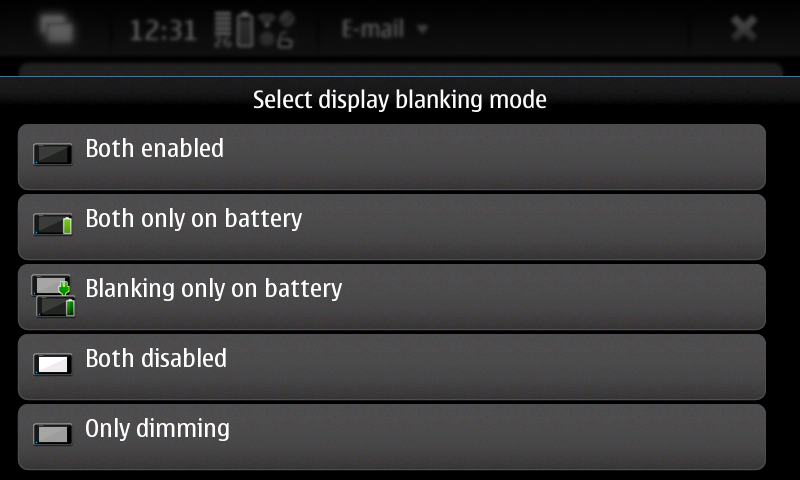
New pre-release of my first Maemo application: The Status Area Display Blanking Applet. Now you can pick whatever blanking mode you want instead of blindly cycling through all available modes, as it was in the previous version.
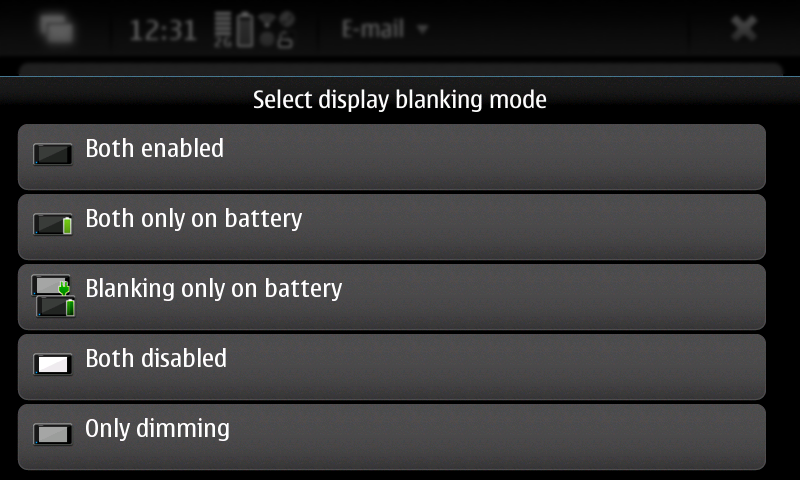
You can download this 0.3 pre-release (binary package and sources) from here: https://llucax.com.nyud.net/proj/sadba/files/0.3/
You can also get the source from the git repository: https://git.llucax.com/w/software/sadba.git
Please feel free to leave your comments and suggestions here or in the Maemo Talk Thread..
Release: Status Area Display Blanking Applet 0.2 for Maemo
by Leandro Lucarella on 2012- 07- 23 09:56 (updated on 2012- 07- 23 09:56)- with 0 comment(s)
Second pre-release of my first Maemo application: The Status Area Display Blanking Applet. No big changes since the last release just code cleanup and a bugfix or new features (depends on how you see it). Now the applet monitors changes on the current configuration, so if you change the display blanking mode from settings (or by any other means), it will be updated in the applet too.
You can download this 0.2 pre-release (binary package and sources) from here: https://llucax.com.nyud.net/proj/sadba/files/0.2/
You can also get the source from the git repository: https://git.llucax.com/w/software/sadba.git
Please feel free to leave your comments and suggestions here or in the Maemo Talk Thread..
Release: Status Area Display Blanking Applet 0.1 for Maemo
by Leandro Lucarella on 2012- 07- 15 20:09 (updated on 2012- 07- 15 20:09)- with 0 comment(s)
Hi, I just wanted to announce the pre-release of my first Maemo "application". The Status Area Display Blanking Applet let you easily change the display blanking mode right from the status menu, without having to go through the settings.
This is specially useful if you have a short blanking time when you use applications that you want to look at for a long time without interacting with the phone and don't inhibit display blanking by themselves (for example a web browser, image viewer or some GPS applications).
You can download this 0.1 pre-release (binary package and sources) from here: https://llucax.com.nyud.net/proj/sadba/files/0.1/
You can also get the source from the git repository: https://git.llucax.com/w/software/sadba.git
Here are some screenshots (the application is highlighted so you can spot it more easily :) ):
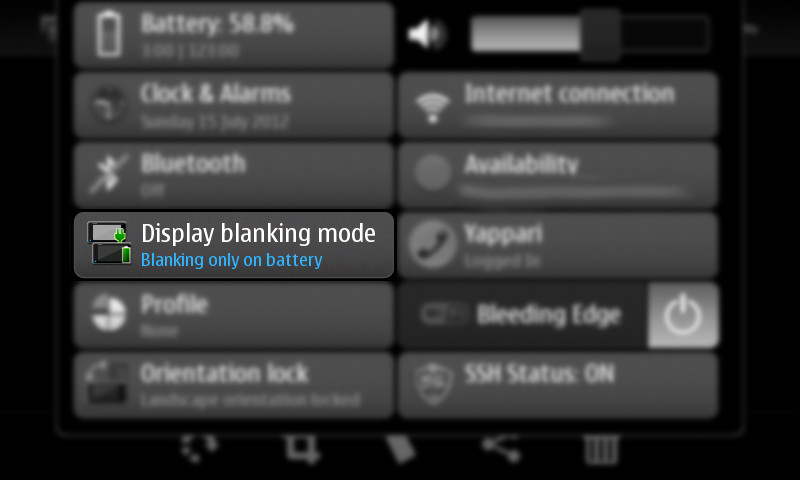

Please feel free to leave your comments and suggestions.
I'll upload the package to extras-devel when I have some time to learn the procedure.
Save Peter Sundes from jail
by Leandro Lucarella on 2012- 07- 14 20:06 (updated on 2012- 07- 14 20:06)- with 0 comment(s)

So, Peter Sundes from The Pirate Bay has been convicted to 1 year prison and 11 million euro. He lost the appeal too, so now he is looking for a last resort, a plea for pardon, a procedure where you can get a judicial sentencing undone by the political administration in exceptional circumstances.
The plea for pardon is not serious in the sense that he is not really doing so, he is denouncing an extremely corrupt and absurd trial. You can read the plea and find out, is long but really interesting how the trial makes no sense (besides what's your stand on file sharing, copyright, etc.).
If you believe the trial was unfair, you can sign this petition, it will probably be completely ignored, but hey, it only takes 2 seconds, worth trying.
Release: Mutt with NNTP Debian package 1.5.21-5nntp3
by Leandro Lucarella on 2012- 07- 05 19:59 (updated on 2012- 07- 05 19:59)- with 0 comment(s)
This is just a quick fix for yesterday's release. Now mutt-nntp depends on mutt >= 1.5.21-5. This should allow having mutt-nntp installed with the standard distribution mutt package for both Debian and Ubuntu (please report any problems).
If you have Ubuntu 12.04 (Precise) and amd64 or i386 arch, just download and install the provided packages.
For other setups, here are the quick (copy&paste) instructions:
ver=1.5.21
deb_ver=$ver-5nntp3
url=https://llucax.com.nyud.net/proj/mutt-nntp-debian/files/latest
wget $url/mutt_$deb_ver.dsc $url/mutt_$deb_ver.diff.gz \
http://ftp.de.debian.org/debian/pool/main/m/mutt/mutt_$ver.orig.tar.gz
sudo apt-get build-dep mutt
dpkg-source -x mutt_$deb_ver.dsc
cd mutt-$ver
dpkg-buildpackage -rfakeroot
# install any missing packages reported by dpkg-buildpackage and try again
cd ..
sudo dpkg -i mutt-nntp_${deb_ver}_*.deb
Now you can enjoy reading your favourite newsgroups and your favourite mailing lists via Gmane with Mutt without leaving the beauty of your packaging system. No need to thank me, I'm glad to be helpful (but if you want to make a donation, just let me know ;).
Note
You should always install the same mutt version as the one the mutt-nntp is based on (i.e. the version number without the nntpX suffix, for example if mutt-nntp version is 1.5.21-5nntp1, your mutt version should be 1.5.21-5 or 1.5.21-5ubuntu2). A newer version will satisfy the dependency too but it is not guaranteed to work (even when it probably will, specially if the upstream version is the same). You could also install the generated/provided mutt package, but that might be problematic when upgrading your distribution.
See the project page for more details.
Release: Mutt with NNTP Debian package 1.5.21-5nntp2
by Leandro Lucarella on 2012- 07- 04 17:24 (updated on 2012- 07- 04 17:24)- with 0 comment(s)
A new version of Mutt with NNTP support is available. This version only moves Mutt with NNTP support to a separate package in the hopes of having a smoother interaction with the distribution packages (avoiding automatic updates with less hassle). Now a new mutt-nntp package is generated.
If you have Ubuntu 12.04 (Precise) and amd64 or i386 arch, just download and install the provided packages.
For other setups, here are the quick (copy&paste) instructions:
ver=1.5.21
deb_ver=$ver-5nntp2
url=https://llucax.com.nyud.net/proj/mutt-nntp-debian/files/latest
wget $url/mutt_$deb_ver.dsc $url/mutt_$deb_ver.diff.gz \
http://ftp.de.debian.org/debian/pool/main/m/mutt/mutt_$ver.orig.tar.gz
sudo apt-get build-dep mutt
dpkg-source -x mutt_$deb_ver.dsc
cd mutt-$ver
dpkg-buildpackage -rfakeroot
# install any missing packages reported by dpkg-buildpackage and try again
cd ..
sudo dpkg -i mutt-nntp_${deb_ver}_*.deb
Now you can enjoy reading your favourite newsgroups and your favourite mailing lists via Gmane with Mutt without leaving the beauty of your packaging system. No need to thank me, I'm glad to be helpful (but if you want to make a donation, just let me know ;).
Note
You should always install the same mutt version as the one the mutt-nntp is based on (i.e. the version number without the nntpX suffix, for example if mutt-nntp version is 1.5.21-5nntp1, your mutt version should be 1.5.21-5). I'm not forcing that in the dependencies because in general it shouldn't be a big issue using an older version. You could also install the generated/provided mutt package, but that might be problematic when upgrading your distribution.
See the project page for more details.
The Shins @ Huxley's Neue Welt (2012-03-28)
by Leandro Lucarella on 2012- 07- 03 11:01 (updated on 2012- 07- 03 11:01)- with 0 comment(s)
-01.jpg)
The Shins @ Huxley's Neue Welt (2012-03-28) (1)
-02.jpg)
The Shins @ Huxley's Neue Welt (2012-03-28) (2)
-03.jpg)
The Shins @ Huxley's Neue Welt (2012-03-28) (3)
-04.jpg)
The Shins @ Huxley's Neue Welt (2012-03-28) (4)
-05.jpg)
The Shins @ Huxley's Neue Welt (2012-03-28) (5)
-06.jpg)
The Shins @ Huxley's Neue Welt (2012-03-28) (6)
Querying N900 address book
by Leandro Lucarella on 2012- 07- 02 20:49 (updated on 2012- 07- 02 20:49)- with 0 comment(s)
Since there is not a lot of information on how to hack Maemo's address book to find some contacts with a mobile phone number, I'll share my findings.
Since setting up an environment to cross-compile for ARM is a big hassle, I decided to write this small test program in Python, (ab)using the wonderful ctypes module to avoid compiling at all.
Here is a very small script to use the (sadly proprietary) OSSO Addressbook library:
# This function get all the names in the address book with mobile phone numbers
# and print them. The code is Python but is as similar as C as possible.
def get_all_mobiles():
osso_ctx = osso_initialize("test_abook", "0.1", FALSE)
osso_abook_init(argc, argv, hash(osso_ctx))
roster = osso_abook_aggregator_get_default(NULL)
osso_abook_waitable_run(roster, g_main_context_default(), NULL)
contacts = osso_abook_aggregator_list_master_contacts(roster)
for contact in glist(contacts):
name = osso_abook_contact_get_display_name(contact)
# Somehow hackish way to get the EVC_TEL attributes
field = e_contact_field_id("mobile-phone")
attrs = e_contact_get_attributes(contact, field)
mobiles = []
for attr in glist(attrs):
types = e_vcard_attribute_get_param(attr, "TYPE")
for t in glist(types):
type = ctypes.c_char_p(t).value
# Remove this condition to get all phone numbers
# (not just mobile phones)
if type == "CELL":
mobiles.append(e_vcard_attribute_get_value(attr))
if mobiles:
print name, mobiles
# Python
import sys
import ctypes
# be sure to import gtk before calling osso_abook_init()
import gtk
import osso
osso_initialize = osso.Context
# Dynamic libraries bindings
glib = ctypes.CDLL('libglib-2.0.so.0')
g_main_context_default = glib.g_main_context_default
def glist(addr):
class _GList(ctypes.Structure):
_fields_ = [('data', ctypes.c_void_p),
('next', ctypes.c_void_p)]
l = addr
while l:
l = _GList.from_address(l)
yield l.data
l = l.next
osso_abook = ctypes.CDLL('libosso-abook-1.0.so.0')
osso_abook_init = osso_abook.osso_abook_init
osso_abook_aggregator_get_default = osso_abook.osso_abook_aggregator_get_default
osso_abook_waitable_run = osso_abook.osso_abook_waitable_run
osso_abook_aggregator_list_master_contacts = osso_abook.osso_abook_aggregator_list_master_contacts
osso_abook_contact_get_display_name = osso_abook.osso_abook_contact_get_display_name
osso_abook_contact_get_display_name.restype = ctypes.c_char_p
ebook = ctypes.CDLL('libebook-1.2.so.5')
e_contact_field_id = ebook.e_contact_field_id
e_contact_get_attributes = ebook.e_contact_get_attributes
e_vcard_attribute_get_value = ebook.e_vcard_attribute_get_value
e_vcard_attribute_get_value.restype = ctypes.c_char_p
e_vcard_attribute_get_param = ebook.e_vcard_attribute_get_param
# argc/argv adaption
argv_type = ctypes.c_char_p * len(sys.argv)
argv = ctypes.byref(argv_type(*sys.argv))
argc = ctypes.byref(ctypes.c_int(len(sys.argv)))
# C-ish aliases
NULL = None
FALSE = False
# Run the test
get_all_mobiles()
Here are some useful links I used as reference:
- http://wiki.maemo.org/PyMaemo/Accessing_APIs_without_Python_bindings
- http://wiki.maemo.org/Documentation/Maemo_5_Developer_Guide/Using_Generic_Platform_Components/Using_Address_Book_API
- http://maemo.org/api_refs/5.0/5.0-final/libebook/
- http://maemo.org/api_refs/5.0/5.0-final/libosso-abook/
- https://garage.maemo.org/plugins/scmsvn/viewcvs.php/releases/evolution-data-server/1.4.2.1-20091104/addressbook/libebook-dbus/?root=eds
- http://www.developer.nokia.com/Community/Discussion/showthread.php?200914-How-to-print-all-contact-names-in-N900-addressbook-Please-Help
The Pirate Cohelo
by Leandro Lucarella on 2012- 01- 30 20:34 (updated on 2012- 01- 30 20:34)- with 0 comment(s)
Nice post by Paulo Coelho promoting the piracy of his own books via The Pirate Bay (whom reciprocally returns the favor).

The Pirate Bay starts today a new and interesting system to promote arts.
Do you have a band? Are you an aspiring movie producer? A comedian? A cartoon artist?
They will replace the front page logo with a link to your work.
As soon as I learned about it, I decided to participate. Several of my books are there, and as I said in a previous post, My thoughts on SOPA, the physical sales of my books are growing since my readers post them in P2P sites.
Welcome to download my books for free and, if you enjoy them, buy a hard copy – the way we have to tell to the industry that greed leads to nowhere.
Love
The Pirate Coelho
Go, search, download, read and if you like them, buy or show your appreciation in another way.
It's finally here
by Leandro Lucarella on 2012- 01- 16 08:30 (updated on 2012- 01- 16 08:30)- with 0 comment(s)

A little snow in Berlin
More adventures with the N900
by Leandro Lucarella on 2011- 12- 18 19:30 (updated on 2011- 12- 18 19:30)- with 0 comment(s)
OK, after I recovered my phone without needing to reflash once, I was even much closer to do it again because of a new problem.
After missing an appointment and arriving at work about 3 hours late, I realized my phone stopped reproducing sound and vibrating when an alarm was fired. At first I thought I put the alarm incorrectly but then I verified that the alarm was not working. I still got a popup with the alarm message, but no sound or vibration.
So... Time to debug the problem. After searching a lot, I couldn't find anybody with my same problem, I found similar, but not the same, so I decided to report a bug. I got a very fast but useless response. Great!
Making long story short, I finally found some IRC channels and mailing lists where I could find a more opensourceish support that the one provided in the forums and bugzilla. So I'm happy I finally found a place where you can talk to actual developers.
I commented my problem and just after a very trivial but extremely useful suggestion (installing syslogd), I could trace the origin or the problem and fix it (I just love you strace!).
I also had another problem, suddenly the skype calls stopped working. Again the syslog helped a lot. Unfortunately I didn't save the exact syslog error message, but it was something like:
GStreamer - Could not convert static caps "!`phmcadion/x-rtp, media=(string)video, payload=(int)[ 96, 127 ], clock-rate=(int)[ 1, 2147483647 ], encoding-name=(string)MP4V-ES"
As the MIME TYPE looked like garbage, I just grep(1)ed the filesystem searching for that string, and I found some binary file at /home/user/.gstreamer-0.10/registry.arm.bin. I backed up the file, remove it, and everything started working again (the file was recreated but with a very different content).
I have no idea how the symlink or the gstreamer file got broken, except maybe because of the unexpected reboot because of the broken batterypatch, but still, is really strange.
Anyway... Lessons learned:
- Maemo (Nokia) bugzilla is useless for getting help
- Install syslogd to debug Nokia N900 problems
- The maemo developers mailing list is your friend
Conclusion: Reflash my ass!
How to rescue your Nokia N900 without reflashing
by Leandro Lucarella on 2011- 12- 11 16:40 (updated on 2011- 12- 11 16:40)- with 0 comment(s)
I bought a Nokia N900 recently, a great toy if you like to have a phone with a Linux distribution that uses dpkg as package manager :)
Of course you can use it as an end user, and never find out, but as the geek I am, I had to hack it, and use the devel package repositories. Of course, with that comes the problems (and the fun! :D).
The last update of the batterypatch package came with a weird feature. The device rebooted itself each time it starts, leaving it in a restart loop that rendered the device unusable.
Searching for valuable information was not easy (thanks forums! You SUCK at organizing information... I miss mailing lists).
Anyway, I hope I can save some work to someone if you get in a similar situation, so you don't have to waste ours searching the Maemo Forums.
First you will need a tool to flash the phone (it can do other things besides flashing it, I used the maemo_flasher-3.5_2.5.2.2_i386.deb file). You can also check some instructions on how to load a (very) basic rescue image (from Meego). The good thing is this image is an initrd that's loaded in MEMORY, so you don't loose anything if you tried, the device goes to it's previous state (broken in my case :P) after a reboot.
What this image can do is put the device in USB mass storage mode (the embedded MMC -eMMC- and the external MMC). I've done this to backup my eMMC data, which holds the MyDocs vfat partition and the 2 GiB ext3 partition used to install optional software. You can also put the device in USB networking mode, you can get a shell console (and reboot/power off the device), but I found that pretty useless (because you don't have any useful tools, the backlit is not turned on, so is really hard to see anything, and because the kayboard doesn't have the function key mapped, so you can't even write a "/").
The bad thing about this image, is you can't access to the root filesystem (wich is stored in another NAND 256MiB memory). I wanted to access it for 2 reasons. First, I wanted to edit some files that the batterypatch program created to see if that fixed the rebooting problem. And if now, I wanted to make a backup of the rootfs so I didn't loose most of my customizations and installed software.
I first found that a way to access the rootfs was to install Meego in a uSD memory, but for that I needed a 4GiB uSD. Also it looked like too much work, it has to be something battery and easier to just mount the rootfs and play around.
And I finally found it. It was the hardest thing to found, that's why I not only passing you the original link, I'm also hosting my own copy because I have the feeling it can disappear any time! :P
This image let's you do all the same the other image can, but it turns on the backlit, it has better support for the keyboard (you can type a "/") and it can mount the UBI root filesystem. Even more, it comes with a telnet daemon, so you can even do the rescue work remotely using USB networking ;)
You can see the instructions for some of the tasks, but here is how I did to be able to log in using telnet, which is not documented elsewhere that I know off. Once you have your image loaded:
You have to activate the USB networking in the device: /rescueOS/usbnetworking-enable.sh
Configure your host PC to assign an IP to usb0: sudo ip a add 192.168.2.14/24 dev usb0 && sudo ip link set usb0 up
Start the telnet daemon in the device: telnetd
I couldn't find out the root password, and since the initrd root filesystem is read-only, so I did this to change the root password:
cp -a /etc /run/ mount --bind /run/etc /etc passwd
Now type the new root password.
That's it, log in via telnet from the host PC: telnet 192.168.2.15 and have fun!
With this I just could edit the broken files and saved the device without even needing to reflash it, but if you're not so lucky, you can just backup the root filesystem and reflash using this instructions (I didn't tested them, but seems pretty official).
Now I should probably have to try the recovery-boot package, if it works well it might be even easier to rescue the phone using that ;)
GML
by Leandro Lucarella on 2011- 07- 23 22:48 (updated on 2011- 07- 23 22:48)- with 0 comment(s)
Graffiti Markup Language is...
An universal, XML based, open file format designed to store graffiti motion data (x and y coordinates and time). The format is designed to maximize readability and ease of implementation, even for hobbyist programmers, artists and graffiti writers. Popular applications currently implementing GML include Graffiti Analysis and EyeWriter. Beyond storing data, a main goal of GML is to spark interest surrounding the importance (and fun) of open data and introduce open source collaborations to new communities. GML is intended to be a simple bridge between ink and code, promoting collaborations between graffiti writers and hackers.
An probably the funniest part:
GML is today’s new digital standard for tomorrow’s vandals.
The Black Keys - Howlin' For You
by Leandro Lucarella on 2011- 07- 22 23:34 (updated on 2011- 07- 22 23:34)- with 0 comment(s)
Interesting music video by The Black Keys shaped as a movie trailer.
Tilt
by Leandro Lucarella on 2011- 07- 20 19:35 (updated on 2011- 07- 20 19:35)- with 0 comment(s)
Tilt is a Firefox extension that lets you visualize any web page DOM tree in 3D.
Via Mozilla hacks.
Futurama just keeps getting better and better
by Leandro Lucarella on 2011- 07- 10 21:04 (updated on 2011- 07- 10 21:04)- with 0 comment(s)
Fragment of Law and Oracle episode (S06E17/6ACV16):
10 delirious songs with strange vocals
by Leandro Lucarella on 2011- 07- 06 03:38 (updated on 2011- 07- 06 03:38)- with 0 comment(s)
10 canciones delirantes con voces extrañas
[Grooveshark murió y con él esta lista]
Harvie Krumpet
by Leandro Lucarella on 2011- 07- 04 14:53 (updated on 2011- 07- 04 14:53)- with 0 comment(s)
Harvey Krumpet (es) by Adam Elliot
(or you can see it in 1 part only in English without Spanish subtitles here)
There, I fixed it!
by Leandro Lucarella on 2011- 07- 04 02:17 (updated on 2011- 07- 04 02:17)- with 0 comment(s)
My cheap bike front light is not very water resistant...




WikiLeaks banking blockage advertisement
by Leandro Lucarella on 2011- 06- 29 20:50 (updated on 2011- 06- 29 20:50)- with 0 comment(s)
Two dogs dining in a busy restaurant
by Leandro Lucarella on 2011- 06- 24 15:49 (updated on 2011- 06- 24 15:49)- with 0 comment(s)
Berlin
by Leandro Lucarella on 2011- 06- 16 16:19 (updated on 2011- 06- 16 16:19)- with 0 comment(s)

Babasónicos - Dopádromo
by Leandro Lucarella on 2011- 06- 13 02:02 (updated on 2011- 06- 13 02:02)- with 0 comment(s)
I was just listening to Dopádromo from Babasónicos and thinking: what a good album!
The Architecture of Open Source Applications
by Leandro Lucarella on 2011- 06- 07 00:56 (updated on 2011- 06- 07 00:56)- with 0 comment(s)
The Architecture of Open Source Applications
Architects look at thousands of buildings during their training, and study critiques of those buildings written by masters. In contrast, most software developers only ever get to know a handful of large programs well—usually programs they wrote themselves—and never study the great programs of history. As a result, they repeat one another's mistakes rather than building on one another's successes.
This book's goal is to change that. In it, the authors of twenty-five open source applications explain how their software is structured, and why. What are each program's major components? How do they interact? And what did their builders learn during their development? In answering these questions, the contributors to this book provide unique insights into how they think.
If you are a junior developer, and want to learn how your more experienced colleagues think, this book is the place to start. If you are an intermediate or senior developer, and want to see how your peers have solved hard design problems, this book can help you too.
I hope I can find the time to read this (at least some chapters).
It's ALIVE!
by Leandro Lucarella on 2011- 06- 05 00:45 (updated on 2011- 06- 05 00:45)- with 2 comment(s)

Thank you Garrett, you saved my bike! =D
Today I got, after looking for one for several months, my derailleur hanger!
Raleigh (both Argentina and USA) were completely unhelpful, so I got to find it somewhere else, and finally found one at bicyclederailleurhangers.com (mine is #22 =).
I hope tomorrow I can finally fix my bike.
/me happy!
Beastie Boys - Fight For Your Right (Revisited)
by Leandro Lucarella on 2011- 05- 28 22:06 (updated on 2011- 05- 28 22:06)- with 0 comment(s)
Lime total.
Never leave your e-mail to Fujitsu
by Leandro Lucarella on 2011- 05- 25 17:26 (updated on 2011- 05- 25 17:26)- with 0 comment(s)
Fujitsu I hate you. I usually use an alias when putting my e-mail in some company form, using the feature most MTAs have to use something like myrealuser-<somealias>@example.com.
Lately I've been receiving tons of spam from luca-fujitsu@... and the kind of spam my Bogofilter have a hard time to swallow, so it's becoming really annoying. I'll just see how to make luca-fujitsu@... and invalid e-mail and reject all mails delivered to it.
Fuck off Fujitsu!
Release: Mutt with NNTP Debian package 1.5.21-5nntp1
by Leandro Lucarella on 2011- 05- 24 19:59 (updated on 2011- 05- 24 19:59)- with 0 comment(s)
I've updated my Mutt Debian package with the NNTP patch to the latest Debian Mutt package.
This release is to bring just the regular bugfixing round from Debian.
If you have Debian testing/unstable and amd64 or i386 arch, just download and install the provided packages.
For other setups, here are the quick (copy&paste) instructions:
ver=1.5.21
deb_ver=$ver-5nntp1
url=https://llucax.com.nyud.net/proj/mutt-nntp-debian/files/latest
wget $url/mutt_$deb_ver.dsc $url/mutt_$deb_ver.diff.gz \
http://ftp.de.debian.org/debian/pool/main/m/mutt/mutt_$ver.orig.tar.gz
sudo apt-get build-dep mutt
dpkg-source -x mutt_$deb_ver.dsc
cd mutt-$ver
dpkg-buildpackage -rfakeroot
# install any missing packages reported by dpkg-buildpackage and try again
cd ..
sudo dpkg -i mutt_${deb_ver}_*.deb mutt-patched_${deb_ver}_*.deb
See the project page for more details.
10 songs of...
by Leandro Lucarella on 2011- 05- 23 22:40 (updated on 2011- 05- 23 22:40)- with 0 comment(s)
New section, let's see for how long I can keep this up =)
The idea is to make a compilation of 10 songs of (somehow) unknown music (and/or bands) picking up a theme. At first I'll try to pick only local (Argentinian) bands, but maybe in the future I can go more global.
This time, the theme is songs that have, in one way or another, some native rhythm.
[Groveshark died, and with it this list]
C++0x -> C++11
by Leandro Lucarella on 2011- 05- 21 04:33 (updated on 2011- 05- 21 04:33)- with 0 comment(s)
Quoting again =P (from Wikipedia):
In their March 2011 meeting, the ISO/IEC JTC1/SC22/WG21 C++ Standards Committee voted C++0x (N3290) to Final Draft International Standard (FDIS) status. This means that this final draft, dated 11 April 2011, is ready for review and approval by the ISO; the final specification is expected to be published sometime in mid-2011. To be able to finish closer to schedule, the Committee decided to focus its efforts on the solutions introduced up until 2006 and ignore newer proposals.
I still don't know if this is good or bad news. Probably both.
Upstream Tracker
by Leandro Lucarella on 2011- 05- 21 03:59 (updated on 2011- 05- 21 03:59)- with 0 comment(s)
I'm too lazy lately, so I will just quote the Upstream Tracker site:
Backward binary compatibility testing for C and C++ shared libraries on x86
This service is aimed on analyzing of the C and C++ libraries evolution. It is looking for new releases of various libraries and checking them for backward binary compatibility. The web-service is generally intended for operating system maintainers to help in updating libraries and for software developers interested in ensuring backward binary compatibility of the API.
A really nice service. They are monitoring 286 libraries (at the time of writing) and you can add more for free.
Bitcoin: p2p virtual currency
by Leandro Lucarella on 2011- 05- 17 00:04 (updated on 2011- 05- 17 00:04)- with 1 comment(s)
Bitcoin is one of the most subversive ideas I ever read, it's as scary as exciting in how it could change the world economy dynamics if it works.
Bitcoin is (quoting WeUseCoins.com):
- Decentralized
- Bitcoin is the first digital currency that is completely distributed. The network is made up of users like yourself so no bank or payment processor is required between you and whoever you're trading with. This decentralization is the basis for Bitcoin's security and freedom.
- Worldwide
- Your Bitcoins can be accessed from anywhere with an Internet connection. Anybody can start mining, buying, selling or accepting Bitcoins regardless of their location.
- No small print
If you have Bitcoins, you can send them to anyone else with a Bitcoin address. There are no limits, no special rules to follow or forms to fill out.
More complex types of transactions can be built on top of Bitcoin as well, but sometimes you just want to send money from A to B without worrying about limits and policies.
- Very low fees
- Currently you can send Bitcoin transactions for free. However, a fee on the order of 1 bitcent will eventually be necessary for your transaction to be processed more quickly. Miners compete on fees, which ensures that they will always stay low in the long run. More on transaction fees (Bitcoin Wiki).
- Own your money!
You don't have to be a criminal to wake up one day and find your account has been frozen. Rules vary from place to place, but in most jurisdictions accounts may be frozen by credit card collection agencies, by a spouse filing for divorce, by mistake or for terms of service violations.
In contrast, Bitcoins are like cash - seizing them requires access to your private keys, which could be placed on a USB stick, thereby enjoying the full legal and practical protections of physical property.
Here is a video, if you are too lazy to read:
If you want some more detailed information, there is a paper describing the technical side of the project (which I read and didn't fully understand, to be honest).
You have to add bitcoin mining to the equation. Which is not very well explained there. Bitcoin mining is a business, just like gold mining is. You need resources to do it, and if you don't do it efficiently, you'll loose money (the electricity and hardware cost will supersede what you're earning).
Quoting again:
The mining difficulty expresses how much harder the current block is to generate compared to the first block. So a difficulty of 70000 means to generate the current block you have to do 70000 times more work than Satoshi had to do generating the first block. Though be fair though, back then mining was a lot slower and less optimized.
The difficulty changes every 2016 blocks. The network tries to change it such that 2016 blocks at the current global network processing power take about 14 days. That's why, when the network power rises, the difficulty rises as well.
Bad Cover Version
by Leandro Lucarella on 2011- 05- 12 02:41 (updated on 2011- 05- 12 02:41)- with 0 comment(s)
Canary sky
by Leandro Lucarella on 2011- 05- 05 17:57 (updated on 2011- 05- 05 17:57)- with 0 comment(s)
How to use your fridge as a whiteboard
by Leandro Lucarella on 2011- 05- 05 03:09 (updated on 2011- 05- 05 03:09)- with 0 comment(s)
Just a stupid idea...

How to use your fridge as a whiteboard

First, get a fridge, then, get a whiteboard marker

Find a hidden spot and write something, then try to erase it immediately

If it didn't work, get another fridge

Otherwise, write again in the hidden spot, but don't erase it yet, wait a couple of hours, then erase it

If it didn't work, get another fridge

If it worked, congratulations, your fridge can be used as a whiteboard

Write on it with the marker, as I am doing (doodle)

Optionally, you can buy some cool magnets (like these)

Glue a couple to your marker (add a protection so they don't scratch the fridge (if you care enough)

So you can leave the marker right on the fridge, ready to be used

Enjoy your fridge, bye =)
Alternate reality
by Leandro Lucarella on 2011- 04- 15 13:19 (updated on 2011- 04- 15 13:19)- with 0 comment(s)
I always loved Studio Ghibli's movies, and mostly because I found them so imaginative, I love the fantasy worlds they created.
But then, I saw this video, and it made me think that maybe, Sen to Chihiro (Spirited Away) is really a documentary...
RSAnimate
by Leandro Lucarella on 2011- 04- 14 13:13 (updated on 2011- 04- 14 13:13)- with 0 comment(s)
Release: Mutt with NNTP Debian package 1.5.21-4nntp1
by Leandro Lucarella on 2011- 04- 13 00:20 (updated on 2011- 04- 13 00:20)- with 0 comment(s)
I've updated my Mutt Debian package with the NNTP patch to the latest Debian Mutt package.
If you have downloaded the previous version, you probably noted an extremely annoying bug, which is fixed in this new package, so I'm sure you want to upgrade =)
If you have Debian testing/unstable and amd64 or i386 arch, just download and install the provided packages.
For other setups, here are the quick (copy&paste) instructions:
ver=1.5.21
deb_ver=$ver-4nntp1
url=https://llucax.com.nyud.net/proj/mutt-nntp-debian/files/latest
wget $url/mutt_$deb_ver.dsc $url/mutt_$deb_ver.diff.gz \
http://ftp.de.debian.org/debian/pool/main/m/mutt/mutt_$ver.orig.tar.gz
sudo apt-get build-dep mutt
dpkg-source -x mutt_$deb_ver.dsc
cd mutt-$ver
dpkg-buildpackage -rfakeroot
# install any missing packages reported by dpkg-buildpackage and try again
cd ..
sudo dpkg -i mutt_${deb_ver}_*.deb mutt-patched_${deb_ver}_*.deb
See the project page for more details.
First Orbit
by Leandro Lucarella on 2011- 04- 12 13:27 (updated on 2011- 04- 12 13:27)- with 0 comment(s)
Today, in the lands of YouTube, is First Orbit, the movie...
A free movie for you to download and share, created to celebrate the first 50 years of human space flight.
A real time recreation of Yuri Gagarin's pioneering first orbit, shot entirely in space from on board the International Space Station. The film combines this new footage with Gagarin's original mission audio and a new musical score by composer Philip Sheppard.
What I like the most is, it's the Russian side of the coin, and when it come to the space race, we usually only see the USA side of it (as with many many other historical events).
Here is the entire movie:
Numbeo
by Leandro Lucarella on 2011- 04- 10 22:11 (updated on 2011- 04- 10 22:11)- with 0 comment(s)
According to Numbeo website:
Numbeo is the largest free Internet database about cost of living worldwide!
Numbeo is the largest free Internet database about worldwide housing indicators!
It's a really nice site to see how the prices compare between countries, and other type of indicators for travelers or curious =)
El fitito de Cousteau
by Leandro Lucarella on 2011- 04- 10 03:45 (updated on 2011- 04- 10 03:45)- with 0 comment(s)

El fitito de Cousteau
The Flaming Lips @ GEBA (2011-04-05)
by Leandro Lucarella on 2011- 04- 09 22:01 (updated on 2011- 04- 12 15:51)- with 0 comment(s)
Algunas notas (English speakers ignore this, is not important):
- GEBA (o mejor dicho los maquinistas de TBA) apesta; el tren no molesta tanto pero los pelotudos de los maquinistas se la pasaba tocando bocina en busca de 15 segundos de (mala) fama.
- Que exista campo y campo VIP apesta. Odio, pero ODIO ODIO al que se le ocurrió esa nefasta idea (cánticos del estilo "¡Sacá la valla la putá que lo parió!" no faltaron). Sí, a vos geniecillo del marketing desconocido, te maldigo y espero que te agarres alguna enfermedad fea fea.
- El show fue una fiesta.
-01.jpg)
The Flaming Lips @ GEBA (2011-04-05) (1)
-02.jpg)
The Flaming Lips @ GEBA (2011-04-05) (2)
-03.jpg)
The Flaming Lips @ GEBA (2011-04-05) (3)
-04.jpg)
The Flaming Lips @ GEBA (2011-04-05) (4)
-05.jpg)
The Flaming Lips @ GEBA (2011-04-05) (5)
-06.jpg)
The Flaming Lips @ GEBA (2011-04-05) (6)
-07.jpg)
The Flaming Lips @ GEBA (2011-04-05) (7)
-08.jpg)
The Flaming Lips @ GEBA (2011-04-05) (8)
-09.jpg)
The Flaming Lips @ GEBA (2011-04-05) (9)
-10.jpg)
The Flaming Lips @ GEBA (2011-04-05) (10)
Massacre @ GEBA (2011-04-05)
by Leandro Lucarella on 2011- 04- 09 21:51 (updated on 2011- 04- 09 21:51)- with 0 comment(s)
Massacre obrando de soporte de los Flaming Lips.
-01.jpg)
Massacre @ GEBA (2011-04-05) (1)
-02.jpg)
Massacre @ GEBA (2011-04-05) (2)
Driver runs into dozens of cyclists in Porto Alegre's Critical Mass
by Leandro Lucarella on 2011- 04- 09 00:42 (updated on 2011- 04- 09 00:42)- with 0 comment(s)
There are no words to describe this...
This happened about a month ago in a Critical Mass in Porto Alegre, Brazil.
Bicicletería Mc. Giver
by Leandro Lucarella on 2011- 04- 03 00:03 (updated on 2011- 04- 03 00:03)- with 0 comment(s)

Bicicletería Mc. Giver
Jane's Addiction @ Anfiteatro de Puerto Madero
by Leandro Lucarella on 2011- 04- 02 18:36 (updated on 2011- 04- 02 18:36)- with 0 comment(s)

Escenario de apertura

El gato volador

Escenario


Dave Navarro, Perry Farrell y Stephen Perkins


Lluvia de papelitos en los bises con Stop!

Perry Farrell, Eric Avery y el culo de Stephen Perkins

El dúo dinámico


Perry Farrell, Stephen Perkins t Eric Avery

Registrando el momento
The Canterbury Distribution
by Leandro Lucarella on 2011- 04- 01 05:39 (updated on 2011- 04- 01 05:39)- with 0 comment(s)
Is The Canterbury Distribution the first big joke from April Fools's Day?
I'm sure it is =)
Flaming Lips
by Leandro Lucarella on 2011- 03- 28 22:49 (updated on 2011- 04- 01 18:24)- with 0 comment(s)
Whoa!

Update
Para los que no tienen entradas, hay un Grupón activo por unas 8 horas más que te permite comprar la entrada al 50%. FUUUUUUUUUUUUUUU!!!
Igual nunca usé el Grupón, así que ni idea de si funciona. Si alguien la compra a través de esto, me comenta como es el procedimiento?
Fandango
by Leandro Lucarella on 2011- 03- 28 22:44 (updated on 2011- 03- 28 22:44)- with 0 comment(s)

Fandango
Let England Shake
by Leandro Lucarella on 2011- 03- 26 23:28 (updated on 2011- 03- 26 23:28)- with 0 comment(s)
I just want to say: WHAT AN AMAZING ALBUM
It's been a while since I listened to an album that made me want to say that, and Let England Shake by Pj Harvey did it (and I'm exactly a PJ Harvey fan). Both music and lyrics are excellent.
Also, there are videos available for almost all the songs in the album, and they are all beautiful. Here is the video for The Colour Of The Earth HD. Watch it!
Tick Tock
by Leandro Lucarella on 2011- 03- 20 15:19 (updated on 2011- 03- 20 15:19)- with 0 comment(s)
(vía albertito =P)
Sur 2011, Día 12, El Retorno
by Leandro Lucarella on 2011- 03- 19 17:16 (updated on 2011- 03- 19 17:16)- with 0 comment(s)

Habitaión del hostel El Hongo

Partida del hostel

¿Zapatillería? ¿Ropería?

El avión (cargando nafta)
How to make a broken HDD useful
by Leandro Lucarella on 2011- 03- 19 16:41 (updated on 2011- 03- 19 16:41)- with 0 comment(s)
Well, I usually only removed those nice and powerful magnets, but this is going one step further at the time of finding a use for a broken HDD...

Wander Wildner y sus Comancheros
by Leandro Lucarella on 2011- 03- 17 01:19 (updated on 2011- 03- 17 01:19)- with 0 comment(s)
Martes 15 de Marzo, Complejo Cultural (Teatro) 25 de Mayo.

Wander Wildner y sus Comancheros (1)

Wander Wildner y sus Comancheros (2)

Wander Wildner y sus Comancheros (3)

Wander Wildner y sus Comancheros (4)
Sur 2011, Día 11, La Angostura (otra vez)
by Leandro Lucarella on 2011- 03- 16 18:57 (updated on 2011- 03- 16 18:57)- with 0 comment(s)
-01.jpg)
Mirador del cerro Belvedere
En la base del cerro hay un asentamiento Mapuche que reclama las tierras, que hemos podido conocer, breve y accidentalmente, porque nos perdimos a la vuelta y tuvimos que cruzarlo para poder volver =P
-02.jpg)
Río Correntoso, visto desde el mirador del cerro Belvedere
-03.jpg)
Arroyo en la cascada Incayal
-04.jpg)
Arroyo
-05.jpg)
Mensaje de paz (amor, justicia y libertad)
-06.jpg)
Cascada Incayal cayendo al precipicio
-07.jpg)
Bajada del cerro Belvedere
-08.jpg)
Río Correntoso, visto desde el puente del camino de los 7 lagos
Dunk
by Leandro Lucarella on 2011- 03- 14 21:45 (updated on 2011- 03- 14 21:45)- with 0 comment(s)
Here is the winning dunk of the 23th Argentinian's basketball league All Stars dunk contest by DeCorey Young:
In case you didn't notice, he was wearing Messi's T-shirt =)
Sur 2011, Día 10, Pichi Traful
by Leandro Lucarella on 2011- 03- 12 00:58 (updated on 2011- 03- 12 00:58)- with 0 comment(s)

Vapor matinal (Espejo Chico)

Arroyo

Pescador

Lago Pichi Traful

Chimango

Con la cabeza en las nubes
Sur 2011, Día 9, Espejo Chico
by Leandro Lucarella on 2011- 03- 10 23:34 (updated on 2011- 03- 10 23:34)- with 0 comment(s)

Tero

Troncos

Lago Espejo Chico

Lago Espejo Chico (panorama)

Posa mariposa

Primitivo

Arroyo

Playa
Sur 2011, Día 7, Bosque de arrayanes (en bici)
by Leandro Lucarella on 2011- 03- 06 02:12 (updated on 2011- 03- 06 02:12)- with 0 comment(s)
-01.jpg)
Descanso mirando al lago
-02.jpg)
Bosque y Lago
-03.jpg)
Primeros arrayanes
-04.jpg)
¿Sabía usted como se reproduce el arrayán?
-05.jpg)
Muelles
-06.jpg)
Scott
Sur 2011, Día 6, Camino a La Angostura
by Leandro Lucarella on 2011- 03- 04 23:52 (updated on 2011- 03- 04 23:52)- with 0 comment(s)

Espejo, ruta, movimiento... y yo

Auto 1

Auto 2
Garmin FAIL
Sur 2011, Día 5, El Paraíso (Río Azul)
by Leandro Lucarella on 2011- 03- 02 22:42 (updated on 2011- 03- 02 22:42)- with 0 comment(s)
-01.jpg)
El Paraíso (Río Azul)
-02.jpg)
Río Azul
Sur 2011, Día 3, Hielo Azul
by Leandro Lucarella on 2011- 03- 01 02:29 (updated on 2011- 03- 01 02:29)- with 0 comment(s)

Refugio Hielo Azul

Nieve

Flower Power

Valle

Laguna y Glaciar Hielo Azul

Acampantes en la nieve

Laguna y Glaciar

Descanso en la Sombra

Arroyito
Sur 2011, Día 2, Rumbo al Hielo Azul
by Leandro Lucarella on 2011- 02- 24 23:06 (updated on 2011- 02- 24 23:06)- with 0 comment(s)

Máximo 1 persona

Puente colgante

Río Azul

Bosque

Mirador del Raquel

¡Es por allá!

Arroyo Teno

Tunel de deshielo

Refugio
Gecko adhesion
by Leandro Lucarella on 2011- 02- 22 22:53 (updated on 2011- 02- 22 22:53)- with 0 comment(s)
You know how Wikipedia is... One thing led to another and I ended up reading about gecko adhesion in one of its references:
How do geckos make use of the smallest of intermolecular forces to climb walls? Tiny hairs derived from the keratin in the skin on their feet create a large, compliant surface area which makes intimate contact with the substrate. One Tokay gecko (Gekko gecko) may possess several millions of these hairs, called setae. Each seta is in turn subdivided into 100-1000 smaller flattened tips, called spatulae.
Why van der Waals? Although they are the weakest type of intermolecular force, they are ubiquitous and occur between all types of surfaces. This means that the key to dry adhesion is the shape or geometry of the adhesive, rather than the chemistry. Other insects which stick by secretions (e.g. ants, beetles, flies, etc.) are much more picky about what types of surfaces they stick to. Geckos can stick to any surface, with the exception of Teflon, which was specifically engineered to prevent even van der Waals adhesion.
Even more, there is some research on synthesizing artificial gecko adhesives. Very interesting...
Sur 2011, Día 1, El Bolsón
by Leandro Lucarella on 2011- 02- 21 02:56 (updated on 2011- 02- 21 02:56)- with 0 comment(s)

GPS

Ruta

Río Azul
Pie al agua

El hombre del fuego

Arde

Pizza!
Lazy Boy
by Leandro Lucarella on 2011- 02- 20 20:13 (updated on 2011- 02- 20 20:13)- with 0 comment(s)
Lazy Boy by Les Mentettes Orchestra.
CDGC merged into Tango
by Leandro Lucarella on 2011- 01- 28 22:49 (updated on 2011- 01- 28 22:49)- with 0 comment(s)
Yai! Finally my CDGC patches has been applied to Tango [1] [2] [3]. CDGC will not be the default Tango GC for now, because it needs some real testing first (and fixing a race when using weak references). So, please, please, do try it, is as simple as compiling from the sources adding a new option to bob: -g=cdgc and then manually installing Tango.
Please, don't forget to report any bugs or problems.
Thanks!
I love this game
by Leandro Lucarella on 2011- 01- 23 15:47 (updated on 2011- 01- 23 15:47)- with 0 comment(s)
Release: Mutt with NNTP Debian package 1.5.21-2nntp1
by Leandro Lucarella on 2011- 01- 19 17:19 (updated on 2011- 01- 19 17:19)- with 0 comment(s)
I've updated my Mutt Debian package with the NNTP patch to the latest Debian Mutt package.
A couple of extra news:
- I added a new Git repository so you can download the sources via Git.
- The Debian revision is renamed to NnntpM (instead of the old NlucaM).
If you have Debian testing/unstable and amd64 or i386 arch, just download and install the provided packages.
For other setups, here are the quick (copy&paste) instructions:
ver=1.5.21
deb_ver=$ver-2nntp1
url=https://llucax.com.nyud.net/proj/mutt-nntp-debian/files/latest
wget $url/mutt_$deb_ver.dsc $url/mutt_$deb_ver.diff.gz \
http://ftp.de.debian.org/debian/pool/main/m/mutt/mutt_$ver.orig.tar.gz
sudo apt-get build-dep mutt
dpkg-source -x mutt_$deb_ver.dsc
cd mutt-$ver
dpkg-buildpackage -rfakeroot
# install any missing packages reported by dpkg-buildpackage and try again
cd ..
sudo dpkg -i mutt_${deb_ver}_*.deb mutt-patched_${deb_ver}_*.deb
See the project page for more details.
libclang
by Leandro Lucarella on 2010- 12- 24 16:45 (updated on 2010- 12- 24 16:45)- with 0 comment(s)
The 2010 LLVM Developers' Meeting was almost 2 months ago, and this time Apple employees videos are available.
I saw the libclang talk video and it was really interesting, it made me want to play with clang. I wonder if there are Python bindings to it, is so much easier to try things out using Python ;)
Project Gutenberg considers adopting RST as master format
by Leandro Lucarella on 2010- 12- 17 00:04 (updated on 2010- 12- 17 00:04)- with 0 comment(s)
Marcello Perathoner, from Project Gutenberg, has just announced that they are considering using ReStructuredText as master format. In his own words:
Project Gutenberg (PG) is a volunteer effort to digitize and make available to everybody books whose copyright has expired. We OCR the books and proofread them and make them available in a variety of formats.
PG has been evaluating RST as a master format to generate HTML, EPUB, Kindle, PDF and plain text formats.
In that course I have written some patches to RST. I now want to discuss them and maybe improve my ways. If you see fit, my patches could be added to the RST core.
It's nice to see this two lovely projects playing together :)
Engineer
by Leandro Lucarella on 2010- 12- 08 21:33 (updated on 2010- 12- 08 21:33)- with 0 comment(s)
Finally, I defended my thesis last Monday and now I'm officially (well, not really, the diploma takes about a year to be emitted) an Ingeniero en Informática (something like a Informatics Engineer). I hope I can get some free time now to polish the rough edges of the collector (fix the weakrefs for example) so it can be finally merged into Tango.
DMDFE copyright assigned to the FSF?
by Leandro Lucarella on 2010- 11- 10 23:07 (updated on 2010- 11- 10 23:07)- with 0 comment(s)
CDGC experimental branch in Druntime
by Leandro Lucarella on 2010- 11- 09 18:51 (updated on 2010- 11- 09 18:51)- with 0 comment(s)
Sean Kelly just created a new experimental branch in Druntime with CDGC as the GC for D2. The new branch is completely untested though, so only people wanting to help testing should try it out (which will be very appreciated).
CDGC Tango integration
by Leandro Lucarella on 2010- 10- 21 02:34 (updated on 2010- 10- 21 02:34)- with 0 comment(s)
Trying CDGC HOWTO
by Leandro Lucarella on 2010- 10- 10 19:28 (updated on 2010- 10- 10 19:28)- with 0 comment(s)
Here are some details on how to try CDGC, as it needs a very particular setup, specially due to DMD not having precise heap scanning integrated yet.
Here are the steps (in some kind of literate scripting, you can copy&paste to a console ;)
# You probably want to do all this mess in some subdirectory :)
mkdir cdgc-test
cd cdgc-test
# First, checkout the repositories.
git clone git://git.llucax.com/software/dgc/cdgc.git
# If you have problems with git:// URLs, try HTTP:
# git clone https://git.llucax.com/r/software/dgc/cdgc.git
svn co http://svn.dsource.org/projects/tango/tags/releases/0.99.9 tango
# DMD doesn't care much (as usual) about tags, so you have to use -r to
# checkout the 1.063 revision (you might be good with the latest revision
# too).
svn co -r613 http://svn.dsource.org/projects/dmd/branches/dmd-1.x dmd
# Now we have to do some patching, let's start with Tango (only patch 3 is
# *really* necessary, but the others won't hurt).
cd tango
for p in 0001-Fixes-to-be-able-to-parse-the-code-with-Dil.patch \
0002-Use-the-mutexattr-when-initializing-the-mutex.patch \
0003-Add-precise-heap-scanning-support.patch \
0004-Use-the-right-attributes-when-appending-to-an-empty-.patch
do
wget -O- "https://llucax.com/blog/posts/2010/10/10-trying-cdgc-howto/$p" |
patch -p1
done
cd ..
# Now let's go to DMD
cd dmd
p=0001-Create-pointer-map-bitmask-to-allow-precise-heap-sca.patch
wget -O- "https://llucax.com/blog/posts/2010/10/10-trying-cdgc-howto/$p" |
patch -p1
# Since we are in the DMD repo, let's compile it (you may want to add -jN if
# you have N CPUs to speed up things a little).
make -C src -f linux.mak
cd ..
# Good, now we have to wire Tango and CDGC together, just create a symbolic
# link:
cd tango
ln -s ../../../../../cdgc/rt/gc/cdgc tango/core/rt/gc/
# Since I don't know very well the Tango build system, I did a Makefile of my
# own to compile it, so just grab it and compile Tango with it. It will use
# the DMD you just compiled and will compile CDGC by default (you can change
# it via the GC Make variable, for example: make GC=basic to compile Tango
# with the basic GC). The library will be written to obj/libtango-$GC.a, so
# you can have both CDGB and the basic collector easily at hand):
wget https://llucax.com/blog/posts/2010/10/10-trying-cdgc-howto/Makefile
make # Again add -jN if you have N CPUs to make a little faster
# Now all you need now is a decent dmd.conf to put it all together:
cd ..
echo "[Environment]" > dmd/src/dmd.conf
echo -n "DFLAGS=-I$PWD/tango -L-L$PWD/tango/obj " >> dmd/src/dmd.conf
echo -n "-defaultlib=tango-cdgc " >> dmd/src/dmd.conf
echo "-debuglib=tango-cdgc -version=Tango" >> dmd/src/dmd.conf
# Finally, try a Hello World:
cat <<EOT > hello.d
import tango.io.Console;
void main()
{
Cout("Hello, World").newline;
}
EOT
dmd/src/dmd -run hello.d
# If you don't trust me and you want to be completely sure you have CDGC
# running, try the collect_stats_file option to generate a log of the
# collections:
D_GC_OPTS=collect_stats_file=log dmd/src/dmd -run hello.d
cat log
Done!
If you want to make this DMD the default, just add dmd/src to the PATH environment variable or do a proper installation ;)
Let me know if you hit any problem...
Bacap updates
by Leandro Lucarella on 2010- 10- 02 00:11 (updated on 2010- 10- 02 00:11)- with 2 comment(s)
Just in case you are a Bacap user (and a lazy one, that doesn't want to subscribe to the repository RSS feed :), you might be interested in a few recent updates:
- Make pinging hosts configurable (a little older :).
- Add FORCE_SYNC option.
- Let rsync do the hard linking.
- Don't provide any default options for ssh.
- Add a Tips section to the README (you can see the tips in the updated website).
- Fix console error reporting when using a LOG_FILE.
Enjoy!
CDGC done
by Leandro Lucarella on 2010- 09- 28 15:16 (updated on 2010- 09- 28 15:16)- with 0 comment(s)
I'm sorry about the quick and uninformative post, but I've been almost 2 weeks without Internet and I have to finish the first complete draft of my thesis in a little more than a week, so I don't have much time to write here.
The thing is, to avoid the nasty effect of memory usage being too high for certain programs when using eager allocation, I've made the GC minimize the heap more often. Even when some test are still a little slower with CDGC, but that's only for tests that only stress the GC without doing any actual work, so I think it's OK, in that cases the extra overhead of being concurrent is bigger than the gain (which is inexistent, because there is nothing to do in parallel with the collector).
Finally, I've implemented early collection, which didn't proved very useful, and tried to keep a better occupancy factor of the heap with the new min_free option, without much success either (it looks like the real winner was eager allocation).
I'm sorry I don't have time to show you some graphs this time. Of course the work is not really finished, there are plenty of things to be done still, but I think the GC have come to a point where it can be really useful, and I have to finish my thesis :)
After I'm done, I hope I can work on integrating the GC in Tango and/or Druntime (where there is already a first approach done by Sean Kelly).
Telecom y LA PUTA QUE TE PARIÓ
by Leandro Lucarella on 2010- 09- 27 23:10 (updated on 2010- 09- 27 23:10)- with 0 comment(s)
Note
English version below.
Huy, tal vez estuve un poco fuerte con el título... O tal vez no.
Hace 13 días que estoy sin teléfono (y por consiguiente Internet, porque tengo ADSL). En realidad vengo con problemas con el teléfono desde junio; los días de lluvia se escuchaba con ruido hasta cortarse (pero extrañamente se cortaba el teléfono pero no Internet) y luego volvía solo.
La fantástica empresa, tan apreciada y conocida por todos, llamada Telecom Argentina funciona tan bien, que llamás al 114 (bah, llama algún conocido porque vos no tenés teléfono) y te atiende un contestador y te dice que tomó el reclamo. Nadie habla de tiempos, nadie habla de nada. Ni te gastes en buscar algún lugar físico de atención al cliente porque al menos en la factura no figura nada, es una empresa fantasma.
Llamé varias veces por el tema de los cortes por lluvia pero nada, solo te amenazan con que cobran la visita si es problema interno de tu casa así que te dicen que te fijes bien que en la entrada del cable a tu casa ande todo bien. El problema es cuando nunca te dijeron donde pusieron la mágica cajita de Telecom que divide tu reino del de ellos. Tener un techo de tejas altísimo no ayuda, porque en general eso está en la terraza.
Luego de probar de todo, llamé y pedí un técnico, cagándome en las amenazas. Pero no, claro, ellos no pueden concertar una cita para un día y hora... Bueno, nadie te dice hora, pero ellos ni siquiera día te dicen. La mecánica es así, te mandan a alguien cuando ellos quieren, si estás bien, y si no recién ahí ven si combinan algún día. ¡Súper eficiente! Y no es que tampoco tarden un día en venir, perder una visita no es poca cosa.
La cosa es que un día cayeron tipo 8 de la mañana, y estaba más dormido que alguien que no está tan tan dormido como yo estaba, que era bastante mucho, y no escuché el timbre. Pero fueron lo suficientemente amables como para llamarme al celular hasta despertarme, a lo que después de regañar un poco por ser unos forros por caer cuando se le canta le dije que ahora los atendía, que me banquen 10 minutos que me levantaba. Ahhhh, la amabilidad de Telecom, tocaron impacientemente el timbre un par de veces más mientras me cambiaba y cuando salí ya se habían ido. Llamé a Telecom para ver que onda, y obviamente nadie sabe nada, es la compañía con peor comunicación interna del mundo, o con peor atención del mundo (me inclino por la segunda). Además, tampoco nadie te dice nada sobre plazos, le pregunté explícitamente si podían tardar un día o una semana o un mes y el muy descarado me dijo "sí". Todo es posible en el maravilloso mundo de Telecom.
Finalmente me llamaron para concertar la entrevista pero el día anterior había llovido y no había pasado nada así que la cancelé (porque lo último que faltaba era que cuando vengan no puedan encontrar el problema y me quieran cobrar diciendo que era problema mío).
Y bueno, así pasaron los días y se hizo 14 de septiembre y el teléfono se cortó a las 16:00hs para nunca más volver, así que llamé de nuevo. El viernes 17, con la velocidad de una babosa sedada, llegó el técnico (de nuevo sin avisar y que me enganchó de pedo antes de salir al laburo) y quiso entrar a la casa, pero le advertí que no había nada que ver adentro, que Telecom a mí nunca me dijo ni donde había puesto la caja. Así que totalmente perdido, se fue a la puerta a verificar una caja externa, con su escalerita de metro y medio que apenas le alcanzó para llegar a esa caja (a mi techo de unos 5 o 6 metros mucho no podía llegar). Y ahí había tono. Con cara de preocupado me dijo que tenía que pedir a otra gente para que lo arregle, a lo que, con cara de resignado, le pregunté "y cuando van a venir", y me dijo, siguiendo firme la política de Telecom "ni idea, ahora con la lluvia viste como es, aparecen todas estas cosas y hay poco personal" a lo que le imploro con cara de desesperado que al menos me de un mínimo o máximo, y me dice que mínimo una semana... ¡Groso!
Llamé de nuevo a Telecom, al área comercial porque en reparaciones te atiende un contestador que dice "su línea ya está en reparaciones" y te corta, y me dicen que ellos no saben nada, que llame a reparaciones. Unos FE NO ME NOS.
El fin de semana, de pedo mirando por la ventana, noté que de la pared del fondo salía un cable, que iba todo por la medianera del fondo hasta el jardín de la vecina, que colgaba largamente hasta subir a su tejado, pero que por la mitad tenía un hermoso empalme, sin siquiera un poco de cinta. Así a lo machote, al aire libre.
Me brillaron los ojitos un poco, pero la indignación casi me mata. Haciéndola corta, le pedí escalera larga a mis viejos prestada, permiso a la vecina y esta tarde por fin pude poner mis manos en él, y voilá! Tengo teléfono/Internet luego de 13 días de corte, gracias a mi alpedismo de mirar por la ventana, mi vecina que se copó, y mis viejos que se ultra-coparon en traerme la escalera. NO gracias a Telecom. Ahora tendré que seguir peleándome para que por un lado me descuenten los días sin servicio, por otro me paguen la multa del doble del abono proporcional por cada día sin servicio por no arreglarlo dentro de los 3 días y finalmente porque vengan a hacer una instalación como la gente, no ese mamamarracho que hicieron de cables colgados y empalmes (hay 2 cables más iguales colgando en el jardín de la vecina).
En fin, están advertidos, si tienen problemas con Telecom, empiecen a buscar la forma de arreglárselos ustedes mismos...
English
I'm sorry but I'll only do a short version in English. I was without phone and Internet for 13 days (and having problems when it rained since June) because the damn Telecom Argentina did my phone installation by throwing an spliced wire, hanging in my neighbor's backyard, that eventually got rusty and finally cut.
They just not respond, they won't do anything, I had to fix it myself. Now I have to keep trying to make them come to do a proper installation, as what I did is a patch over a patch.
64 bits support for mutest
by Leandro Lucarella on 2010- 09- 13 19:51 (updated on 2010- 09- 13 19:51)- with 0 comment(s)
Truly concurrent GC using eager allocation
by Leandro Lucarella on 2010- 09- 10 03:01 (updated on 2010- 09- 10 03:01)- with 0 comment(s)
Finally, I got the first version of CDGC with truly concurrent garbage collection, in the sense that all the threads of the mutator (the program itself) can run in parallel with the collector (well, only the mark phase to be honest :).
You might want to read a previous post about CDGC where I achieved some sort of concurrency by making only the stop-the-world time very short, but the thread that triggered the collection (and any other thread needing any GC service) had to wait until the collection finishes. The thread that triggered the collection needed to wait for the collection to finish to fulfill the memory allocation request (it was triggered because the memory was exhausted), while any other thread needing any GC service needed to acquire the global GC lock (damn global GC lock!).
To avoid this issue, I took a simple approach that I call eager allocation, consisting on spawn the mark phase concurrently but allocating a new memory pool to be able to fulfill the memory request instantly. Doing so, not only the thread that triggered the collection can keep going without waiting the collection to finish, the global GC lock is released and any other thread can use any GC service, and even allocate more memory, since a new pool was allocated.
If the memory is exhausted again before the collection finishes, a new pool is allocated, so everything can keep running. The obvious (bad) consequence of this is potential memory bloat. Since the memory usage is minimized from time to time, this effect should not be too harmful though, but let's see the results, there are plenty of things to analyze from them (a lot not even related to concurrency).
First, a couple of comments about the plots:
- Times of Dil are multiplied by a factor of 0.1 in all the plots, times of rnddata are too, but only in the pause time and stop-the-world plots. This is only to make the plots more readable.
- The unreadable labels rotated 45 degrees say: stw, fork and ea. Those stand for Stop-the-world (the basic collector), fork only (concurrent but without eager allocation) and eager allocation respectively. You can click on the images to see a little more readable SVG version.
- The plots are for one CPU-only because using more CPUs doesn't change much (for these plots).
- The times were taken from a single run, unlike the total run time plots I usually post. Since a single run have multiple collections, the information about min, max, average and standard deviation still applies for the single run.
- Stop-the-world time is the time no mutator thread can run. This is not related to the global GC lock, is time the threads are really really paused (this is even necessary for the forking GC to take a snapshot of threads CPU registers and stacks). So, the time no mutator thread can do any useful work might be much bigger than this time, because the GC lock. This time is what I call Pause time. The maximum pause time is probably the most important variable for a GC that tries to minimize pauses, like this one. Is the maximum time a program will stay totally unresponsive (important for a server, a GUI application, a game or any interactive application).

The stop-the-world time is reduced so much that you can hardly see the times of the fork and ea configuration. It's reduced in all tests by a big margin, except for mcore and the bigarr. For the former it was even increased a little, for the later it was reduced but very little (but only for the ea* configuration, so it might be a bad measure). This is really measuring the Linux fork() time. When the program manages so little data that the mark phase itself is so fast that's faster than a fork(), this is what happens. The good news is, the pause times are small enough for those cases, so no harm is done (except from adding a little more total run time to the program).
Note the Dil maximum stop-the-world time, it's 0.2 seconds, looks pretty big, uh? Well, now remember that this time was multiplied by 0.1, the real maximum stop-the-world for Dil is 2 seconds, and remember this is the minimum amount of time the program is unresponsive! Thank god it's not an interactive application :)
Time to take a look to the real pause time:

OK, this is a little more confusing... The only strong pattern is that pause time is not changed (much) between the swt and fork configurations. This seems to make sense, as both configurations must wait for the whole collection to finish (I really don't know what's happening with the bh test).
For most tests (7), the pause time is much smaller for the ea configuration, 3 tests have much bigger times for it, one is bigger but similar (again mcore) and then is the weird case of bh. The 7 tests where the time is reduced are the ones that seems to make sense, that's what I was looking for, so let's see what's happening with the remaining 3, and for that, let's take a look at the amount of memory the program is using, to see if the memory bloat of allocating extra pools is significant.
| Test | Maximum heap size (MB) | ||
|---|---|---|---|
| Program | stw | ea | ea/stw |
| dil | 216 | 250 | 1.16 |
| rnddata | 181 | 181 | 1 |
| voronoi | 16 | 30 | 1.88 |
| tree | 7 | 114 | 16.3 |
| bh | 80 | 80 | 1 |
| mcore | 30 | 38 | 1.27 |
| bisort | 30 | 30 | 1 |
| bigarr | 11 | 223 | 20.3 |
| em3d | 63 | 63 | 1 |
| sbtree | 11 | 122 | 11.1 |
| tsp | 63 | 63 | 1 |
| split | 39 | 39 | 1 |
See any relations between the plot and the table? I do. It looks like some programs are not being able to minimize the memory usage, and because of that, the sweep phase (which still have to run in a mutator thread, taking the global GC lock) is taking ages. An easy to try approach is to trigger the minimization of the memory usage not only at when big objects are allocated (like it is now), but that could lead to more mmap()/munmap()s than necessary. And there still problems with pools that are kept alive because a very small object is still alive, which is not solved by this.
So I think a more long term solution would be to introduce what I call early collection too. Meaning, trigger a collection before the memory is exhausted. That would be the next step in the CDGC.
Finally, let's take a look at the total run time of the test programs using the basic GC and CDGC with concurrent marking and eager allocation. This time, let's see what happens with 2 CPUs (and 25 runs):

Wow! It looks like this is getting really juicy (with exceptions, as usual :)! Dil time is reduced to about 1/3, voronoi is reduced to 1/10!!! Split and mcore have both their time considerably reduced, but that's because another small optimization (unrelated to what we are seeing today), so forget about those two. Same for rnddata, which is reduced because of precise heap scanning. But other tests increased its runtime, most notably bigarr takes almost double the time. Looking at the maximum heap size table, one can find some answers for this too. Another ugly side of early allocation.
For completeness, let's see what happens with the number of collections triggered during the program's life. Here is the previous table with this new data added:
| Test | Maximum heap size (MB) | Number of collections | ||||
|---|---|---|---|---|---|---|
| Program | stw | ea | ea/stw | stw | ea | ea/stw |
| dil | 216 | 250 | 1.16 | 62 | 50 | 0.81 |
| rnddata | 181 | 181 | 1 | 28 | 28 | 1 |
| voronoi | 16 | 30 | 1.88 | 79 | 14 | 0.18 |
| tree | 7 | 114 | 16.3 | 204 | 32 | 0.16 |
| bh | 80 | 80 | 1 | 27 | 27 | 1 |
| mcore | 30 | 38 | 1.27 | 18 | 14 | 0.78 |
| bisort | 30 | 30 | 1 | 10 | 10 | 1 |
| bigarr | 11 | 223 | 20.3 | 305 | 40 | 0.13 |
| em3d | 63 | 63 | 1 | 14 | 14 | 1 |
| sbtree | 11 | 122 | 11.1 | 110 | 33 | 0.3 |
| tsp | 63 | 63 | 1 | 14 | 14 | 1 |
| split | 39 | 39 | 1 | 7 | 7 | 1 |
See how the number of collections is practically reduced proportionally to the increase of the heap size. When the increase in size explodes, even when the number of collections is greatly reduced, the sweep time take over and the total run time is increased. Specially in those tests where the program is almost only using the GC (as in sbtree and bigarr). That's why I like the most Dil and voronoi as key tests, they do quite a lot of real work beside asking for memory or using other GC services.
This confirms that the performance gain is not strictly related to the added concurrency, but because of a nice (finally! :) side-effect of eager allocation: removing some pressure from the GC by increasing the heap size a little (Dil gets 3x boost in run time for as little as 1.16x of memory usage; voronoi gets 10x at the expense of almost doubling the heap, I think both are good trade-offs). This shows another weak point of the GC, sometimes the HEAP is way too tight, triggering a lot of collections, which leads to a lot of GC run time overhead. Nothing is done right now to keep a good heap occupancy ratio.
But is there any real speed (in total run time terms) improvement because of the added concurrency? Let's see the run time for 1 CPU:

It looks like there is, specially for my two favourite tests: both Dil and voronoi get a 30% speed boost! That's not bad, not bad at all...
If you want to try it, the repository has been updated with this last changes :). If you do, please let me know how it went.
The Wilderness Downtown
by Leandro Lucarella on 2010- 09- 01 01:40 (updated on 2010- 09- 01 01:40)- with 0 comment(s)
The Wilderness Downtown is a new interactive film by Chris Milk (done in HTML5 as a Google Chrome Experiment), and the new video for the song We Used To Wait from Arcade Fire. Judging from this, and the Unstaged show it looks like they are willing to play with the new technologies.
I like the video, for some reason it reminds me of House Of Cards (maybe because Google was involved too). The downside is, it only works on Chrome / Chromium.
Recursive vs. iterative marking
by Leandro Lucarella on 2010- 08- 30 00:54 (updated on 2010- 08- 30 00:54)- with 0 comment(s)
After a small (but important) step towards making the D GC truly concurrent (which is my main goal), I've been exploring the possibility of making the mark phase recursive instead of iterative (as it currently is).
The motivation is that the iterative algorithm makes several passes through the entire heap (it doesn't need to do the full job on each pass, it processes only the newly reachable nodes found in the previous iteration, but to look for that new reachable node it does have to iterate over the entire heap). The number of passes is the same as the connectivity graph depth, the best case is where all the heap is reachable through the root set, and the worse is when the heap is a single linked list. The recursive algorithm, on the other hand, needs only a single pass but, of course, it has the problem of potentially consuming a lot of stack space (again, the recurse depth is the same as the connectivity graph depth), so it's not paradise either.
To see how much of a problem is the recurse depth in reality, first I've implemented a fully recursive algorithm, and I found it is a real problem, since I had segmentation faults because the (8MiB by default in Linux) stack overflows. So I've implemented an hybrid approach, setting a (configurable) maximum recurse depth for the marking phase. If the maximum depth is reached, the recursion is stopped and nodes that should be scanned deeply than that are queued to scanned in the next iteration.
Here are some results showing how the total run time is affected by the maximum recursion depth:
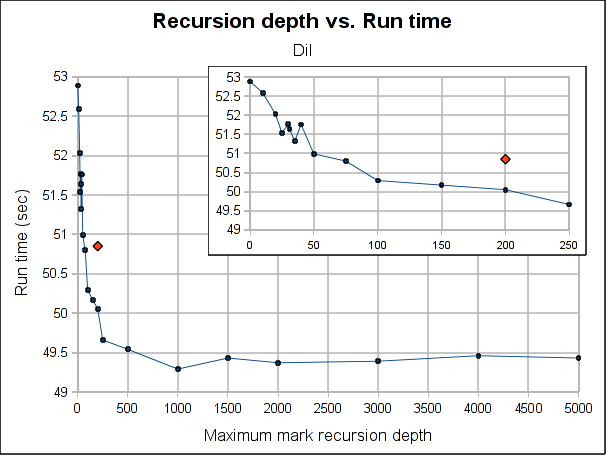
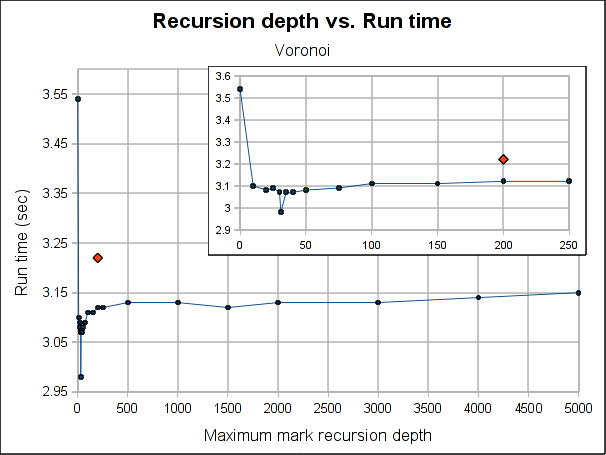
The red dot is how the pure iterative algorithm currently performs (it's placed arbitrarily in the plot, as the X-axis doesn't make sense for it).
The results are not very conclusive. Even when the hybrid approach performs better for both Dil and Voronoi when the maximum depth is bigger than 75, the better depth is program specific. Both have its worse case when depth is 0, which makes sense, because is paying the extra complexity of the hybrid algorithm with using its power. As soon as we leave the 0 depth, a big drop is seen, for Voronoi big enough to outperform the purely iterative algorithm, but not for Dil, which matches it near 60 and clearly outperforms it at 100.
As usual, Voronoi challenges all logic, as the best depth is 31 (it was a consistent result among several runs). Between 20 and 50 there is not much variation (except for the magic number 31) but when going beyond that, it worsen slowly but constantly as the depth is increased.
Note that the plots might make the performance improvement look a little bigger than it really is. The best case scenario the gain is 7.5% for Voronoi and 3% for Dil (which is probably better measure for the real world). If I had to choose a default, I'll probably go with 100 because is where both get a performance gain and is still a small enough number to ensure no segmentation faults due to stack exhaustion is caused (only) by the recursiveness of the mark phase (I guess a value of 1000 would be reasonable too, but I'm a little scared of causing inexplicable, magical, mystery segfaults to users). Anyway, for a value of 100, the performance gain is about 1% and 3.5% for Dil and Voronoi respectively.
So I'm not really sure if I should merge this change or not. In the best case scenarios (which requires a work from the user to search for the better depth for its program), the performance gain is not exactly huge and for a reasonable default value is so little that I'm not convinced the extra complexity of the change (because it makes the marking algorithm a little more complex) worth it.
Feel free to leave your opinion (I would even appreciate it if you do :).
The Yes Men Fix The World
by Leandro Lucarella on 2010- 08- 23 22:54 (updated on 2010- 08- 23 22:54)- with 0 comment(s)
I once recommended The Yes Men, now their new movie, The Yes Men Fix The World is officially available for download in Vodo (HD and mobile versions included) via BitTorrent. There are subtitles for several languages (more are coming) and you can donate to The Yes Men so they can film their next movie.
Great mov(i)e!
CDGC first breath
by Leandro Lucarella on 2010- 08- 23 02:03 (updated on 2010- 08- 23 02:03)- with 0 comment(s)
I'm glad to announce that now, for the first time, CDGC means Concurrent D Garbage Collector, as I have my first (extremely raw and unoptimized) version of the concurrent GC running. And I have to say, I'm very excited and happy with the results from the very small benchmark I did.
The stop-the-world (pause) time was reduced by 2 orders of magnitude for the average, the standard deviation and, probably the more important, the maximum (these are the results for a single run, measuring the pause time for all the collections in that run). This is good news for people needing (soft) real-time in D, even when using the GC. Where the standard D GC have a pause time of 100ms, the CDGC have a pause time of 1ms.
The total run-time of the program was increased a little though, but not as much as the pause time was reduced. Only a 12% performance loss was measured, but this is just the first raw unoptimized version of the CDGC.
All this was measured with the voronoi benchmark, with -n 30000. Here are some plots:
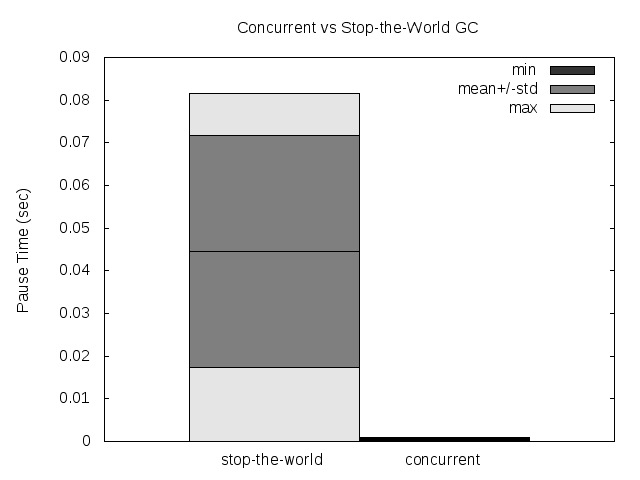
Please note that the GC still has a global lock, so if 2 threads needs to allocate while the collection is running, both will be paused anyways (I have a couple of ideas on how to try to avoid that).
The idea about how to make the GC concurrent is based on the paper Nonintrusive Cloning Garbage Collector with Stock Operating System Support. I'm particularly excited by the results because the reduction of the pause time in the original paper were less than 1 order of magnitude better than their stop-the-world collector, so the preliminary results of the CDGC are much better than I expected.
The Suburbs Unstaged
by Leandro Lucarella on 2010- 08- 21 22:03 (updated on 2010- 08- 21 23:04)- with 0 comment(s)
You might already know about the new Arcade Fire album, The Suburbs.
Even when is a good album, I think is by far the less interesting / innovative / emotional from the band (at least from the musical point of view, I didn't payed much attention to the lyrics yet), but I still love their live performance, and I've came across the Unstaged series at the Madison Square Garden and directed by Terry Gilliam. The videos are available in YouTube in HD (many thanks to youtube-dl [*] that let me see the concert without suffering the f*cking Flash Player).
Here is Sprawl II (Mountains Beyond Mountains), my favourite song from the new album:
Update
You can download all the videos in HD using youtube-dl with this small bash script:
for i in h0DpBOYzXcQ 5pp3olGyku0 TtbrY6QrgPw 7vS5crSXJ6k GGdyG_83nX4 \
DSykB-j_2UQ Q2T-ZAharmY 0L6ZFhZVOx0 CLjrQ3cwzJ4 RdYyYFymH-Y \
sVW9usMRgNE bjhAP3V1o0w Q7fRvPjKDLs N9WR_eK0Rac bhwdd_01Ots \
0ozdCLrTrtA diK1tZOXgDk 0ozdCLrTrtA aXuymDSGCko MQvZ4N1RfS8 \
siFsdInZqC0 MXJi5_yThNY
do
youtube-dl -f 37 -t "http://www.youtube.com/watch?v=$i"
done
| [*] | Tip: Download the files using the option -f 37 to get the HD version =) |
TypeInfo, static data and the GC
by Leandro Lucarella on 2010- 08- 16 00:39 (updated on 2010- 08- 16 00:39)- with 0 comment(s)
The D compiler doesn't provide any information on the static data that the GC must scan, so the runtime/GC have to use OS-dependant tricks to get that information.
Right now, in Linux, the GC gets the static data to scan from the libc's variables __data_start and _end, from which are not much information floating around except for some e-mail from Hans Boehm to the binutils mainling list.
There is a lot of stuff in the static data that doesn't need to be scanned, most notably the TypeInfo, which is a great portion of the static data. C libraries static data, for example, would be scanned too, when it makes no sense to do so.
I noticed CDGC has more than double the static data the basic GC has, just because of TypeInfo (I use about 5 or so more types, one of them is a template, which makes the bloat bigger).
The voronoi test goes from 21KB to 26KB of static data when using CDGC.
It would be nice if the compiler could group all the static that must really be scanned (programs static variables) together and make its limits available to the GC. It would be even nicer to leave static variables that have no pointers out of that group, and even much more nicer to create a pointer map like the one in the patch for precise scanning to allow precise heap scanning. Then only the scan should be scanned in full conservative mode.
I reported a bug with this issue so it doesn't get lost.
Memory allocation patterns
by Leandro Lucarella on 2010- 08- 14 06:28 (updated on 2010- 08- 14 16:09)- with 0 comment(s)
Note
Tango 0.99.9 has a bug in its runtime, which sometimes makes the GC scan memory that should not be scanned. It only affects Dil and Voronoi programs, but in a significant way. The tests in this post are done using a patched runtime, with the bug fixed.
Update
The results for the unpublished programs are now available. You can find the graphic results, the detailed summary and the source code for all the programs (except dil, which can be downloaded from its home site).
After seeing some weird behaviours and how different benchmarks are more or less affected by changes like memory addresses returned by the OS or by different ways to store the type information pointer, I decided to gather some information about how much and what kind of memory are requested by the different benchmarks.
I used the information provided by the malloc_stats_file CDGC option, and generated some stats.
The analysis is done on the allocations requested by the program (calls to gc_malloc()) and contrasting that with the real memory allocated by the GC. Note that only the GC heap memory (that is, memory dedicated to the program, which the GC scans in the collections) is counted (internal GC memory used for bookkeeping is not).
Also note that in this post I generally refer to object meaning a block of memory, it doesn't mean they are actually instance of a class or anything. Finally bear in mind that all the figures shown here are the sum of all the allocations done in the life of a program. If the collected data says a program requested 1GiB of memory, that doesn't mean the program had a residency of 1GiB, the program could had a working set of a few KiB and recycled memory like hell.
When analyzing the real memory allocated by the GC, there are two modes being analyzed, one is the classic conservative mode and the other is the precise mode (as it is in the original patch, storing the type information pointer at the end of the blocks). So the idea here is to measure two major things:
- The amount of memory wasted by the GC because of how it arranges memory as fixed-size blocks (bins) and large objects that uses whole pages.
- The extra amount of memory wasted by the GC when using precise mode because it stores the type information pointer at the end of the blocks.
I've selected a few representative benchmarks. Here are the results:
bh allocation pattern
This is a translation by Leonardo Maffi from the Olden Benchmark that does a Barnes–Hut simulation. The program is CPU intensive an does a lot of allocation of about 5 different small objects.
Here is a graphic summary of the allocation requests and real allocated memory for a run with -b 4000:




We can easily see here how the space wasted by the GC memory organization is significant (about 15% wasted), and how the type information pointer is adding an even more significant overhead (about 36% of the memory is wasted). This means that this program will be 15% more subject to false pointers (and will have to scan some extra memory too, but fortunately the majority of the memory doesn't need to be scanned) than it should in conservative mode and that the precise mode makes things 25% worse.
You can also see how the extra overhead in the precise mode is because some objects that should fit in a 16 bin now need a 32 bytes bin to hold the extra pointer. See how there were no waste at all in the conservative mode for objects that should fit a 16 bytes bin. 117MiB are wasted because of that.
Here is a more detailed (but textual) summary of the memory requested and allocated:
- Requested
- Total
- 15,432,462 objecs, 317,236,335 bytes [302.54MiB]
- Scanned
- 7,757,429 (50.27%) objecs, 125,360,510 bytes [119.55MiB] (39.52%)
- Not scanned
- 7,675,033 (49.73%) objecs, 191,875,825 bytes [182.99MiB] (60.48%)
- Different object sizes
- 8
- Objects requested with a bin size of:
- 16 bytes
- 7,675,064 (49.73%) objects, 122,801,024 bytes [117.11MiB] (38.71%)
- 32 bytes
- 7,734,214 (50.12%, 99.85% cumulative) objects, 193,609,617 bytes [184.64MiB] (61.03%, 99.74% cumulative)
- 64 bytes
- 23,181 (0.15%, 100% cumulative) objects, 824,988 bytes [805.65KiB] (0.26%, 100% cumulative)
- 256 bytes
- 2 (0%, 100% cumulative) objects, 370 bytes (0%, 100% cumulative)
- 512 bytes
- 1 (0%, 100% cumulative) objects, 336 bytes (0%, 100% cumulative)
- Allocated
- Conservative mode
- Total allocated
- 371,780,480 bytes [354.56MiB]
- Total wasted
- 54,544,145 bytes [52.02MiB], 14.67%
- Wasted due to objects that should use a bin of
- 16 bytes
- 0 bytes (0%)
- 32 bytes
- 53,885,231 bytes [51.39MiB] (98.79%, 98.79% cumulative)
- 64 bytes
- 658,596 bytes [643.16KiB] (1.21%, 100% cumulative)
- 256 bytes
- 142 bytes (0%, 100% cumulative)
- 512 bytes
- 176 bytes (0%, 100% cumulative)
- Precise mode
- Total allocated
- 495,195,296 bytes [472.26MiB]
- Total wasted
- 177,958,961 bytes [169.71MiB], 35.94%
- Wasted due to objects that should use a bin of
- 16 bytes
- 122,801,024 bytes [117.11MiB] (69.01%)
- 32 bytes
- 54,499,023 bytes [51.97MiB] (30.62%, 99.63% cumulative)
- 64 bytes
- 658,596 bytes [643.16KiB] (0.37%, 100% cumulative)
- 256 bytes
- 142 bytes (0%, 100% cumulative)
- 512 bytes
- 176 bytes (0%, 100% cumulative)
bigarr allocation pattern
This is a extremely simple program that just allocate a big array of small-medium objects (all of the same size) I found in the D NG.
Here is the graphic summary:




The only interesting part of this test is how many space is wasted because of the memory organization, which in this case goes up to 30% for the conservative mode (and have no change for the precise mode).
Here is the detailed summary:
- Requested
- Total
- 12,000,305 objecs, 1,104,160,974 bytes [1.03GiB]
- Scanned
- 12,000,305 (100%) objecs, 1,104,160,974 bytes [1.03GiB] (100%)
- Not scanned
- 0 (0%) objecs, 0 bytes (0%)
- Different object sizes
- 5
- Objects requested with a bin size of
- 128 bytes
- 12,000,000 (100%, 100% cumulative) objects, 1,056,000,000 bytes [1007.08MiB] (95.64%, 95.64% cumulative)
- 256 bytes
- 2 (0%, 100% cumulative) objects, 322 bytes (0%, 95.64% cumulative)
- 512 bytes
- 1 (0%, 100% cumulative) objects, 336 bytes (0%, 95.64% cumulative)
- more than a page
- 302 (0%) objects, 48,160,316 bytes [45.93MiB] (4.36%)
- Allocated
- Conservative mode
- Total allocated
- 1,584,242,808 bytes [1.48GiB]
- Total wasted
- 480,081,834 bytes [457.84MiB], 30.3%
- Wasted due to objects that should use a bin of
- 128 bytes
- 480,000,000 bytes [457.76MiB] (99.98%, 99.98% cumulative)
- 256 bytes
- 190 bytes (0%, 99.98% cumulative)
- 512 bytes
- 176 bytes (0%, 99.98% cumulative)
- more than a page
- 81,468 bytes [79.56KiB] (0.02%)
- Precise mode
- Total allocated
- 1,584,242,808 bytes [1.48GiB]
- Total wasted
- 480,081,834 bytes [457.84MiB], 30.3%
- Wasted due to objects that should use a bin of:
- 128 bytes
- 480,000,000 bytes [457.76MiB] (99.98%, 99.98% cumulative)
- 256 bytes
- 190 bytes (0%, 99.98% cumulative)
- 512 bytes
- 176 bytes (0%, 99.98% cumulative)
- more than a page
- 81,468 bytes [79.56KiB] (0.02%)
mcore allocation pattern
This is program that test the contention produced by the GC when appending to (thread-specific) arrays in several threads concurrently (again, found at the D NG). For this analysis the concurrency doesn't play any role though, is just a program that do a lot of appending to a few arrays.
Here are the graphic results:




This is the most boring of the examples, as everything works as expected =)
You can clearly see how the arrays grow, passing through each bin size and finally becoming big objects which take most of the allocated space. Almost nothing need to be scanned (they are int arrays), and practically there is no waste. That's a good decision by the array allocation algorithm, which seems to exploit the bin sizes to the maximum. Since almost all the data is doesn't need to be scanned, there is no need to store the type information pointers, so there is no waste either for the precise mode (the story would be totally different if the arrays were of objects that should be scanned, as probably each array allocation would waste about 50% of the memory to store the type information pointer).
Here is the detailed summary:
- Requested
- Total requested
- 367 objecs, 320,666,378 bytes [305.81MiB]
- Scanned
- 8 (2.18%) objecs, 2,019 bytes [1.97KiB] (0%)
- Not scanned
- 359 (97.82%) objecs, 320,664,359 bytes [305.81MiB] (100%)
- Different object sizes
- 278
- Objects requested with a bin size of
- 16 bytes
- 4 (1.09%) objects, 20 bytes (0%)
- 32 bytes
- 5 (1.36%, 2.45% cumulative) objects, 85 bytes (0%, 0% cumulative)
- 64 bytes
- 4 (1.09%, 3.54% cumulative) objects, 132 bytes (0%, 0% cumulative)
- 128 bytes
- 4 (1.09%, 4.63% cumulative) objects, 260 bytes (0%, 0% cumulative)
- 256 bytes
- 6 (1.63%, 6.27% cumulative) objects, 838 bytes (0%, 0% cumulative)
- 512 bytes
- 9 (2.45%, 8.72% cumulative) objects, 2,708 bytes [2.64KiB] (0%, 0% cumulative)
- 1024 bytes
- 4 (1.09%, 9.81% cumulative) objects, 2,052 bytes [2KiB] (0%, 0% cumulative)
- 2048 bytes
- 4 (1.09%, 10.9% cumulative) objects, 4,100 bytes [4KiB] (0%, 0% cumulative)
- 4096 bytes
- 4 (1.09%, 11.99% cumulative) objects, 8,196 bytes [8KiB] (0%, 0.01% cumulative)
- more than a page
- 323 (88.01%) objects, 320,647,987 bytes [305.79MiB] (99.99%)
- Allocated
- Conservative mode
- Total allocated
- 321,319,494 bytes [306.43MiB]
- Total wasted
- 653,116 bytes [637.81KiB], 0.2%
- Wasted due to objects that should use a bin of
- 16 bytes
- 44 bytes (0.01%)
- 32 bytes
- 75 bytes (0.01%, 0.02% cumulative)
- 64 bytes
- 124 bytes (0.02%, 0.04% cumulative)
- 128 bytes
- 252 bytes (0.04%, 0.08% cumulative)
- 256 bytes
- 698 bytes (0.11%, 0.18% cumulative)
- 512 bytes
- 1,900 bytes [1.86KiB] (0.29%, 0.47% cumulative)
- 1024 bytes
- 2,044 bytes [2KiB] (0.31%, 0.79% cumulative)
- 2048 bytes
- 4,092 bytes [4KiB] (0.63%, 1.41% cumulative)
- 4096 bytes
- 8,188 bytes [8KiB] (1.25%, 2.67% cumulative)
- more than a page
- 635,699 bytes [620.8KiB] (97.33%)
- Precise mode
- Total allocated
- 321,319,494 bytes [306.43MiB]
- Total wasted
- 653,116 bytes [637.81KiB], 0.2%
- Wasted due to objects that should use a bin of
- 16 bytes
- 44 bytes (0.01%)
- 32 bytes
- 75 bytes (0.01%, 0.02% cumulative)
- 64 bytes
- 124 bytes (0.02%, 0.04% cumulative)
- 128 bytes
- 252 bytes (0.04%, 0.08% cumulative)
- 256 bytes
- 698 bytes (0.11%, 0.18% cumulative)
- 512 bytes
- 1,900 bytes [1.86KiB] (0.29%, 0.47% cumulative)
- 1024 bytes
- 2,044 bytes [2KiB] (0.31%, 0.79% cumulative)
- 2048 bytes
- 4,092 bytes [4KiB] (0.63%, 1.41% cumulative)
- 4096 bytes
- 8,188 bytes [8KiB] (1.25%, 2.67% cumulative)
- more than a page
- 635,699 bytes [620.8KiB] (97.33%)
voronoi allocation pattern
This is one of my favourites, because is always problematic. It "computes the voronoi diagram of a set of points recursively on the tree" and is also taken from the Olden Benchmark and translated by Leonardo Maffi to D.
Here are the graphic results for a run with -n 30000:




This have a little from all the previous examples. Practically all the heap should be scanned (as in bigarr), it wastes a considerably portion of the heap because of the fixed-size blocks (as all but mcore), it wastes just a very little more because of type information (as all but bh) but that waste comes from objects that should fit in a 16 bytes bin but is stored in a 32 bytes bin instead (as in bh).
Maybe that's why it's problematic, it touches a little mostly all the GC flaws.
Here is the detailed summary:
- Requested
- Total requested
- 1,309,638 objecs, 33,772,881 bytes [32.21MiB]
- Scanned
- 1,309,636 (100%) objecs, 33,772,849 bytes [32.21MiB] (100%)
- Not scanned
- 2 (0%) objecs, 32 bytes (0%)
- Different object sizes
- 6
- Objects requested with a bin size of
- 16 bytes
- 49,152 (3.75%) objects, 786,432 bytes [768KiB] (2.33%)
- 32 bytes
- 1,227,715 (93.74%, 97.5% cumulative) objects, 31,675,047 bytes [30.21MiB] (93.79%, 96.12% cumulative)
- 64 bytes
- 32,768 (2.5%, 100% cumulative) objects, 1,310,720 bytes [1.25MiB] (3.88%, 100% cumulative)
- 256 bytes
- 2 (0%, 100% cumulative) objects, 346 bytes (0%, 100% cumulative)
- 512 bytes
- 1 (0%, 100% cumulative) objects, 336 bytes (0%, 100% cumulative)
- Allocated
- Conservative mode
- Total allocated
- 42,171,488 bytes [40.22MiB]
- Total wasted
- 8,398,607 bytes [8.01MiB], 19.92%
- Wasted due to objects that should use a bin of
- 16 bytes
- 0 bytes (0%)
- 32 bytes
- 7,611,833 bytes [7.26MiB] (90.63%, 90.63% cumulative)
- 64 bytes
- 786,432 bytes [768KiB] (9.36%, 100% cumulative)
- 256 bytes
- 166 bytes (0%, 100% cumulative)
- 512 bytes
- 176 bytes (0%, 100% cumulative)
- Precise mode
- Total allocated
- 42,957,888 bytes [40.97MiB]
- Total wasted
- 9,185,007 bytes [8.76MiB], 21.38%
- Wasted due to objects that should use a bin of
- 16 bytes
- 786,400 bytes [767.97KiB] (8.56%)
- 32 bytes
- 7,611,833 bytes [7.26MiB] (82.87%, 91.43% cumulative)
- 64 bytes
- 786,432 bytes [768KiB] (8.56%, 100% cumulative)
- 256 bytes
- 166 bytes (0%, 100% cumulative)
- 512 bytes
- 176 bytes (0%, 100% cumulative)
Dil allocation pattern
Finally, this is by far my favourite, the only real-life program, and the most colorful example (literally =).
Dil is a D compiler, and as such, it works a lot with strings, a lot of big chunks of memory, a lot of small objects, it has it all! String manipulation stress the GC a lot, because it uses objects (blocks) of all possible sizes ever, specially extremely small objects (less than 8 bytes, even a lot of blocks of just one byte!).
Here are the results of a run of Dil to generate Tango documentation (around 555 source files are processed):




Didn't I say it was colorful?
This is like the voronoi but taken to the extreme, it really have it all, it allocates all types of objects in significant quantities, it wastes a lot of memory (23%) and much more when used in precise mode (33%).
Here is the detailed summary:
- Requested
- Total
- 7,307,686 objecs, 322,411,081 bytes [307.48MiB]
- Scanned
- 6,675,124 (91.34%) objecs, 227,950,157 bytes [217.39MiB] (70.7%)
- Not scanned
- 632,562 (8.66%) objecs, 94,460,924 bytes [90.08MiB] (29.3%)
- Different object sizes
- 6,307
- Objects requested with a bin size of
- 16 bytes
- 2,476,688 (33.89%) objects, 15,693,576 bytes [14.97MiB] (4.87%)
- 32 bytes
- 3,731,864 (51.07%, 84.96% cumulative) objects, 91,914,815 bytes [87.66MiB] (28.51%, 33.38% cumulative)
- 64 bytes
- 911,016 (12.47%, 97.43% cumulative) objects, 41,918,888 bytes [39.98MiB] (13%, 46.38% cumulative)
- 128 bytes
- 108,713 (1.49%, 98.91% cumulative) objects, 8,797,572 bytes [8.39MiB] (2.73%, 49.11% cumulative)
- 256 bytes
- 37,900 (0.52%, 99.43% cumulative) objects, 6,354,323 bytes [6.06MiB] (1.97%, 51.08% cumulative)
- 512 bytes
- 22,878 (0.31%, 99.75% cumulative) objects, 7,653,461 bytes [7.3MiB] (2.37%, 53.45% cumulative)
- 1024 bytes
- 7,585 (0.1%, 99.85% cumulative) objects, 4,963,029 bytes [4.73MiB] (1.54%, 54.99% cumulative)
- 2048 bytes
- 3,985 (0.05%, 99.9% cumulative) objects, 5,451,493 bytes [5.2MiB] (1.69%, 56.68% cumulative)
- 4096 bytes
- 2,271 (0.03%, 99.93% cumulative) objects, 6,228,433 bytes [5.94MiB] (1.93%, 58.61% cumulative)
- more than a page
- 4,786 (0.07%) objects, 133,435,491 bytes [127.25MiB] (41.39%)
- Allocated
- Conservative mode
- Total allocated
- 419,368,774 bytes [399.94MiB]
- Total wasted
- 96,957,693 bytes [92.47MiB], 23.12%
- Wasted due to objects that should use a bin of
- 16 bytes
- 23,933,432 bytes [22.82MiB] (24.68%)
- 32 bytes
- 27,504,833 bytes [26.23MiB] (28.37%, 53.05% cumulative)
- 64 bytes
- 16,386,136 bytes [15.63MiB] (16.9%, 69.95% cumulative)
- 128 bytes
- 5,117,692 bytes [4.88MiB] (5.28%, 75.23% cumulative)
- 256 bytes
- 3,348,077 bytes [3.19MiB] (3.45%, 78.68% cumulative)
- 512 bytes
- 4,060,075 bytes [3.87MiB] (4.19%, 82.87% cumulative)
- 1024 bytes
- 2,804,011 bytes [2.67MiB] (2.89%, 85.76% cumulative)
- 2048 bytes
- 2,709,787 bytes [2.58MiB] (2.79%, 88.56% cumulative)
- 4096 bytes
- 3,073,583 bytes [2.93MiB] (3.17%, 91.73% cumulative)
- more than a page
- 8,020,067 bytes [7.65MiB] (8.27%)
- Precise mode:
- Total allocated
- 482,596,774 bytes [460.24MiB]
- Total wasted
- 160,185,693 bytes [152.76MiB], 33.19%
- Wasted due to objects that should use a bin of
- 16 bytes
- 26,820,824 bytes [25.58MiB] (16.74%)
- 32 bytes
- 85,742,913 bytes [81.77MiB] (53.53%, 70.27% cumulative)
- 64 bytes
- 18,070,872 bytes [17.23MiB] (11.28%, 81.55% cumulative)
- 128 bytes
- 5,221,884 bytes [4.98MiB] (3.26%, 84.81% cumulative)
- 256 bytes
- 3,400,557 bytes [3.24MiB] (2.12%, 86.93% cumulative)
- 512 bytes
- 4,125,611 bytes [3.93MiB] (2.58%, 89.51% cumulative)
- 1024 bytes
- 2,878,763 bytes [2.75MiB] (1.8%, 91.31% cumulative)
- 2048 bytes
- 2,760,987 bytes [2.63MiB] (1.72%, 93.03% cumulative)
- 4096 bytes
- 3,143,215 bytes [3MiB] (1.96%, 94.99% cumulative)
- more than a page
- 8,020,067 bytes [7.65MiB] (5.01%)
Conclusion
I've analyzed other small fabricated benchmarks, but all of them had results very similar to the ones shown here.
I think the overallocation problem is more serious than what one might think at first sight. Bear in mind this is not GC overhead, is not because of internal GC data. Is memory the GC or the mutator cannot use. Is memory wasted because of fragmentation (planned fragmentation, but fragmentation at least). And I don't think this is the worse problem. The worse problem is, this memory will need to be scanned in most cases (Dil needs to scan 70% of the total memory requested), and maybe the worse of all is that is subject to false pointer. A false pointer to a memory location that is not actually being used by the program will keep the block alive! If is a large object (several pages) that could be pretty nasty.
This problems can be addressed in several ways. One is mitigate the problem by checking (when type information is available) what portions of the memory is really used and what is wasted, and don't keep things alive when they are only pointed to wasted memory. This is not free though, it will consume more CPU cycles so the solution could be worse than the problem.
I think it worth experimenting with other heap organizations, for example, I would experiment with one free list for object size instead of pre-fixed-sizes. I would even experiment with a free list for each type when type information is available, that would save a lot of space (internal GC space) when storing type information. Some specialization for strings could be useful too.
Unfortunately I don't think I'll have the time to do this, at least for the thesis, but I think is a very rich and interesting ground to experiment.
Add PC-beep whitelist for an Intel board
by Leandro Lucarella on 2010- 08- 11 00:49 (updated on 2010- 08- 11 00:49)- with 0 comment(s)
Yaii! My beep will be back in the next kernel release :)
This is a note to let you know that I've just added the patch titled
ALSA: hda - Add PC-beep whitelist for an Intel board
to the 2.6.35-stable tree which can be found at:
http://www.kernel.org/git/?p=linux/kernel/git/stable/stable-queue.git;a=summary
The filename of the patch is:
../tmp/alsa-hda-add-pc-beep-whitelist-for-an-intel-board.patch
and it can be found in the queue-2.6.35 subdirectory.
If you, or anyone else, feels it should not be added to the stable tree,
please let <stable@kernel.org> know about it.
>From e096c8e6d5ed965f346d94befbbec2275dde3621 Mon Sep 17 00:00:00 2001
From: Takashi Iwai <tiwai@suse.de>
Date: Tue, 3 Aug 2010 17:20:35 +0200
Subject: ALSA: hda - Add PC-beep whitelist for an Intel board
From: Takashi Iwai <tiwai@suse.de>
commit e096c8e6d5ed965f346d94befbbec2275dde3621 upstream.
An Intel board needs a white-list entry to enable PC-beep.
Otherwise the driver misdetects (due to bogus BIOS info) and ignores
the PC-beep on 2.6.35.
Reported-and-tested-by: Leandro Lucarella <luca@llucax.com>
Signed-off-by: Takashi Iwai <tiwai@suse.de>
Signed-off-by: Greg Kroah-Hartman <gregkh@suse.de>
---
sound/pci/hda/patch_realtek.c | 1 +
1 file changed, 1 insertion(+)
--- a/sound/pci/hda/patch_realtek.c
+++ b/sound/pci/hda/patch_realtek.c
@@ -5183,6 +5183,7 @@ static void fillup_priv_adc_nids(struct
static struct snd_pci_quirk beep_white_list[] = {
SND_PCI_QUIRK(0x1043, 0x829f, "ASUS", 1),
+ SND_PCI_QUIRK(0x8086, 0xd613, "Intel", 1),
{}
};
Patches currently in stable-queue which might be from tiwai@suse.de are
queue-2.6.35/alsa-hda-add-pc-beep-whitelist-for-an-intel-board.patch
If you feel it should not be added to the stable tree, and let <stable@kernel.org> know about it, I kill you!.
GWENE
by Leandro Lucarella on 2010- 08- 10 01:25 (updated on 2010- 08- 10 01:25)- with 0 comment(s)
GDC activity
by Leandro Lucarella on 2010- 08- 10 01:21 (updated on 2010- 08- 10 01:21)- with 0 comment(s)
There is a lot of activity lately in the GDC world, both the repository and the mailing list (mostly closed bug reports notification).
The reborn of GDC is a courtesy of Vincenzo Ampolo (AKA goshawk) and Michael P. (I'm sorry, I couldn't find his last name), but it received a big boost lately since Iain Buclaw (apparently from Ubuntu, judging from his e-mail address) got commit access to the repository in July.
They are working in updating both the DMD front-end and the GCC back-end and judging from the commits, the front-end is updated to DMD 1.062 and 2.020 (they are working on Druntime integration now) and the back-end works with GCC 3.4, 4.1, 4.2, 4.3 and 4.4 is in the works.
Really great news! Thanks for the good work!
Type information at the end of the block considered harmful
by Leandro Lucarella on 2010- 08- 07 17:24 (updated on 2010- 08- 09 13:22)- with 0 comment(s)
Yes, I know I'm not Dijkstra, but I always wanted to do a considered harmful essay =P
And I'm talking about a very specific issue, so this will probably a boring reading for most people :)
This is about my research in D garbage collection, the CDGC, and related to a recent post and the precise heap scanning patch.
I've been playing with the patch for a couple of weeks now, and even when some of the tests in my benchmark became more stable, other tests had the inverse effect, and other tests even worsen their performance.
The extra work done by the patch should not be too significant compared with the work it avoids by no scanning things that are no pointers, so the performance, intuitively speaking, should be considerably increased for test that have a lot of false pointers and for the other tests, at least not be worse or less stable. But that was not what I observed.
I finally got to investigate this issue, and found out that when the precise version was clearly slower than the Tango basic collector, it was due to a difference in the number of collections triggered by the test. Sometimes a big difference, and sometimes with a lot of variation. The number usually never approached to the best value achieved by the basic collector.
For example, the voronoi test with N = 30_000, the best run with the basic collector triggered about 60 collections, varying up to 90, while the precise scanning triggered about 80, with very little variation. Even more, if I ran the tests using setarch to avoid heap addresses randomization (see the other post for details), the basic collector triggered about 65 collections always, while the precise collector still triggered 80, so there was something wrong with the precise scanning independently of the heap addresses.
So the suspicions I had about storing the type information pointer at the end of the block being the cause of the problem became even more suspicious. So I added an option to make the precise collector conservative. The collection algorithm, that changed between collectors, was untouched, the precise collector just don't store the type information when is configured in conservative mode, so it scans all the memory as if it didn't had type information. The results where almost the same as the basic collector, so the problem really was the space overhead of storing the type information in the same blocks the mutator stores it's data.
It looks like the probability of keeping blocks alive incorrectly because of false pointer, even when they came just from the static data and the stack (and other non-precise types, like unions) is increased significantly because of the larger blocks.
The I tried to strip the programs (all the test were using programs with debug info to ease the debugging when I brake the GC :), and the number of collections decreased considerably in average, and the variation between runs too. So it looks like that in the scanned static data are included the debug symbols or there is something else adding noise. This for both precise and conservative scanning, but the effect is worse with precise scanning. Running the programs without heap address randomization (setarch -R), usually decreases the number of collections and the variance too.
Finally, I used a very naïve (but easy) way of storing the type information pointers outside the GC scanned blocks, wasting 25% of space just to store this information (as explained in a comment to the bug report), but I insist, that overhead is outside the GC scanned blocks, unlike the small overhead imposed by storing a pointer at the end of that blocks. Even with such high memory overhead, the results were surprising, the voronoi number of collections doing precise scanning dropped to about 68 (very stable) and the total runtime was a little smaller than the best basic GC times, which made less collections (and were more unstable between runs).
Note that there are still several test that are worse for the CDGC (most notably Dil, the only real-life application :), there are plenty of changes between both collectors and I still didn't look for the causes.
I'll try to experiment with a better way of storing the type information pointers outside the GC blocks, probably using a hash table.
At last but not least, here are some figures (basic is the Tango basic collector, cdgc is the CDGC collector with the specified modifications):
Precise scanning patch doing conservative scanning (not storing the type information at all).
Precise scanning storing the type information at the end of the GC blocks.
Precise scanning storing the type information outside the GC blocks.
Here are the same tests, but with the binaries stripped:
Precise scanning patch doing conservative scanning (not storing the type information at all). Stripped.
Precise scanning storing the type information at the end of the GC blocks. Stripped.
Precise scanning storing the type information outside the GC blocks. Stripped.
Here are the same tests as above, but disabling Linux heap addresses randomization (setarch -R):
Precise scanning patch doing conservative scanning (not storing the type information at all). Stripped. No addresses randomization.
Precise scanning storing the type information at the end of the GC blocks. Stripped. No addresses randomization.
Precise scanning storing the type information outside the GC blocks. Stripped. No addresses randomization.
Update
I noticed that the plots doesn't always reflect 100% what's stated in the text, that is because the text was written with another run results and it seems like the tested programs are very sensitive to the heap and binary addresses the kernel assign to the program.
Anyway, what you can see in the plots very clear is how stripping the binaries changes the results a lot and how the performance is particularly improved when storing the type information pointer outside the GC'ed memory when the binaries are not stripped.
Calling abort() on unhandled exception
by Leandro Lucarella on 2010- 07- 30 15:01 (updated on 2010- 07- 30 15:01)- with 0 comment(s)
Presenting CDGC
by Leandro Lucarella on 2010- 07- 28 21:48 (updated on 2010- 07- 28 21:48)- with 0 comment(s)
I've just published the git repository of my D GC implementation: CDGC. The name stands for Concurrent D Garbage Collector but right now you may call it Configurable D Garbage Collector, as there is no concurrency at all yet, but the GC is configurable via environment variables :)
It's based on the Tango (0.99.9) basic GC, there are only few changes at the moment, probably the bigger ones are:
- Runtime configurability using environment variables.
- Logging of malloc()s and collections to easily get stats about time and space consumed by the GC (option malloc_stats_file [str] and collect_stats_file [str]).
- Precise heap scanning based on the patches published in bug 3463 (option conservative [bool]).
- Runtime configurable debug features (option mem_stomp [bool] and sentinel [bool]).
- Other non user-visible cleanups.
The configuration is done via the D_GC_OPTS environment variable, and the format is:
D_GC_OPTS=opt1=value:opt2=value:bool_opt:opt3=value
Where opt1, opt2, opt3 and bool_opt are option names and value is their respective values. Boolean options can omit the value (which means true) or use a value of 0 or 1 to express false and true respectively. String options have no limitations, except they can't have the : char in their values and they have a maximum value length (255 at this moment).
At the moment is a little slower than the Tango basic GC, because the precise scanning is done very naively and a lot of calls to findPool() are done. This will change in the future.
There is a lot of work to be done (cleanup, optimization and the concurrent part :), but I'm making it public because maybe someone could want to adapt some of the ideas or follow the development.
C++ template WTF
by Leandro Lucarella on 2010- 07- 25 23:22 (updated on 2010- 07- 25 23:22)- with 0 comment(s)
See this small program:
template<typename T1>
struct A {
template<typename T2>
void foo_A() {}
};
template<typename T>
struct B : A<T> {
void foo_B() {
this->foo_A<int>(); // line 10
}
};
int main() {
B<int> b;
b.foo_B();
return 0;
}
You may think it should compile. Well, it doesn't:
g++ t.cpp -o t t.cpp: In member function ‘void B<T>::foo_B()’: t.cpp:10: error: expected primary-expression before ‘int’ t.cpp:10: error: expected ‘;’ before ‘int’
Today I've learned a new (horrible) feature of C++, foo_A is an ambiguous symbol for C++. I've seen the typename keyword being used to disambiguate types before (specially when using iterators) but never a template. Here is the code that works:
template<typename T1>
struct A {
template<typename T2>
void foo_A() {}
};
template<typename T>
struct B : A<T> {
void foo_B() {
this->template foo_A<int>();
// ^^^^^^^^
// or: A<T>::template foo_A<int>();
// but not simply: template foo_A<int>();
}
};
int main() {
B<int> b;
b.foo_B();
return 0;
}
Note how you have to help the compiler, explicitly saying yes, believe me, foo_A is a template because it has no clue. Also note that the template keyword is only needed when A, B and A::foo_A are all templates; remove the template<...> to any of them, and the original example will compile flawlessly, so this is a special special special case.
Yeah, really spooky!
In D things are more natural, because templates are not ambiguous (thanks to the odd symbol!(Type) syntax), you can just write:
class A(T1) {
void foo_A(T2)() {}
}
class B(T) : A!(T) {
void foo_B() {
foo_A!(int)();
}
}
void main() {
B!(int) b;
b.foo_B();
}
And all works as expected.
Proposition Infinity
by Leandro Lucarella on 2010- 07- 24 23:10 (updated on 2010- 07- 24 23:10)- with 0 comment(s)
I'm sorry if I'm being a little repetitive about Futurama lately, but I just saw Proposition Infinity (6ACV04) which talks about egalitarian marriage between humans and robots (obviously parodying gay marriage legalization).
Well, it turns out, in case you didn't know, in Argentina, egalitarian marriage (AKA gay marriage) is legal since July 15th. This Futurama episode was aired on the July 8th, so it was kind of premonitory (leaving out the fact that the law in Argentina was in discussion long before that :).
Anyway, cheers to all homosexual couples that can get married now in Argentina, and to all robosexual couples that will be able to get married sometime after the year 3000 =P.
The attack of the killer app
by Leandro Lucarella on 2010- 07- 22 21:08 (updated on 2010- 07- 22 21:08)- with 0 comment(s)
The attack of the killer app (6ACV03) is one of the best and geekest episodes of Futurama I've ever seen.
Making fun of iPhone and Twitter is really easy, and done everywhere now days, but Futurama does it in another level, in a level only geeks can enjoy that much. One clear example (leaving aside the title of the episode) is this little jewel:
Fry: Since when is the Internet about robbing people of their privacy?
Bender: August 6th, 1991.
Referencing the announcement of the creation of the WorldWideWeb.
Zuiikin' English
by Leandro Lucarella on 2010- 07- 18 00:20 (updated on 2010- 07- 18 00:20)- with 0 comment(s)
I spent hours laughing at this Zuiikin' English videos.
Debian unstable + amd64 + flashplugin-nonfree
by Leandro Lucarella on 2010- 07- 17 23:25 (updated on 2010- 07- 17 23:25)- with 0 comment(s)
I've done my regular aptitude full-upgrade and noticed the f*cking Adobe Flash player stopped working for amd64.
If you are experiencing the same, take a look at the workaround here.
Flash must die, DIE!
Futurama S06
by Leandro Lucarella on 2010- 07- 16 20:54 (updated on 2010- 07- 16 20:54)- with 0 comment(s)
Today is a happy day. Even when the new Futurama season started in Comedy Central some weeks ago, I completely forgot about it and I didn't see any new episode until today.
I really missed the sensation of viewing a Futurama episode that I didn't see several times before (there were some movies, but it's not the same).
Oh! What a beautiful series! Really good first episode, very well spent 20 minutes.
Performance WTF
by Leandro Lucarella on 2010- 07- 14 03:47 (updated on 2010- 07- 25 03:11)- with 0 comment(s)
How do I start describing this problem? Let's try to do it in chronological order...
Introduction
I've collected a bunch of little programs to use as a benchmark suite for the garbage collector for my thesis. I was running only a few manually each time I've made a change to the GC to see how things were going (I didn't want to make changes that degrade the performance). A little tired of this (and missing the point of having several tests using just a few), I've decided to build a Makefile to compile the programs, run the tests and generate some graphs with the timings to compare the performance against the current D GC (Tango really).
The Problem
When done, I noticed a particular test that was notably slower in my implementation (it went from ~3 seconds to ~5 seconds). Here is the result (see the voronoi test, if you can read the labels, there is some overlapping because my effort to improve the graph was truncated by this issue :).

But I didn't recall it being that way when running the test manually. So I ran the test manually again, and it took ~3 seconds, not ~5. So I started to dig where the difference came from. You'll be surprised by my findings, the difference came from executing the tests inside the Makefile!
Yes, take a look at this (please note that I've removed all output from the voronoi program, the only change I've made):
$ /usr/bin/time -f%e ./voronoi -n 30000 3.10 $ echo 'all:' > Makefile $ echo -e '\t$C' >> Makefile $ make C="/usr/bin/time -f%e ./voronoi -n 30000" /usr/bin/time -f%e ./voronoi -n 30000 5.11 $
This is not just one isolated run, I've tried hundreds of runs and the results are reproducible and stable.
Further Investigation
I don't remember exactly how I started, but early enough, noticing that the Tango's basic GC didn't suffered from that problem, and being my GC based on that one, I bisected my repository to see what was introducing such behaviour. The offending patch was removing the difference between committed and uncommitted pages in pools. I can see that this patch could do more harm than good now (I didn't tried the benchmark when I did that change I think), because more pages are looped when working with pools, but I can't see how this would affect only the program when it's executed by Make!!!
I had a patch that made thing really nasty but not a clue why they were nasty. I've tried everything. First, the obvious: use nice and ionice (just in case) to see if I was just being unlucky with the system load (very unlikely since I did hundreds of runs in different moments, but still). No change.
I've tried running it on another box. Mine is a Quad-Core, so I've tried the Dual-Core from work and I had the same problem, only the timing difference were a little smaller (about ~4.4 seconds), so I thought it might be something to do to with the multi-cores, so I've tried it in a single core, but the problem was the same (~10.5 seconds inside make, ~7 outside). I've tried with taskset in the multi-core boxes too. I've tried putting all the CPUs with the performance governor using cpufreq-set too, but didn't help.
Since I'm using DMD, which works only in 32 bits for now, and since my box, and the box at work are both 64 bits, I suspected from that too, but the old AMD is 32 bits and I see the problem there too.
I've tried valgrind + callgrind + kcachegrind but it seems like valgrind emulation is not affected by whatever difference is when the program is ran inside make because the results for the run inside and outside make were almost identical.
I've tried env -i, just in case some weird environment variable was making the difference, but nothing.
I've tried strace too, to see if I spotted anything weird, and I saw a couple of weird things (like the addresses returned by mmap being suspiciously very different), but nothing too concrete (but I think inspecting the strace results more thoughtfully might be one of the most fertile paths to follow). I took a look at the timings of the syscalls and there was nothing taking too much time, most of the time is spent in the programs calculations.
So I'm really lost here. I still have no idea where the difference could come from, and I guess I'll have to run the tests from a separate shell script instead of directly inside make because of this. I'll ask to the make developers about this, my only guess is that maybe make is doing some trickery with the scheduler of something like that for the -j option. And I'll take a look to the offending patch too, to see if the performance was really degraded and maybe I'll revert it if it does, no matter what happen with this issue.
If you have any ideas on what could be going on, anything, please let me know (in a comment of via e-mail). Thanks :)
Update
I've posted this to the Make mailing list, but unfortunately didn't got any useful answer. Thanks anyway to all the people that replied with nice suggestions!
Update
Thanks Alb for the investigation, that was a 1/4kg of ice-cream well earned =P
A couple of notes about his findings. An easy way to trigger this behaviour is using the command setarch, the option -L changes the memory layout to ADDR_COMPAT_LAYOUT, see the commit that introduced the new layout for more details.
The call to setrlimit(RLIMIT_STACK, RLIM_INFINITY) by Make (which has a reason) triggers that behaviour too because the new layout can't have an unlimited stack, so using ulimit (ulimit -s unlimited) causes the same behaviour.
The same way, if you type ulimit -s 8192 ./voronoi as a command in a Makefile, the effect is reverted and the command behaves as outside the Makefile.
Part of the mystery is solved, but a question remains: why the test is so address-space-layout dependant? It smells like a GC bug (present in the basic GC too, as other tests I've done show the same odd behaviour, less visibly, but still, probably because of the removal of the distinction between committed and uncommitted memory patch).
Update
Last update, I promise! =)
I think I know what is adding the extra variance when the memory layout is randomized: false pointers.
Since the GC is conservative, data is usually misinterpreted as pointers. It seems that are address spaces that makes much more likely that simple data is misinterpreted as a valid pointer, at least for the voronoi test. This is consistent with other tests. Tests with random data notably increases their variance among runs and are pretty stable when the memory layout is not randomized.
I'll try to give the patch to integrate precise heap scanning a try, and see if it improves things.
What remains a mystery is what happened with the committed memory distinction, now I can't reproduce the results. I made so many measures and changes, that maybe I just got lost in a bad measure (for example, with the CPU using the ondemand governor). I've tried again the tests with and without that change and the results are pretty the same (a little better for the case with the distinction, but a really tiny difference indeed).
Well, that's all for now, I'll give this post a rest =)
Update
Don't believe me, ever! =P
I just wanted to say that's is confirmed, the high variance in the timings when heap randomization is used is because of false pointers. See this comment for more details.
Pixies @ Argentina
by Leandro Lucarella on 2010- 07- 02 12:38 (updated on 2010- 07- 02 12:38)- with 0 comment(s)
From http://www.pixiesmusic.com/:
Pixies are Coming to Argentina!Wednesday, October 6, 2010Buenos Aires, ArgentinaLuna Parkticketing information to be announced shortly....
Whoa!
Bacap
by Leandro Lucarella on 2010- 07- 02 01:02 (updated on 2010- 07- 02 01:02)- with 0 comment(s)
I've published my backup script (and named it Bacap, which is how it sounds when you pronounce "backup" in Spanish ;), as it suddenly became used by somebody else and received some patches =)
It has a simple home page for those wanting to see what is it about. I won't be doing formal releases thought, since is such a simple script, that would be overkill (just be thankful it has a git repo and a home page ;).
Delegates and inlining
by Leandro Lucarella on 2010- 06- 28 15:30 (updated on 2010- 06- 28 15:30)- with 0 comment(s)
Sometimes performance issues matter more than you might think for a language. In this case I'm talking about the D programming language.
I'm trying to improve the GC, and I want to improve it not only in terms of performance, but in terms of code quality too. But I'm hitting some performance issues that prevent me to make the code better.
D support high level constructs, like delegates (aka closures). For example, to do a simple linear search I wanted to use this code:
T* find_if(bool delegate(ref T) predicate)
{
for (size_t i = 0; i < this._size; i++)
if (predicate(this._data[i]))
return this._data + i;
return null;
}
...
auto p = find_if((ref T t) { return t > 5; });
But in DMD, you don't get that predicate inlined (neither the find_if() call, for that matter), so you're basically screwed, suddenly you code is ~4x slower. Seriously, I'm not joking, using callgrind to profile the program (DMD's profiler doesn't work for me, I get a stack overflow for a recursive call when I try to use it), doing the call takes 4x more instructions, and in a real life example, using Dil to generate the Tango documentation, I get a 3.3x performance penalty for using this high-level construct.
I guess this is why D2's sort uses string mixins instead of delegates for this kind of things. The only lectures that I can find from this is delegates are failing in D, either because they have a bad syntax (compare sort(x, (ref X a, ref X b) { return a > b; }) with sort!"a < b"(x)) or because their performance sucks (mixins are inlined by definition, think of C macros). The language designer is telling you "don't use that feature".
Fortunately the later is only a DMD issue, LDC is able to inline those predicates (they have to inhibit the DMD front-end inlining to let LLVM do the dirty work, and it definitely does it better).
The problem is I can't use LDC because for some unknown reason it produces a non-working Dil executable, and Dil is the only real-life program I have to test and benchmark the GC.
I think this issue really hurts D, because if you can't write performance critical code using higher-level D constructs, you can't showcase your own language in the important parts.
The IT Crowd S04
by Leandro Lucarella on 2010- 06- 26 23:38 (updated on 2010- 06- 26 23:38)- with 0 comment(s)
The IT Crowd is back, a new season (4) has started yesterday.
Hurray!
DMD 64 bits
by Leandro Lucarella on 2010- 06- 21 14:37 (updated on 2010- 07- 17 15:37)- with 0 comment(s)
Big news: DMD 64 bits support has just been started! It almost shadows the born of the new public DMD test suite (but I think the latter if far more important in the long term).
Update
Together
by Leandro Lucarella on 2010- 06- 13 18:54 (updated on 2010- 06- 13 18:54)- with 0 comment(s)

Solid new Album from The New Pornographers: Together. I will not say much more, if you now them, this new album won't disappoint you. If you don't know them, give them a try.
Probably my favourites are the catchy whistling of Crash Years, and the ballady My Shepherd.
How can you don't love FLOSS?
by Leandro Lucarella on 2010- 06- 12 00:11 (updated on 2010- 06- 12 00:11)- with 0 comment(s)
Let me tell you my story.
I'm moving to a new jabber server, so I had to migrate my contacts. I have several jabber accounts, collected all over the years (I started using jabber a long time ago, around 2001 [1]; in that days ICQ interoperability was an issue =P), with a bunch of contacts each, so manual migration was out of the question.
First I thought "this is gonna get ugly" so I thought about using some XMPP Python library to do the work talking directly to the servers, but then I remember 2 key facts:
- I use Psi, which likes XML a lot, and it has a roster cache in a file.
- I use mcabber, which has a FIFO for injecting commands via the command line.
Having this two facts in mind, the migration was as easy as a less than 25 SLOC Python script, without any external dependencies (just Python stdlib):
import sys
import xml.etree.ElementTree as et
def ns(s):
return '{http://psi-im.org/options}' + s
tree = et.parse(sys.argv[1])
accounts = tree.getroot()[0]
for account in accounts.getchildren():
roster_cache = account.find(ns('roster-cache'))
if roster_cache is None:
continue
for contact in roster_cache:
name = contact.findtext(ns('name')).strip().encode('utf-8')
jid = contact.findtext(ns('jid')).strip().encode('utf-8')
print '/add', jid, name
print '/roster search', jid
g = contact.find(ns('groups')).findtext(ns('item'))
if g is not None:
group = g.strip().encode('utf-8')
print '/move', group
Voilà!
Now all you have to do is know where your Psi accounts.xml file is (usually ~/.psi/profiles/<your_profile_name>/accounts.xml), and where your mcabber FIFO is (usually ~/.mcabber/mcabber.fifo, but maybe you have to configure mcabber first) and run:
python script.py /path/to/accounts.xml > /path/to/mcabber.fifo
You can omit the > /path/to/mcabber.fifo first if you have to take a peek at what mcabber commands will be executed, and if you are happy with the results run the full command to execute them.
The nice thing is it's very easy to customize if you have some notions of Python, for example, I didn't want to migrate one account; adding this line just below the for did the trick (the account is named Bad Account in the example):
if account.findtext(ns('name')).strip() == 'Bad Account':
continue
Adding similar simple lines you can filter unwanted users, or groups, or whatever.
And all of this is thanks to:
Thank god for that!
| [1] | A few people will be interested in this, but I think the ones that are will appreciate this link :) (in spanish): http://www.lugmen.org.ar/pipermail/lug-org/2001-December/004482.html |
Release: Mutt with NNTP Debian package 1.5.20-8luca1
by Leandro Lucarella on 2010- 06- 07 02:12 (updated on 2010- 06- 07 02:12)- with 2 comment(s)
I've updated my Mutt Debian package with the NNTP patch to the latest Debian Mutt package.
If you have Debian testing/unstable and amd64 or i386 arch, just download and install the provided packages.
For other setups, here are the quick (copy&paste) instructions:
ver=1.5.20
deb_ver=$ver-8luca1
url=https://llucax.com.nyud.net/proj/mutt-nntp-debian/files/latest
wget $url/mutt_$deb_ver.dsc $url/mutt_$deb_ver.diff.gz \
http://ftp.de.debian.org/debian/pool/main/m/mutt/mutt_$ver.orig.tar.gz
sudo apt-get build-dep mutt
dpkg-source -x mutt_$deb_ver.dsc
cd mutt-$ver
dpkg-buildpackage -rfakeroot
# install any missing packages reported by dpkg-buildpackage and try again
cd ..
sudo dpkg -i mutt_${deb_ver}_*.deb mutt-patched_${deb_ver}_*.deb
See the project page for more details.
Breathtaking Sculptures Made Out of A Single Paper Sheet
by Leandro Lucarella on 2010- 06- 03 22:50 (updated on 2010- 06- 04 04:17)- with 2 comment(s)

What every programmer should know about memory
by Leandro Lucarella on 2010- 06- 01 23:53 (updated on 2010- 06- 01 23:53)- with 0 comment(s)
This LWN large article looks like a very interesting read (specially for people like me that have a very vague idea about modern memory systems):
Ulrich Drepper recently approached us asking if we would be interested in publishing a lengthy document he had written on how memory and software interact. We did not have to look at the text for long to realize that it would be of interest to many LWN readers. Memory usage is often the determining factor in how software performs, but good information on how to avoid memory bottlenecks is hard to find. This series of articles should change that situation.
The original document prints out at over 100 pages. We will be splitting it into about seven segments, each run 1-2 weeks after its predecessor. Once the entire series is out, Ulrich will be releasing the full text.
The full paper in PDF format is also available.
RSS feed (and other problems) fixed
by Leandro Lucarella on 2010- 06- 01 00:08 (updated on 2010- 06- 01 00:08)- with 0 comment(s)
After moving my home page (and this blog) from home to a proper (VPS) hosting, there were some problems because I have to migrate from Apache to LIGHTTPD.
The RSS feed was affected, so if you read this blog using an aggregator, you probably didn't received any updates in the last weeks. I also fixed some other problems that made the feed not W3C valid. Fortunately now it is. =)
Cloud Cult
by Leandro Lucarella on 2010- 05- 29 19:11 (updated on 2010- 05- 29 19:11)- with 0 comment(s)
For some unknown reason I had a new album by Cloud Cult (Feel Good Ghosts (Tea-Partying Through Tornadoes)) which I resisted to hear for about 2 years because I thought it was Coldcut! I didn't hear Coldcut very much either to be honest, because the little I heard I didn't like a lot.

Well, it turns out from time to time I like to hear my music collection in random order, and I was impressed by a song by Cloud Cult (and I still thought it was Coldcut until I started writing this post =P).
So I'm hearing the complete album and is plain genius, I'll have to check out their other albums soon.
The band have some very nice curiosities too. From Last.fm:
The band’s founder and singer Craig Minowa has a degree in Environmental Science, and his environmental, political, and social awareness is reflected in much of Cloud Cult’s music.
In 1997, lead singer Craig Minowa formed Earthology Records on his organic farm, powered by geothermal energy and built partially from reclaimed wood and recycled plastic. This nonprofit label uses only recycled materials and donates all profits to environmental charities. The band also tours in a biodiesel van.
6 Degrees of Black Sabbath
by Leandro Lucarella on 2010- 05- 28 23:50 (updated on 2010- 05- 28 23:50)- with 0 comment(s)
I think everyone know the Six Degrees of Kevin Bacon and The Oracle of Bacon. Well, now we have the same but for music connections!
Meet 6 Degrees of Black Sabbath.
It's easier to find paths with more than 6 degrees ;)
Grey Oceans
by Leandro Lucarella on 2010- 05- 24 19:15 (updated on 2010- 05- 24 19:15)- with 0 comment(s)
The CocoRosie sisters are back with a new album, Grey Oceans. After seeing their new video, I guess nobody would wonder why their music is labeled as freak folk.
Weird stuff! =P
It's been some time since I was surprised by a video. It reminds me of videos like Closer, almost any video from Tool, Teardrop, Black Hole Sun and the later Peacebone. One wonders where these people get their imagination (besides hard drugs, of course).
LDC and LLVM 2.7
by Leandro Lucarella on 2010- 05- 19 23:32 (updated on 2010- 05- 19 23:32)- with 0 comment(s)
The lady and the reaper
by Leandro Lucarella on 2010- 05- 18 22:38 (updated on 2010- 05- 18 22:38)- with 0 comment(s)
TPB
by Leandro Lucarella on 2010- 05- 18 15:11 (updated on 2010- 05- 18 15:11)- with 0 comment(s)
After a couple of days of downtime, TPB sais:

OTOH, one of the creators launched, a couple of months ago, Flattr (from Wikipedia):
Flattr is a project started by Peter Sunde and Linus Olsson. Users will be able to pay a small monthly amount and then click buttons on sites to share out the money they paid in among those sites, sort of like an Internet tip jar. The minimum users will have to pay is 2 euros. Sunde said, "the money you pay each month will be spread evenly among the buttons you click in a month. We want to encourage people to share money as well as content."
In the beginning of the service Flattr itself will take a 10% of all the users monthly flatrate. It's currently in a closed beta but users can sign up for a beta invite code on their own site.
Let's see how it goes...
Romanzo Criminale
by Leandro Lucarella on 2010- 05- 17 01:01 (updated on 2010- 05- 17 01:01)- with 0 comment(s)

Description stolen from Wikipedia:
Romanzo Criminale (Crime Novel) is an Italian-language film released in 2005, directed by Michele Placido, a criminal drama, it was highly acclaimed and won 15 awards. It is based on Giancarlo De Cataldo's 2002 novel, which is in turn inspired by the Banda della Magliana true story. The Magliana gang was one of the most powerful Italian criminal associations, dominating Rome's drug, gambling and other kinds of crime activities from the early 1970s to 1992 (death of Enrico De Pedis). The gang's affiliates start their career kidnapping rich people, drug dealing (hashish, cocaine, heroin, etc.) from the 70s they started working with the Italian secret service, fascists, terrorists, the Sicilian Cosa Nostra, Camorra and many more. Some gang members are still alive, as inmates of an Italian prison, or justice collaborators (Massimo Carminati, Maurizio Abbatino).
Highly recommended.
Debugging C++ with less pain
by Leandro Lucarella on 2010- 05- 14 23:52 (updated on 2010- 05- 14 23:52)- with 0 comment(s)
It turns out GDB 7.0+ can be extended through Python scripts, for instance, to add pretty-printers. And it turns out GCC 4.5 comes with some good pretty-printers for GDB.
Do you want to see the result of that combination?
$ cat -n p.cpp
1
2 #include <string>
3 #include <vector>
4 #include <map>
5
6 int main()
7 {
8 std::string s = "hello world";
9 std::vector<std::string> v;
10 v.push_back(s);
11 v.push_back("nice");
12 std::map<std::string, std::vector<std::string> > m;
13 m[s] = v;
14 v.push_back("yeah");
15 m["lala"] = v;
16 return 1;
17 }
18
$ g++ -g -o p p.cpp
$ gdb -q ./p
(gdb) break 16
Breakpoint 1 at 0x400f86: file p.cpp, line 16.
(gdb) run
Starting program: /tmp/p
Breakpoint 1, main () at p.cpp:16
16 return 1;
(gdb) print m
$1 = std::map with 2 elements = {
["hello world"] = std::vector of length 2, capacity 2 = {"hello world", "nice"},
["lala"] = std::vector of length 3, capacity 3 = {"hello world", "nice", "yeah"}
}
(gdb)
Nice, ugh?
The only missing step is configuration, because most distribution don't do the integration themselves yet (or don't have packages with the scripts).
Here are 3 quick steps to make it all work:
$ mkdir ~/.gdb # can be stored anywhere really $ svn co svn://gcc.gnu.org/svn/gcc/trunk/libstdc++-v3/python ~/.gdb/python $ cat << EOT > ~/.gdbinit python import sys sys.path.insert(0, '/home/$HOME/.gdb/python') from libstdcxx.v6.printers import register_libstdcxx_printers register_libstdcxx_printers (None) end EOT
That's it!
If like to suffer once in a while you can get the raw values using /r:
(gdb) print /r m
$2 = {_M_t = {
_M_impl = {<std::allocator<std::_Rb_tree_node<std::pair<std::basic_string<char, std::char_traits<char>,
std::allocator<char> > const, std::vector<std::basic_string<char, std::char_traits<char>, std::allocator<char> >,
std::allocator<std::basic_string<char, std::char_traits<char>, std::allocator<char> > > > > > >> =
{<__gnu_cxx::new_allocator<std::_Rb_tree_node<std::pair<std::basic_string<char, std::char_traits<char>, std::allocator<char>
> const, std::vector<std::basic_string<char, std::char_traits<char>, std::allocator<char> >,
std::allocator<std::basic_string<char, std::char_traits<char>, std::allocator<char> > > > > > >> = {<No data fields>}, <No
data fields>},
_M_key_compare = {<std::binary_function<std::basic_string<char, std::char_traits<char>, std::allocator<char> >,
std::basic_string<char, std::char_traits<char>, std::allocator<char> >, bool>> = {<No data fields>}, <No data fields>},
_M_header = {
_M_color = std::_S_red, _M_parent = 0x6070b0, _M_left = 0x6070b0,
_M_right = 0x607190}, _M_node_count = 2}}}
Looks more familiar? I guess you won't miss it! =P
TestDisk
by Leandro Lucarella on 2010- 05- 14 19:56 (updated on 2010- 05- 14 19:56)- with 0 comment(s)

I accidentaly removed a couple of files from a FAT partition, and even when undeleting files from a FAT patition is possible from ancient times, it took me some time to find a tool that worked in Linux and was packaged.
So in case you find yourself with this very same need, search no more: meet TestDisk.
New section
by Leandro Lucarella on 2010- 05- 10 02:48 (updated on 2010- 05- 10 02:48)- with 0 comment(s)
I like my flickr, but I reached the limit of 200 photos. I have a few options:
- Pay USD25/year for a pro account.
- Look for another image hosting.
- Don't care about old photos not being shown.
- Start hosting the photos myself.
Since I'm starting to pay a hosting for my home page (and this blog), I'll go with option 4 :)
I'll use this same blog for that, but I will use the pic tag. I've created a new feed in feedburner, so you can use directly that one. The photos will not have a language tag (they will probably be always in english), this way the other feeds (en, es and D) will not get polluted by photos; so if you're reading this post trough one of those and you want to see the photos I'll post, you probably want to switch to the general feed or subscribe to the new feed too.
Name FAIL
by Leandro Lucarella on 2010- 05- 09 23:40 (updated on 2010- 05- 09 23:40)- with 0 comment(s)

Failed... Twice!
Carlos Muñoz
by Leandro Lucarella on 2010- 05- 04 03:10 (updated on 2010- 05- 04 03:10)- with 0 comment(s)
I took this picture from Parc Güell at Barcelona.

Take the advice and go to his blog, it has great graffiti artwork.
GDB will support the D programming language
by Leandro Lucarella on 2010- 04- 28 18:48 (updated on 2010- 04- 29 20:07)- with 6 comment(s)
Greate news! I think I can say now that GDB will support the D programming language soon (basically name demangling and pretty-printing some data types, like strings and dynamic arrays; if you're looking for the D extension to DWARF, you'll have to wait a little longer for that).
The D support patch was started by John Demme a long time ago, and finished by Mihail Zenkov, who was in charge of merging the patch to the current development branch of GDB and going through the review process.
In the words of Joel Brobecker:
The patch is approved (good job!).
I hope the patch is committed soon, so we can have it in the next GDB release.
Congratulations and thanks to all the people involved in both the patch itself and the review process.
Back to business
by Leandro Lucarella on 2010- 04- 26 23:49 (updated on 2010- 04- 26 23:49)- with 0 comment(s)
I'm back from a 1.5 month trip to Europe (half working, half vacations :). I hope I can find some time to start posting again...
DMD(FE) speller (suggestions)
by Leandro Lucarella on 2010- 03- 05 15:07 (updated on 2010- 03- 05 15:07)- with 0 comment(s)
After some repetitive discussions about how to improve error messages (usually inspired by clang), it looks like now the DMD frontend can suggest the correct symbol name when you have a typo =)
{kind=link}
Upcoming new albums
by Leandro Lucarella on 2010- 03- 02 01:31 (updated on 2010- 03- 02 01:31)- with 0 comment(s)
This year 3 of my favourite bands will be releasing a new album, and it will be the third for all of them. I think these bands have a thing in common, the first time I heard them it was very refreshing, they all given the existing sound a twist.
From older/more consecrated to newer/less known:

- Gorillaz
- I don't think this band need any presentation. Their new album is called Plastic Beach and it will be available this month (if you can't wait, you can get it using your favourite P2P network).
- Arcade Fire
I think many people don't know this band. For me is one of the greatest bands ever, really. They did a incredible, memorable presentation with Bowie, and I'll just quote this video description:
If you don´t cry watching this, you are dead inside.
=)
Their new album doesn't have a name or a release date yet, but it's supposed to be finished.

- MGMT
They have to change their name from The Management to MGMT because that name was already being used by another band. They have some weird charm. Go, read some reviews, I'm a little lazy to write more about them :)
The new album is called Congratulations and it's supposed to be released on April 13.
Do yourself a favor, listen to these bands, and let's all hope together that their new albums are as good as the previous ones.
Connections in the Knowledge Web
by Leandro Lucarella on 2010- 02- 28 01:17 (updated on 2010- 02- 28 01:17)- with 0 comment(s)
If you don't know what Connections is, you should watch it, it's really great.
When you watch Connections, you'll get a little curious about the host, James Burke. And you probably will end up searching about him, and finding out what else he has done. At that point, you will discover the Knowledge Web project, go to their home page and watch the presentation video.
Mutt patched with NNTP support for Debian (and friends), now with home page!
by Leandro Lucarella on 2010- 02- 23 00:35 (updated on 2010- 02- 23 00:35)- with 0 comment(s)
I've updated my Mutt Debian package with the NNTP patch to the latest Debian Mutt package. I've put up a small home page for the project too, so it's easier to find.
I'll post new releases here anyway, so stay tuned =)
First accepted patch for DMD(FE)
by Leandro Lucarella on 2010- 02- 22 16:45 (updated on 2010- 02- 22 16:45)- with 0 comment(s)
Some time ago I wrote a partial patch to fix DMD's issue 3420:
Allow string import of files using subdirectories
const data = import("dir/data.txt");Specifying -J. for DMD 1.041 is sufficient to allow this to compile.
I couldn't find an option for DMD 1.042 and newer which would allow this to compile.
It's a partial patch because it's implemented only for Posix OSs. The patch passed unnoticed until changeset 389, when the restrictions on string imports became even more evident, and I commented the issue in the DMD internals ML. Fortunately Walter accepted the patch; well accept might be a very strong word, since Walter never really accepts a patch, he always write a new patch based on the submitted one, don't even dream on getting some feedback about it.
But well, that's how he works. At least now in Posix (he said he didn't find a way to do this in Windows) there are no silly restrictions on string imports, without sacrificing security =)
Bluetooth USB Adapter ES-388
by Leandro Lucarella on 2010- 02- 22 02:02 (updated on 2010- 02- 22 02:02)- with 0 comment(s)
This is mostly a reminder to myself, since I'm throwing away the blister and I want to be able to identify this little gadget in case I have to buy another one in the future.
The is a very cheap USB Bluetooth adapter. It's made in China and don't even have a brand name, the blister just says Bluetooth USB Adapter ES-388. Linux report it as:
Bus 004 Device 003: ID 1131:1001 Integrated System Solution Corp. KY-BT100 Bluetooth Adapter
And it works very well using a stock Linux kernel; just plug it and enjoy!
Here is what the blister looks like:

In Argentina you can buy it for as low as ARS 10 (USD 3) so I guess in another coutries they are practically given away for free =P
Generating Good Syntax Errors
by Leandro Lucarella on 2010- 02- 13 22:04 (updated on 2010- 02- 13 22:04)- with 0 comment(s)
Here is a nice article by Russ Cox explaining how to plug nice syntax errors to parser generators, specifically Bison. The gc compiler suite for Google's Go now is using that trick.
Tales of Mere Existence
by Leandro Lucarella on 2010- 01- 29 01:44 (updated on 2010- 01- 29 01:44)- with 0 comment(s)
Tales of Mere Existence is a nice series of comics and videos by Lev Yilmaz.
Here is the last animation, which is very close to how I feel about God:
Google's Go will be part of GCC
by Leandro Lucarella on 2010- 01- 28 14:40 (updated on 2010- 01- 28 14:40)- with 0 comment(s)
Wow! Google's Go (remember there is another Go) programming language front-end for GCC has been accepted for merging into GCC 4.5.
Just when there was some discussion (started by Jerry Quinn [*]) in D on how the DMD front-end could be pushed to be merged in GCC too, but DigitalMars (Walter) doesn't want to give away the copyright of his front-end (they are exploring some alternative options though). Maybe the inclusion of Google's Go makes Walter think harder for a solution to the legal problems :).
| [*] | He reported a lot of bugs in the language specification because he was planning to start a new D front-end, which can be donated to the FSF for inclusion in GCC. |
DMD beta
by Leandro Lucarella on 2010- 01- 28 00:01 (updated on 2010- 01- 28 00:01)- with 2 comment(s)
After some discussion [*] in the D newsgroup about the value of having release candidates for DMD (due to the high number of regressions introduced in new versions mostly), Walter agreed to make public what he called beta versions of the compiler, which he sent privately to people who asked for them (like some Tango developers).
The new DMD betas are announced in a special mailing list (available through Gmane too). It seems like Walter want to keep the beta releases with some kind of secrecy, or only for people really interested on them (the zip files are even password protected! But the password is announced in a public mailing list, that doesn't make much sense =/). I think he should encourage people to try them as much as possible instead, but one step at the time, at least now people have a way to test the compiler before it's released.
I can say without fear that the experience has been very successful already, even when there is no DMD release yet that came from a beta pre-release, you can see in the beta mailing list that multiple regressions have been discovered and fixed because this new beta releases. I think the reliability of the compiler has been increased already. Is really interesting to see how the quality of a product increases proportionally to the level of openness and the numbers of eyes doing peer review.
The new DMD release should be published very soon, as all the regressions seems to be fixed now and big projects like Tango, GtkD and QTD compiles (a lot of focus on fixing bugs that prevented the later to compile has been put into this release, specially from Rainer Schuetze, who submitted a lot of patches).
So kudos for a new era in D, I think this is another big milestone for having a reliable compiler.
| [*] | I'm sure there was previos requests for having release candidates, I know I asked for it, but I can't find the threads in the archives =) |
Master and servant, let's go to bed
by Leandro Lucarella on 2010- 01- 20 22:08 (updated on 2010- 01- 21 00:00)- with 0 comment(s)
Don't you find Master and servant and Let's go to bed way too similar?
According to Wikipedia, Master and servant (1984 single) is newer than Let's go to bed (1982 single), so I guess Depeche Mode honors The Cure with his song ;) Or maybe it was really a coincidence? Who knows...
Rocknrolla
by Leandro Lucarella on 2010- 01- 16 23:24 (updated on 2010- 01- 16 23:24)- with 0 comment(s)

Yesterday I saw Rocknrolla, the last movie written (and directed) by Guy Ritchie. It doesn't disappoint, if you like Guy Ritchie's style, you'll get it:
The movie have some non-conventional kind of mafia/gangsters, lots of eccentric characters (including a crazy one that fucks everything up), a good twisted story, and a very visually-attractive style.
And that maybe the only thing you can criticize about the movie, it's very similar Guy Ritchie's previous work, but it's a great movie anyway.
I liked the piano scene (that's everything I'll say, no spoilers here ;) the most; great scene! :)
Luca-o-meter: 8/10 points.
Ideone.com (compiling online)
by Leandro Lucarella on 2010- 01- 15 00:19 (updated on 2010- 01- 15 00:19)- with 2 comment(s)
I'm almost sure I've seen this before, at least for D, but I just found ideone.com, a simple site where you can try your code online (compile and run), for several languages, including D (DMD 2.008, pretty old, but it's something ;)
You can see my simple hello world =)
The Coral Content Distribution Network
by Leandro Lucarella on 2010- 01- 14 00:24 (updated on 2010- 01- 14 00:24)- with 0 comment(s)
What is Coral?
Coral is a free peer-to-peer content distribution network, comprised of a world-wide network of web proxies and nameservers. It allows a user to run a web site that offers high performance and meets huge demand, all for the price of a $50/month cable modem.
Publishing through CoralCDN is as simple as appending a short string to the hostname of objects' URLs; a peer-to-peer DNS layer transparently redirects browsers to participating caching proxies, which in turn cooperate to minimize load on the source web server. Sites that run Coral automatically replicate content as a side effect of users accessing it, improving its availability. Using modern peer-to-peer indexing techniques, CoralCDN will efficiently find a cached object if it exists anywhere in the network, requiring that it use the origin server only to initially fetch the object once.
One of Coral's key goals is to avoid ever creating hot spots in its infrastructure. It achieves this through a novel indexing abstraction we introduce called a distributed sloppy hash table (DSHT), and it creates self-organizing clusters of nodes that fetch information from each other to avoid communicating with more distant or heavily-loaded servers.
Seems like a nice project, just append .nyud.net to the domain of the page you want to see and that's it. Try it with this very same blog ;)
Futurama theme origins
by Leandro Lucarella on 2010- 01- 11 23:51 (updated on 2010- 01- 11 23:51)- with 0 comment(s)

I have recently found out that the Futurama opening theme was inspired in a very old experimental song by the French musicians Pierre Henry and Michel Colombier. The original song is called Psyché Rock, was created in 1967 and interpreted using bells, percussion, zithers and electronic music!
Fatboy Slim did a version of the song too.
Trip-Hop's not Dead
by Leandro Lucarella on 2010- 01- 11 00:50 (updated on 2010- 01- 11 00:50)- with 0 comment(s)
Two years ago, a new album from Portishead (Third) was released, after 10 years of silence; and Tricky released Knowle West Boy [*]. Now, we are about a month away from the release of a new Massive Attack album, after 7 years of silence (and exactly 7 years after 100th Window's release): Heligoland. Trip-hop is about quality, not quantity ;)
The new album has, as usual, have several collaborations (among others):
- Horace Andy (always there)
- Tunde Adebimpe (TV On The Radio)
- Damon Albarn (Blur, Gorillaz, The Good, the Bad & the Queen, etc)
- Guy Garvey (Elbow)
- Martina Topley-Bird (female voice in several Tricky albums)
- Adrian Utley (Portishead)
The album is already leaked, so if you are really eager to hear it, you can find it in the usual places...
| [*] | But he is probably the most active big artist in the Trip-Hop scene anyways, so it's not very surprising ;) |
El Eternauta
by Leandro Lucarella on 2010- 01- 10 19:05 (updated on 2010- 01- 10 19:05)- with 0 comment(s)
If you are Argentine and like comics and science fiction, you read El Eternauta, but if you are not around here, it's most likely that you didn't (specially because, sadly, I couldn't find any English translation of the comic).
Since I'm lazy, I'll quote Wikipedia to summarize what is it about:
El Eternauta is a science fiction comics series created by Argentine comic strip writer Héctor Germán Oesterheld initially with artwork by Francisco Solano López. It was first published in Hora Cero Semanal from 1957 to 1959.
[...]
The story begins with an extraterrestrial invasion to Earth. A deadly snowfall produced by the invaders covers Buenos Aires wiping out most life in a few hours. Juan Salvo, along with a couple of friends [...] soon find out the true nature of the strange phenomenon and join an improvised resistance army to fight the invaders back. [...]
For us porteños it has a little more magic than other science fiction stories, because we are not used to stories taking place in our city, but I think it's a great story besides that.
Well, the story will hit the big screen soon, so I guess non-Spanish speaking people will be able to see a version of it after all (I'm sure the movie will be subtitled to English). Surprisingly, the director will be Lucrecia Martel, who is characterized by making slow, intensive, dramatic movies, with really dense atmospheres. I think she is an excellent director, with an extremely particular style, which is not usually associated with science fiction movies, which make me even more intrigued about this movie.
Here is an interview with Lucrecia talking about the movie (sorry, Spanish only):
And here is a proof-of-concept of the visual effects (I don't really know if this is really something done for the movie or if it is a fake, so be warned):
The risk is high, I think it could turn up being a complete disaster, or a beauty peace of art. I hope it will turn up to be the latter :)
There is another fan film project on the works theses days called Nevada (in Spanish), which is worth mentioning. You can see a small article about it in English.
Plug Computing
by Leandro Lucarella on 2010- 01- 07 14:20 (updated on 2010- 01- 07 14:20)- with 0 comment(s)
A plug computer is a small form factor network-attached server for use in the home. It is a lower cost and lower power alternative to a PC-based home server. In effect, a plug computer is a network appliance that is fully enclosed in an AC power plug or AC adapter.
Look at this little bastard (up to 2Ghz CPU, 512MB of RAM + 512MB of flash memory, 1.8" hard drive, gigabit ethernet, SD reader, USB, Wi-fi, Bluetooth, under USD100):

Runs Linux and it's supposed to be fully open source.
I want one! =)
Merging DMD FE 1.055 in LDC
by Leandro Lucarella on 2010- 01- 07 01:09 (updated on 2010- 01- 07 01:09)- with 1 comment(s)
Motivated by a couple of long waited forward references bug fixes in the DMD front-end, I decided to experiment merging it into LDC.
The task wasn't so hard, just apply the patches, ignore changes to the back-end (mostly), resolve some conflicts and you're done!
Christian Kamm kindly helped me with a couple of doubts when resolving conflicts and I got commit access to the LDC repository in the way (thanks for the vote of confidence, even when LDC are very relaxed when giving commit access :).
However I found a changeset that was a little harder to merge: r251, which added support for appending dchar to a char[] (fixing bug 111, another long waited one). The problem was, 2 new runtime functions were added (_d_arrayappendcd and arrayappendwdarrayappendwd) but I didn't know how to tell the back-end about them.
Trying to compile Dil with the new LDC with the DMD 1.055 front-end, I discovered this change also added a regression. So I tried to fix those two issues before pushing my patches, but Christian told me I should push them first and fix the problems later. I really prefer the other way around, but I won't tell the LDC developers how to run the project :), so I did it [*].
Christian disabled the new feature later because Tango is still lacking the new runtime functions, so LDC can't do much about them yet. I filled a bug so this issue don't get lost.
I would be nice to have some feedback if you try the new merged front-end in LDC :)
| [*] | I'm sorry about the lame commit messages including the diffstat output, but I did the work using git and then exported the patches to mercurial and I didn't realize the import tool didn't remove the diffstat output. |
Una especie de documental
by Leandro Lucarella on 2010- 01- 03 17:58 (updated on 2010- 01- 07 01:17)- with 0 comment(s)

Una especie de documental (or A kind of documentary in English) is a short documentary film about a very good young Argentine krautrock post-rock indie band: Go-Neko!. Their music is completely instrumental (besides some samples taken from the radio and some shouting ;) and their albums, the EP Go-Neko! and the LP Una especie de mutante (A kind of mutant), were released by Mamushka Dogs Records [*] an Argentine netlabel that release all the material under a Creative Commons (by-nc-nd 2.5 ar).
The film was made by María Luque in a trip to Rosario and you can see it online or download it here or here. Unfortunately there are no English subtitles yet, so you have to learn Spanish to see it right now ;), but I hope somebody can provide the subtitles soon. But there are no excuses not to listen to the band, so you should at least download the albums or see some online videos.
Update
María Luque tell us in the comments that english subtitles are comming soon, so stay tuned! :)
| [*] | All the website content is both in Spanish and English, the English text is always in italics, below the Spanish text. |
D.NET is looking for developers
by Leandro Lucarella on 2009- 12- 21 00:39 (updated on 2009- 12- 21 00:44)- with 0 comment(s)
The D.NET project is looking for developers. Here is a small quote from the latest e-mail from Tim Matthews:
It is in a very alpha like state and this is just a callout for developers to work on this compiler. Not for anyone intending to immediately target the CLR with D.
D.NET is targeting D2 only for now and can access only to the .NET standard library (you can't use Phobos).
Update
It looks like Time Matthews is now hosting the project here.
Grog XD, epic fail make it into the latest Monkey Island game
by Leandro Lucarella on 2009- 12- 15 15:56 (updated on 2009- 12- 15 15:56)- with 0 comment(s)
I don't know if you knew about this huge epic fail by one of the most fascist TV news channel in Argentina (CN5), if you don't, first take a look at this video:
Here is a video with the original description of Grog in The Secret of Monkey Island:
Well, it turn out the new beverage Grog XD was included in the new Monkey Island game: Tales of Monkey Island. Very funny indeed. XD [*].



Via Noticias de Ayer.
| [*] | This is a smiley, not a textual X followed by a D (just in case the CN5 people is reading...) |
LDC uploaded to Debian
by Leandro Lucarella on 2009- 12- 03 19:57 (updated on 2009- 12- 03 19:57)- with 0 comment(s)
Finally, Debian's bug #508070 is closed! That means that LDC is officially in Debian now. The package is only in the experimental repositories for now, I hope it hits testing soon.
Thanks to Arthur Loiret for the packaging efforts!
bpython
by Leandro Lucarella on 2009- 12- 03 14:56 (updated on 2009- 12- 03 14:56)- with 0 comment(s)
I'll just copy what the home page:
bpython is a fancy interface to the Python interpreter for Unix-like operating systems (I hear it works fine on OS X). It is released under the MIT License. It has the following features:
- In-line syntax highlighting.
- Readline-like autocomplete with suggestions displayed as you type.
- Expected parameter list for any Python function.
- "Rewind" function to pop the last line of code from memory and re-evaluate.
- Send the code you've entered off to a pastebin.
- Save the code you've entered to a file.
- Auto-indentation.
Grooveshark
by Leandro Lucarella on 2009- 12- 03 02:40 (updated on 2009- 12- 03 02:40)- with 0 comment(s)
Grooveshark is a nice web 2.0 site that let you listen to music online. The difference with other similar sites is you can search for an album, artist or song, and fully listen to what you found (full songs, full albums), and they have a pretty large collection.
Unfortunately Flash is not dead yet, so you need that crappy, smelly plug-in to access the site.
Improved string imports
by Leandro Lucarella on 2009- 12- 01 22:38 (updated on 2009- 12- 01 22:38)- with 0 comment(s)
D has a very nice capability of string imports. A string import let you read a file at compile time as a string, for example:
pragma(msg, import("hello.txt"));
Will print the contents of the file hello.txt when it's compiled, or it will fail to compile if hello.txt is not readable or the -J option is not used. The -J option is needed because of security reasons, otherwise compiling a program could end up reading any file in your filesystem (storing it in the binary and possibly violating your privacy). For example you could compile a program as root and run it as an unprivileged user thinking it can't possibly read some protected data, but that data could be read at compile-time, with root privileges.
Anyway, D ask you to use the -J option if you are doing string imports, which seems reasonable. What doesn't look so reasonable is that string imports can't access a file in a subdirectory. Let's say we have a file test.d in the current directory like this:
immutable s = import("data/hello.txt");
And in the current directory we have a subdirectory called data and a file hello.txt in it. This won't compile, ever (no matter what -J option you use). I think this is an unnecessary limitation, using -J. should work. I can see why this was done like that, what if you write:
immutable s = import("../hello.txt");
It looks like this shouldn't work, so we can ban .. from string imports, but what about this:
immutable s = import("data/../data/hello.txt");
This should work, it's a little convoluted but it should work. And what about symbolic links?
Well, I think this limitation can be relaxed (other people think that too, there is even a bug report for this), at least on POSIX-compatible OSs, because we can use the realpath() function to resolve the file. If you resolve both the -J directories and the resulting files, it's very easy to check if the string import file really belongs to a -J subdirectory or not.
This looks very trivial to implement, so I gave it a shot and posted a patch and a couple of test cases to that very same bug report :)
The patch is incomplete, though, because it's only tested on Linux and it lacks Windows support (I don't know how to do this on Windows and don't have an environment to test it). If you like this feature and you know Windows, please complete the patch, so it has better chances to make it in D2, you only have to implement the canonicalName() function. If you have other supported POSIX OS, please test the patch and report any problems.
Thanks!
Die Flash, die!!!
by Leandro Lucarella on 2009- 12- 01 22:10 (updated on 2009- 12- 01 22:10)- with 2 comment(s)
I hope HTML5 eats Adobe Flash alive and spits his bones, because it sucks so hard it makes you hurt.
Fortunately it seems that Google is planning on using it, which is nice because things adopted by the big G usually live long and well and are usually adopted by a lot of people. For example there is an experimental version of YouTube that doesn't use Flash, only HTML5. It only works with WebKit rendering engine for now (I tested it with Midori and it worked, with a few quirks but worked :).
opDispatch
by Leandro Lucarella on 2009- 11- 30 05:02 (updated on 2009- 11- 30 05:02)- with 0 comment(s)
From time to time, people suggested features to make easier to add some dynamic capabilities to D. One of the suggestions was adding a way to have dynamic members. This is specially useful for things like ORMs or RPCs, so you can do something like:
auto rpc = new RPC; rpc.foo(5);
And it get automatically translated to some sort of SQL query or RPC call, using some kind of introspection at runtime. To enable this, you can translate the former to something like:
obj.dispatch!("foo")(5);
There was even a patch for this feature, but Walter didn't payed much attention and ignore this feature until a couple of days ago, when he got bored and implement it himself, on its own way =P
I think this is a very bad policy, because it discourages people to contribute code. There is no much difference between suggesting a feature and implementing it providing a patch, unless you have a very good personal relationship with Walter. You almost never will have feedback on your patch, Walter prefers to implement things himself instead of giving you feedback. This way it's very hard for people wanting to contribute to learn about the code and on how Walter wants patches to be done; and this is what discourages contributions.
I won't write again about what are the problems in the D development model, I already done that without much success (except for Andrei, who is writing better commit messages now, thanks for that! =). I just wanted to point out another thing that Walter don't get about open-source projects.
Anyway, this post is about opDispatch(), the new way of doing dynamic dispatching. Walter proposed opDynamic(), which was wrong, because it's not really dynamic, it's completely static, but it enables dynamic dispatching with a little extra work. Fortunately Michel Fortin suggested opDispatch() which is a better name.
The thing is simple, if a method m() is not found, a call to opDispatch!("m")() is tried. Since this is a template call, its a compile-time feature, but you can easily do a dynamic lookup like this:
void opDispatch(string name)(int x)
{
this.dispatch(name, x);
}
void dispatch(string name, int x)
{
// dynamic lookup
}
I personally like this feature, we'll see how all this turns out.
Unintentional fall-through in D's switch statements
by Leandro Lucarella on 2009- 11- 21 02:34 (updated on 2009- 11- 21 02:34)- with 0 comment(s)
Removing switch fall-through from D's switch statement is something discussed since the early beginnings of D, there are discussions about it since 2001 and to the date [*]. If you don't know what I'm talking about, see this example:
switch (x) {
case A:
i = x;
// fall-through
case B:
j = 2;
break;
case C:
i = x + 1;
break;
}
If you read carefully the case B case A code, it doesn't include a break statement, so if x == A not only i = x will be executed, the code in case B will be executed too. This is perfectly valid code, introduced by C, but it tends to be very error prone and if you forget a break statement, the introduced bug can be very hard to track.
Fall-through if fairly rare, and it would make perfect sense to make it explicit. Several suggestions were made in this time to make fall-through explicit, but nothing materialized yet. Here are the most frequently suggested solutions:
Add a new syntax for non-fall-through switch statements, for example:
switch (x) { case A { i = x; } case B { j = 2; } case C { i = x + 1; }Don't fall-through by default, use an explicit statement to ask for fall-through, for example:
switch (x) { case A: i = x; goto case; case B: j = 2; break; case C: i = x + 1; break; }Others suggested continue switch or fallthrough, but I think some of this suggestions were made before goto case was implemented.
A few minutes ago, Chad Joan has filled a bug with this issue, but with a patch attached 8-). He opted for an intermediate solution, more in the lines of new switch syntax. He defines 2 case statements: case X: and case X!: (note the !). The former doesn't allow implicit fall-through and the latter does. This is the example in the bug report:
switch (i)
{
case 1!: // Intent to use fall through behavior.
x = 3;
case 2!: // It's OK to decide to not actually fall through.
x = 4;
break;
case 3,4,5:
x = 5;
break;
case 6: // Error: You either forgot a break; or need to use !: instead of :
case 7: // Fine, ends with goto case.
goto case 1;
case 8:
break;
x = 6; // Error: break; must be the last statement for case 8.
}
While I really think the best solution is to just make a goto case required if you want to fall-through [†], it's great to have a patch for a solution. Thanks Chad! =)
| [†] | I find it more readable and with better locality, to know if something fall-through or not I just have to read the code sequentially without remembering which kind of case I'm in. And I think cases without any statements should be allowed too, I wonder how this works with case range statements. |
Annotations, properties and safety are coming to D
by Leandro Lucarella on 2009- 11- 14 02:34 (updated on 2009- 11- 14 18:45)- with 0 comment(s)
Two days ago, the documentation of functions were updated with some interesting revelations...
After a lot of discussion about properties needing improvements [*], it seems like they are now officially implemented using the annotations, which seems to be official too now, after some more discussion [†].
Annotations will be used for another longly discussed feature, a safe [‡] subset of the language. At first it was thought as some kind of separate language, activated through a flag -safe (which is already in the DMD compiler but has no effect AFAIK), but after the discussion it seems that it will be part of the main language, being able to mark parts of the code as safe or trusted (unmarked functions are unsafe).
Please take a look at the discussions for the details but here are some examples:
Annotations
They are prefixed with @ and are similar to attributes (not class attributes; static, final, private, etc. see the specs for details).
For example:
@ann1 {
// things with annotation ann1
}
@ann2 something; // one thing with annotation ann2
@ann3:
// From now on, everything has the ann3 annotation
For now, only the compiler can define annotations, but maybe in the future the user can do it too and access to them using some reflection. Time will tell, as usual, Walter is completely silent about this.
Properties
Properties are now marked with the @property annotation (maybe a shorter annotation would be better? Like @prop). Here is an example:
class Foo {
@property int bar() { ... } // read-only
@property { // read-write
char baz() { ... }
void baz(char x) { ...}
}
Safe
Now functions can be marked with the annotations @safe or @trusted. Unmarked functions are unsafe. Safe functions can only use a subset of the language that it's safe by some definition (memory safe and no undefined behavior are probably the most accepted definition). Here is a list of things a safe function can't do:
- No casting from a pointer type to any type other than void*.
- No casting from any non-pointer type to a pointer type.
- No modification of pointer values.
- Cannot access unions that have pointers or references overlapping with other types.
- Calling any unsafe functions.
- No catching of exceptions that are not derived from class Exception.
- No inline assembler.
- No explicit casting of mutable objects to immutable.
- No explicit casting of immutable objects to mutable.
- No explicit casting of thread local objects to shared.
- No explicit casting of shared objects to thread local.
- No taking the address of a local variable or function parameter.
- Cannot access __gshared variables.
There is some discussion about bound-checking being active in safe functions even when the -release compiler flag is used.
Trusted functions are not checked by the compiler, but trusted to be safe (should be manually verified by the writer of the function), and can use unsafe code and call unsafe functions.
| [†] | Discussion about annotations: |
Fotopedia
by Leandro Lucarella on 2009- 11- 13 21:06 (updated on 2009- 11- 13 21:06)- with 0 comment(s)
About Fotopedia:
Fotopedia is breathing new life into photos by building a photo encyclopedia that lets photographers and photo enthusiasts collaborate and enrich images to be useful for the whole world wide web.
It's like the Wikipedia but only about pictures. Pick a place, person, object, whatever, and get (Creative Commons licensed) pictures about it.
Burj Dubai
by Leandro Lucarella on 2009- 11- 13 19:02 (updated on 2009- 11- 13 19:02)- with 0 comment(s)
It's a drawing? ... It's a 3D render? ...

It's a photograph! (by Joichi Ito)
The Burj Dubai is the tallest building in the world... by far (about 50% taller than the second). It has a projected shadow of 2.5 Km.
{kind=link}
Go nuts
by Leandro Lucarella on 2009- 11- 11 15:14 (updated on 2009- 11- 11 21:48)- with 0 comment(s)
I guess everybody (at least everybody with some interest in system programming languages) should know by now about the existence of Go, the new system programming language released yesterday by Google.
I think this has a huge impact in D, because it's trying to fill the same hole: a modern high-performance language that doesn't suck (hello C++!). They have a common goal too: be practical for business (they are designed to get things done and easy of implementation). But there are still very big differences about both languages. Here is a small summary (from my subjective point of view after reading some of the Go documentation):
| Go | D |
|---|---|
| Feels more like a high-level high- performance programming language than a real system programming language (no asm, no pointer arithmetics). | Feels more like a real close to the metal system programming language. |
| Extremely simple, with just a very small set of core features. | Much more complex, but very powerful and featureful. |
| Can call C code but can't be called from C code. | Interacts very well with C in both directions (version 2 can partially interact with C++ too). |
| Feels like a very well thought, cohesive programming language. | Feels as a bag of features that grew in the wild. |
| FLOSS reference implementation. Looks very FLOSS friendly, with proper code review, VCS, mailing lists, etc. | Reference implementation is not FLOSS. Not very FLOSS friendly (it's just starting to open up a little but it's a slow and hard process). |
| Supported by a huge corporation, I expect a very large community in very short time. | Supported by a very small group of volunteers, small community. |
I really like the simplicity of Go, but I have my doubts about how limiting it could be in practice (it doesn't even have exceptions!). I have to try it to see if I will really miss the features of more complex programming languages (like templates / generics, exceptions, inheritance, etc.), or if it will just work.
I have the feeling that things will just work, and things missing in Go will not be a problem when doing actual work. Maybe it's because I had a very similar feeling about Python (indentation matters? Having to pass self explicitly to methods? No ++? No assignment in if, while, etc.? I hated all this things at first, but after understanding the rationale and using then in real work, it works great!). Or maybe is because there are is extremely capable people behind it, like Ken Thomson and Rob Pike (that's why you can see all sort of references to Plan 9 in Go :), people that knows about designing operating systems and languages, a good combination for designing a system programming language ;)
You never know with this things, Go could die in the dark or become a very popular programming language, only time will tell (but since Google is behind it, I guess the later is more likely).
DMD frontend 1.051 merged in LDC
by Leandro Lucarella on 2009- 11- 07 18:08 (updated on 2009- 11- 07 18:08)- with 0 comment(s)
TED: Witricity
by Leandro Lucarella on 2009- 11- 06 23:40 (updated on 2009- 11- 06 23:40)- with 0 comment(s)
The concept of transfering energy without wires is pretty old. You can even have it now, with RFID for example (I even have a mouse that uses no battery, the pad transfer energy to the mouse using RFID; very good mouse BTW).
But Eric Giler presents a nice new concept in wireless electricity (the marketing name is Witricity), because other kind of wireless energy transfer I saw has very little power (to avoid frying your brain ;). This one works using a magnetic field instead of radio waves, which makes possible to transfer bigger amounts of energy without harm.
In the video you can see how it powers a big LCD screen for example. I don't know how efficient this will be. At first sight it looks like it would waste a lot of energy, because the magnetic field generation will be using energy all the time, even when there are no devices using it.
Here is the video:
Patch to make D's GC partially precise
by Leandro Lucarella on 2009- 11- 06 14:43 (updated on 2009- 11- 06 23:09)- with 0 comment(s)
David Simcha has announced a couple of weeks ago that he wanted to work on making the D's GC partially precise (only the heap). I was planning to do it myself eventually because it looked like something doable with not much work that could yield a big performance gain, and particularly useful to avoid memory leaks due to false pointers (which can keep huge blocks of data artificially alive). But I didn't had the time and I had other priorities.
Anyway, after some discussion, he finally announced he got the patch, which he added as a bug report. The patch is being analyzed for inclusion, but the main problem now is that it is not integrated with the new operator, so if you want to get precise heap scanning, you have to use a custom function to allocate (that creates a map of the type to allocate at compile-time to pass the information about the location of the pointers to the GC).
I'm glad David could work on this and I hope this can be included in D2, since is a long awaited feature of the GC.
Update
David Schima has been just added to the list of Phobos developers. Maybe he can integrate his work on associative arrays too.
The D Programming Language
by Leandro Lucarella on 2009- 10- 29 15:37 (updated on 2009- 10- 29 15:37)- with 1 comment(s)

The version 2.0 of D will be released in sync with the classic book titled after the language, in this case, The D Programming Language, written by the Andrei Alexandrescu. You can follow the progress of the book looking at his home page, where a words and pages counter and a short term objective are regularly updated.
He posted a little introductory excerpt of the book a while ago and yesterday he published a larger excerpt, the whole chapter 4 about arrays, associative arrays and strings.
If you don't know much about D, it could be a good way to take a peek.
LLVM 2.6
by Leandro Lucarella on 2009- 10- 24 21:30 (updated on 2009- 10- 24 21:30)- with 0 comment(s)
Just in case you're not that well informed, Chris Lattner has just announced the release of LLVM 2.6. Enjoy!
War videos
by Leandro Lucarella on 2009- 10- 23 03:04 (updated on 2009- 10- 23 03:04)- with 0 comment(s)
Here are two very sad videos about wars.
The first is a representation of the battles in the last 1000 years as explosions in a world map. The size of the explosion is proportional to the number of deaths.
I guess it's missing a lot of small battles because you can't see any explosions in very big regions (like Africa, Latin America and India) until some empire tries to conquer them. I'm sorry if I depressed you too much.
The second video at least is cute if you forget what is it really about. Is an animation of food to represent several armed conflicts. Each country is represented by a regional food (you can see the cheat sheet if you get lost).
Found at No Puedo Creer. Lots of interesting stuff there (in Spanish though).
MIT Indoor Autonomous Helicopter
by Leandro Lucarella on 2009- 10- 21 18:26 (updated on 2009- 10- 21 18:26)- with 0 comment(s)
KLEE, automatically generating tests that achieve high coverage
by Leandro Lucarella on 2009- 10- 20 14:20 (updated on 2009- 10- 20 14:20)- with 0 comment(s)
This is the abstract of the paper describing KLEE, a new LLVM sub-project announced with the upcoming 2.6 release:
We present a new symbolic execution tool, KLEE, capable of automatically generating tests that achieve high coverage on a diverse set of complex and environmentally-intensive programs. We used KLEE to thoroughly check all 89 stand-alone programs in the GNU COREUTILS utility suite, which form the core user-level environment installed on millions of Unix systems, and arguably are the single most heavily tested set of open-source programs in existence. KLEE-generated tests achieve high line coverage — on average over 90% per tool (median: over 94%) — and significantly beat the coverage of the developers' own hand-written test suites. When we did the same for 75 equivalent tools in the BUSYBOX embedded system suite, results were even better, including 100% coverage on 31 of them. We also used KLEE as a bug finding tool, applying it to 452 applications (over 430K total lines of code), where it found 56 serious bugs, including three in COREUTILS that had been missed for over 15 years. Finally, we used KLEE to cross-check purportedly identical BUSYBOX and COREUTILS utilities, finding functional correctness errors and a myriad of inconsistencies.
I have to try this...
Anti-love song
by Leandro Lucarella on 2009- 10- 17 04:01 (updated on 2009- 10- 17 04:01)- with 0 comment(s)
I always found fascinating the mixture of beauty and terror that The Beautiful South is capable of =P
For instance, read the lyrics from Something That You Said from the album 0898 Beautiful South. Here are some fragments of the lyrics:
The perfect love song it has no words it only has death threatsAnd you can tell a classic ballad by how threatening it getsSo if you walk into your house and she's cutting up your motherShe's only trying to tell you that she loves you like no otherNo other, she loves you like no other.[...]The perfect love has no emotions, it only harbours doubtAnd if she fears your intentions she will cut you outSo do not raise your voice and do not shake your fistJust pass her the carving knife, if that's what she insists[...]The perfect kiss is dry as sand and doesn't take your breathThe perfect kiss is with the boy that you've just stabbed to death
But please, go and read the full lyrics first.
Now try to picture how this song would sound like (if you don't already know it, of course =). You might think it will sound like a creepy death metal band, but no. You can hear 30 seconds of the song at last.fm to know how it really sounds.
{kind=link}
The song is awfully peaceful, and the voice is Briana Corrigan is incredibly beautiful. But what it makes this a great song for me is the contrast between music and lyrics. They have plenty of songs using this resource and a lot of irony (for example, the more popular Song For Whoever).
For those who don't know anything about this band, it was formed by two ex-members of The Housemartins (I hope you know them =).
pybugz, a python and command line interface to Bugzilla
by Leandro Lucarella on 2009- 10- 16 14:14 (updated on 2009- 10- 16 14:14)- with 0 comment(s)
Tired of the clumsy Bugzilla web interface? Meet pybugz, a command line interface for Bugzilla.
An example workflow from the README file:
$ bugz search "version bump" --assigned liquidx@gentoo.org * Using http://bugs.gentoo.org/ .. * Searching for "version bump" ordered by "number" 101968 liquidx net-im/msnlib version bump 125468 liquidx version bump for dev-libs/g-wrap-1.9.6 130608 liquidx app-dicts/stardict version bump: 2.4.7 $ bugz get 101968 * Using http://bugs.gentoo.org/ .. * Getting bug 130608 .. Title : app-dicts/stardict version bump: 2.4.7 Assignee : liquidx@gentoo.org Reported : 2006-04-20 07:36 PST Updated : 2006-05-29 23:18:12 PST Status : NEW URL : http://stardict.sf.net Severity : enhancement Reporter : dushistov@mail.ru Priority : P2 Comments : 3 Attachments : 1 [ATTACH] [87844] [stardict 2.4.7 ebuild] [Comment #1] dushistov@----.ru : 2006-04-20 07:36 PST ... $ bugz attachment 87844 * Using http://bugs.gentoo.org/ .. * Getting attachment 87844 * Saving attachment: "stardict-2.4.7.ebuild" $ bugz modify 130608 --fixed -c "Thanks for the ebuild. Committed to portage"
D and open development model
by Leandro Lucarella on 2009- 10- 15 20:09 (updated on 2009- 10- 15 20:09)- with 6 comment(s)
Warning
Long post ahead =)
I'm very glad that yesterday DMD had the first releases (DMD 1.050 and DMD 2.035) with a decent revision history. It took some time to Walter Bright to understand how the open source development model works, and I think he still has a lot more to learn, but I have some hope now about the future of D.
Not much time ago, neither Phobos, DMD nor Druntime had revision control. Druntime didn't even exist, making D 1 split in two because of the Phobos vs Tango dichotomy. DMD back-end sources were not available either, and Walter Bright was the only person writing stuff (sometimes not because people didn't want to, but because he was too anal retentive to let them ;). It was almost impossible to make patches back then (your only chance was hacking GDC, which is pretty hard).
Now I can say that DMD, Phobos and Druntime have full source availability (DMD back-end is not free/libre though), almost all the parts of DMD have the sources published under a source control system. The core team has been expanded and even when Walter Bright is still in charge, at least 3 developers are now very committed to D: Andrei Alexandrescu (in charge of Phobos), Sean Kelly (in charge of Druntime) and Don Clugston (squashing DMD bugs at full speed, specially in the back-end). Other people are contributing patches in a regular basis. There were about 72 patches submitted to bugzilla before DMD was distributed with full source (72 patches in ~10 years) , since then, 206 patches were submitted (that is, 206 patches in less than 8 months).
But even with this great improvement, there is much left to do yet (and I'm talking only about the development model). This is a small list of what I think it's necessary to keep moving to a more open development model:
Releases
The release process should be improved. Me and other people are suggesting release candidates. This will allow people to test the new releases to find any regressions. As things are now, releases are not much different from a nightly build, except that you don't have one available every night :). People get very frustrated when downloading a new version of the compiler and things stop working, and this holds back front-end updates in other compilers, like LDC (which is frozen at 1.045 because of the regressions found in the next 5 versions).
I think Walter Bright is suffering from premature releasing too. Releases comes from nowhere, when nobody expects them. Nobody knows when a new compiler version will be released. I think that hurts the language reliability.
I think the releases should be more predictable. A release schedule (even when not very accurate, like in many other open source projects) gives you some peace of mind.
Peer review
Even when commits are fairly small now in DMD, I think they are far from ideal. Is very common to see unrelated changes in a commit (the classic example is the compiler version number being bumped in an bug fix). See revision 214 for example: the compiler version is bumped and there are some changes to the new JSON output, totally unrelated to bug 3401, which is supposed to fix; or revision 213, which announces the release of DMD 1.050 and DMD 2.035, introducing a bunch of changes that who knows what are supposed to do (well, they look like the introduction of the new type T[new], but that's not even documented in the release changelog :S). This is bad for several reasons:
- Reviewing a patch with unrelated changes is hard.
- If you want to fold in a individual patch (let's say, LDC guys want to fold a bug fix), you have a lot of junk to take care of.
- If you want to do some sort of bisection to find a regression, you still have to figure out which is the group of related changes that introduced the regression.
I'm sure there are more...
Commit messages lacks a good description of the problem and the solution. Most commit messages in DMD are "bugzilla N". You have to go to the bugzilla bug to know what's all about. For example, Don's patches usually comes with very good and juicy information about the bug causes and why the patch fixes it (see an example). That is a good commit message. You can learn a lot about the code by reading well commented patches, which can lead to more contributions in the future.
Commits in Phobos can be even worse. The commits with a message "bugzilla N" are usually the good ones. There are 56 commits that have "minor" as the commit message. Yes, just "minor". That's pretty useless, it's very hard to review a patch when you don't know what is supposed to do. Commit messages are the base of peer reviewing, and peer reviewing is the base for high quality code.
So I think that D developers should focus a lot more in commit message. I know it can sound silly at first, but I think I would be a huge gain with too little effort.
Besides this, commits should be mailed to a newsgroup or mailing list to easy peer review. Now it's a little hard to make comments about a commit, you have to post the comment in the D newsgroup or make the comment by personal e-mail to the author. The former is not that bad but it's not easy to include context and people reading the comment will probably have to open a browser and search for the commented commit. This clearly make peer reviewing more difficult when the ideal would be to encourage it. The private mail is simply wrong because other people can't see the comments.
Source control and versioning
This one is tightly related to the previous two topics. Using a good DVCS can make help a lot too. Subversion has a lot of problems with branching, which makes releases harder too (as having a branch for each release is very painful). Is bad for commit messages too, because there is no real difference in branches and directories, so know every commit is duplicated (both changes for DMD 1 and 2 are included). It's not easy to cherry-pick single commits either, and you can't fix you commits if you messed up, which leads to a lot of commits of the style "Woops! Fix the typo in the previous commit.".
I'm sure both the release process and peer reviewing can be greatly improved by using a better DVCS.
Easy branching can also lead to a more fast evolving and reliable language. Yes, both are possible with branches. Now there are 2 branches: stable (D1) and experimental (D2). D1 is almost frozen and people is seeing less and less interest on it as it goes old, and D2 is too unstable for real use. Having some intermediate can be really helpful. For example, it has been announced that the concurrency model proposed by Bartosz Milewski will be not part of D2 because there is not enough time to implement it, since D2 should be release fairly soon as Andrei Alexandrescu is writing a book that has a deadline and the language has to be finalized by the time the book is published.
So concurrency (as AST macros) are delayed to D3. D2 is more than 2 years old, so one should expect that D3 will be not available in less than 5 years from now (assuming D2 would take 2.5 years and D3 would take the same). This might be too much time.
I think the language should adopt a model closer to Python, where a minor language version (with backward compatible improvements) is release every 1 ~ 1.5 years. Last mayor version took about 8 years, but considering how many new features Python included in minor versions that's not a big issue. The last mayor version was mostly a clean up of old stuff/nasty stuff, not huge changes to the language.
Licensing
I think the DMD back-end should have a better license. Personal use is simply not enough for a reference implementation of a language that wants to hit mainstream. If you plan to do business with it, not being able to patch the compiler if you need to and distribute it is not an option.
This is for the sake of DMD only, because other compilers (like LDC and GDC) are fully free/libre.
Conclusion
Some of the things I mention are really hard to change, as they modify how people work and imply learning new tools. But other are fairly easy, and can be done progressively (like providing release candidates and improving commits and commit messages).
I hope Walter Bright & Co. keep walking the openness road =)
LLVM developer meeting videos available
by Leandro Lucarella on 2009- 10- 15 13:55 (updated on 2009- 10- 15 16:35)- with 0 comment(s)
Chris Lattner announced that the videos for the last LLVM developer meeting are now available. They are usually very interesting, so I'd recommend to watch them if you have some time.
Update
Big WTF and many anti-cool-points for Apple:
On Oct 15, 2009, at 8:29 AM, Anton Korobeynikov wrote: [...] > I'm a bit curious: is there any reason why are other slides / videos > not available (it seems that the ones missing are from Apple folks)? Unfortunately, we found out at the last minute that Apple has a rule which prevents its engineers from giving video taped talks or distributing slides. We will hold onto the video and slide assets in case this rule changes in the future. -Chris
Fragment from a response to the announcement.
Mutt patched with NNTP support for Debian (and friends)
by Leandro Lucarella on 2009- 10- 14 04:01 (updated on 2009- 10- 14 04:01)- with 2 comment(s)
Did you ever wanted Mutt with NNTP support packed up for your Debian (or Debian-ish) box, but you are too lazy to do it yourself? Did you even tried to report a bug so the patch can be applied to the official Debian package but the maintainers told you they wont do it?
If so, this is a great day for you, because I did it and I'm giving it away with no charge in this one time only opportunity!!! =P
Seriously, I can understand why the maintainers don't want to support it officially, it a big patch and can be some work to fold it in. So I did it myself, and it turned out it's wasn't that bad.
I adjusted the patch maintained by Vsevolod Volkov to work on top of all the other patches included in the mutt-patched Debian package (the only conflicting patch is the sidebar patch and some files that doesn't exist because the patch should be applied after autotools files are generated and Debian apply the patches before that) and built the package using the latest Debian source (1.5.20-4).
You can find the source package and the binary packages for Debian unstable i386 here. You can find there the modified NNTP patch too.
If you have Ubuntu or other Debian based distribution, you can compile the binary package by downloading the files mutt_1.5.20-4luca1.diff.gz, mutt_1.5.20-4luca1.dsc and mutt_1.5.20.orig.tar.gz, then run:
$ sudo apt-get build-dep mutt
$ dpkg-source -x mutt_1.5.20-4luca1.dsc
$ cd mutt-1.5.20
$ dpkg-buildpackage -rfakeroot
$ cd ..
$ sudo dpkg -i mutt_1.5.20-4luca1_i386.deb \
mutt-patched_1.5.20-4luca1_i386.deb
Now you can enjoy reading the D newsgroups and your favourite mailing lists via Gmane with Mutt without leaving the beauty of your packaging system. No need to thank me, I'm glad to be helpful ;)
Lessfs
by Leandro Lucarella on 2009- 10- 11 19:56 (updated on 2009- 10- 11 19:56)- with 0 comment(s)
Lessfs is an open source data deduplication filesystem:
Data deduplication (often called "intelligent compression" or "single-instance storage") is a method of reducing storage needs by eliminating redundant data. [...] lessfs can determine if data is redundant by calculating an unique (192 bit) tiger hash of each block of data that is written. When lessfs has determined that a block of data needs to be stored it first compresses the block with LZO or QUICKLZ compression. The combination of these two techniques results in a very high overall compression rate for many types of data.
Україна має талант
by Leandro Lucarella on 2009- 10- 10 23:27 (updated on 2009- 10- 10 23:27)- with 0 comment(s)
I'm not Ukrainian, I just like how weird foreign symbols looks like in my blog =P
Україна має талант means something like Ukraine's Got Talent and is where Kseniya Simonova fame comes from. It's indescribable what she does, you just have to see a video.
You might enjoy it (or understand it) a little more if you read about what's going on before actually seeing the videos.
Here is a fragment from a small article:
The appearance of a shy 24-year-old on a Ukrainian TV talent show this year has caused a nation to revisit its painful wartime past and is well on the way to becoming an international sensation.
About 13 million people watched Kseniya Simonova win Ukraine's Got Talent live with an extraordinary demonstration of "sand art". Most of them, according to reports, were weeping.
file:line VIM plug-in
by Leandro Lucarella on 2009- 10- 10 19:59 (updated on 2009- 10- 10 19:59)- with 0 comment(s)
This VIM script should be part of the official VIM distribution:
When you open a file:line, for instance when copying and pasting from an error from your compiler VIM tries to open a file with a colon in its name. With this little script in your plugins folder if the stuff after the colon is a number and a file exists with the name specified before the colon VIM will open this file and take you to the line you wished in the first place.
Link Time Optimization
by Leandro Lucarella on 2009- 10- 10 18:34 (updated on 2009- 10- 10 18:34)- with 0 comment(s)
The upcoming LLVM 2.6 will include a plug-in for Gold to implement Link Time Optimization (LTO) using LLVM's LibLTO. There is a similar project for GCC, merged into the main trunk about a week ago. It will be available in GCC 4.5.
This is all fairly new, and will be not enabled by default in LLVM (I don't know what about GCC), but it will add a lot of new optimization oportunities in the future.
So people using LDC and GDC will probably be able to enjoy LTO in a near future =)
Stats for the basic GC
by Leandro Lucarella on 2009- 10- 08 23:08 (updated on 2009- 10- 08 23:08)- with 0 comment(s)
Here are some graphs made from my D GC benchmarks using the Tango (0.99.8) basic collector, similar to the naive ones but using histograms for allocations (time and space):





Some comments:
- The Wasted space is the Uncommitted space (since the basic GC doesn't track the real size of the stored object).
- The Stop-the-world time is the time all the threads are stopped, which is almost the same as the time spent scanning the heap.
- The Collect time is the total time spent in a collection. The difference with the Stop-the-world time is almost the same as the time spent in the sweep phase, which is done after the threads have being resumed (except the thread that triggered the collection).
There are a few observations to do about the results:
- The stop the world time varies a lot. There are tests where is almost unnoticeable (tree), tests where it's almost equals to the total collection time (rnd_data, rnd_data_2, split) and test where it's in the middle (big_arrays). I can't see a pattern though (like heap occupancy).
- There are tests where it seems that collections are triggered for no reason; there is plenty of free space when it's triggered (tree and big_arrays). I haven't investigated this yet, so if you can see a reason, please let me know.
Tucan {up,down}load manager for file hosting sites
by Leandro Lucarella on 2009- 10- 06 14:02 (updated on 2009- 10- 06 14:02)- with 0 comment(s)
Meet Tucan:

Tucan is a free and open source application designed for automatic management of downloads and uploads at hosting sites like Rapidshare.
GDC resurrection
by Leandro Lucarella on 2009- 10- 05 14:31 (updated on 2009- 10- 05 14:31)- with 0 comment(s)
About a month ago, the GDC newsgroup started to get some activity when Michael P. and Vincenzo Ampolo started working on updating GCD. Yesterday they announced that they successfully merged the DMD frontend 1.038 and 2.015, and a new repository for GDC. They will be hanging on #d.gdc if you have any questions or want to help out.
So great news for the D ecosystem! Kudos for this two brave men! =)
YikeBike & Mini-Farthing
by Leandro Lucarella on 2009- 10- 03 02:33 (updated on 2009- 10- 03 02:33)- with 2 comment(s)
YikeBike, an implementation of a mini-farthing. Too bad is a propietary design...
DGC page is back
by Leandro Lucarella on 2009- 10- 02 16:17 (updated on 2009- 10- 02 16:17)- with 0 comment(s)
The Yes Men
by Leandro Lucarella on 2009- 10- 02 03:05 (updated on 2009- 10- 02 03:05)- with 0 comment(s)
English
Watch The Yes Men.
Identity Correction
Impersonating big-time criminals in order to publicly humiliate them. Targets are leaders and big corporations who put profits ahead of everything else.
Links:
Español
Vean The Yes Men.
Corrección de identidad
Hacerse pasar por grandes criminales con el fin de humillarlos públicamente. Los objetivos son líderes y grandes corporaciones que ponen las ganancias por sobre todo el resto.
Links:
Fantastic Photos of our Solar System
by Leandro Lucarella on 2009- 09- 30 14:27 (updated on 2009- 09- 30 14:27)- with 0 comment(s)
Erupting Prominence: http://media.smithsonianmag.com/images/erupting-prominence-3.jpg
{kind=link}
8-bit Lego Trip
by Leandro Lucarella on 2009- 09- 29 15:31 (updated on 2009- 09- 29 15:31)- with 0 comment(s)
Feeds
by Leandro Lucarella on 2009- 09- 29 02:49 (updated on 2009- 09- 29 02:49)- with 0 comment(s)
I found out that my blog software (blitiri) already support tag-specific feeds, you just have to some extra GET variable(s) to the URL, for example:
/blog/blog/atom?tag=en&tag=self
This URL will get you the posts with both tags: en and self. I've set up some common feeds at feedburner (en, es and D for now). Please, use those if you can (i.e. if you don't need a feed for other tags).
World Digital Library
by Leandro Lucarella on 2009- 09- 28 03:27 (updated on 2009- 09- 28 03:27)- with 0 comment(s)
New home page and blog
by Leandro Lucarella on 2009- 09- 28 03:15 (updated on 2009- 09- 29 02:38)- with 3 comment(s)
Finally I removed my Redmine instance because it was eating up all my (modest) server memory. For my home page I'm using mostly static pages, rendered from reStructuredText using Sphinx. It's not particularly nice, but it's simple and cheap :)
I was a little tired of posting to several blogs (my thesis blog about DGC, Mazziblog and 4am), so I decided to centralize things. From now on, I'll be posing just here, I guess :)
So I'm generalizing my ex-"thesis blog" to some kind of "planet Luca". The good news is I plan to post a lot more, the bad news is that probably the posts quality will decrease =P, because I want to use this blog as a kind of notebook. I hope what I post is useful and interesting to other people, but I can't promise anything.
I will try to post in English except when the topic makes no sense for non-Spanish speakers (or non-Argentine people :). You can subscribe to only English-only or Spanish-only posts using the en or es tags respectively.
Update
I'm sorry, but my blog doesn't support feeding a tag, so the en/es feeds are not working properly yet (they feed the whole blog content for now).
I'll let you know when this is fixed.
Update
Language-specific feeds (en/es) are now working ;)
In fact, you can get a feed for any (AND combination of) tags you want adding "tag"s GET variables to the atom URL. For example, you can receive only posts in English about garbage collection.
Life in hell
by Leandro Lucarella on 2009- 09- 06 21:24 (updated on 2009- 09- 06 21:24)- with 0 comment(s)
Warning
Long post ahead =)
As I said before, debug is hell in D, at least if you're using a compiler that doesn't write proper debug information and you're writing a garbage collector. But you have to do it when things go wrong. And things usually go wrong.
This is a small chronicle about how I managed to debug a weird problem =)
I had my Naive GC working and getting good stats with some small micro-benchmarks, so I said let's benchmark something real. There is almost no real D applications out there, suitable for an automated GC benchmark at least [1]. Dil looked like a good candidate so I said let's use Dil in the benchmark suite!.
And I did. But Dil didn't work as I expected. Even when running it without arguments, in which case a nice help message like this should be displayed:
dil v1.000 Copyright (c) 2007-2008 by Aziz Köksal. Licensed under the GPL3. Subcommands: help (?) compile (c) ddoc (d) highlight (hl) importgraph (igraph) python (py) settings (set) statistics (stats) tokenize (tok) translate (trans) Type 'dil help <subcommand>' for more help on a particular subcommand. Compiled with Digital Mars D v1.041 on Sat Aug 29 18:04:34 2009.
I got this instead:
Generate an XML or HTML document from a D source file. Usage: dil gen file.d [Options] Options: --syntax : generate tags for the syntax tree --xml : use XML format (default) --html : use HTML format Example: dil gen Parser.d --html --syntax > Parser.html
Which it isn't even a valid Dil command (it looks like a dead string in some data/lang_??.d files).
I ran Valgrind on it and detected a suspicious invalid read of size 4 when reading the last byte of a 13 bytes long class instance. I thought maybe the compiler was assuming the GC allocated block with size multiples of the word size, so I made gc_malloc() allocate multiples of the word size, but nothing happened. Then I thought that maybe the memory blocks should be aligned to a multiple of a word, so I made gc_malloc() align the data portion of the cell to a multiple of a word, but nothing.
Since Valgrind only detected that problem, which was at the static constructor of the module tango.io.Console, I though it might be a Tango bug, so I reported it. But it wasn't Tango's fault. The invalid read looked like a DMD 1.042 bug; DMD 1.041 didn't have that problem, but my collector still failed to run Dil. So I was back to zero.
I tried the Tango stub collector and it worked, so I tried mine disabling the collections, and it worked too. So finally I could narrow the problem to the collection phase (which isn't much, but it's something). The first thing I could think it could be wrong in a collection is that cells still in use are swept as if they were unused, so I then disabled the sweep phase only, and it kept working.
So, everything pointer to prematurely freed cells. But why my collector was freeing cells prematurely being so, so simple? I reviewed the code a couple of times and couldn't find anything evidently wrong. To confirm my theory and with the hope of getting some extra info, I decided to write a weird pattern in the swept cells and then check if that pattern was intact when giving them back to the mutator (the basic GC can do that too if compiled with -debug=MEMSTOMP). That would confirm that the swept memory were still in use. And it did.
The I tried this modified GC with memory stomp with my micro-benchmarks and they worked just fine, so I started to doubt again that it was my GC's problem. But since those benchmarks didn't use much of the GC API, I thought maybe Dil was using some strange features of making some assumptions that were only true for the current implementation, so I asked Aziz Köksal (Dil creator) and he pointed me to some portion of code that allocated memory from the C heap, overriding the operators new and delete for the Token struct. There is a bug in Dil there, because apparently that struct store pointers to the GC heap but it's not registered as a root, so it looks like a good candidate.
So I commented out the overridden new and delete operators, so the regular GC-based operators were used. But I still got nothing, the wrong help message were printed again. Then I saw that Dil was manually freeing memory using delete. So I decided to make my gc_free() implementation a NOP to let the GC take over of all memory management... And finally all [2] worked out fine! =)
So, the problem should be either my gc_free() implementation (which is really simple) or a Dil bug.
In order to get some extra information on where the problem is, I changed the Cell.alloc() implementation to use mmap to allocate whole pages, one for the cell's header, and one or more for the cell data. This way, could easily mprotect the cell data when the cell was swept (and un-mprotecting them when they were give back to the program) in order to make Dil segfault exactly where the freed memory was used.
I ran Dil using strace and this is what happened:
[...]
(a) write(1, "Cell.alloc(80)\n", 15) = 15
(b) mmap2(NULL, 8192, PROT_READ|PROT_WRITE, ...) = 0xb7a2e000
[...]
(c) mprotect(0xb7911000, 4096, PROT_NONE) = 0
mprotect(0xb7913000, 4096, PROT_NONE) = 0
[...]
mprotect(0xb7a2b000, 4096, PROT_NONE) = 0
mprotect(0xb7a2d000, 4096, PROT_NONE) = 0
(d) mprotect(0xb7a2f000, 4096, PROT_NONE) = 0
mprotect(0xb7a43000, 4096, PROT_NONE) = 0
mprotect(0xb7a3d000, 4096, PROT_NONE) = 0
[...]
mprotect(0xb7a6b000, 4096, PROT_NONE) = 0
(e) mprotect(0xb7a73000, 4096, PROT_NONE) = 0
(f) mprotect(0xb7a73000, 4096, PROT_READ|PROT_WRITE) = 0
mprotect(0xb7a6b000, 4096, PROT_READ|PROT_WRITE) = 0
[...]
mprotect(0xb7a3f000, 4096, PROT_READ|PROT_WRITE) = 0
(g) mprotect(0xb7a3d000, 4096, PROT_READ|PROT_WRITE) = 0
--- SIGSEGV (Segmentation fault) @ 0 (0) ---
+++ killed by SIGSEGV (core dumped) +++
(a) is a debug print, showing the size of the gc_malloc() call that got the address 0xb7a2e000. The mmap (b) is 8192 bytes in size because I allocate a page for the cell header (for internal GC information) and another separated page for the data (so I can only mprotect the data page and keep the header page read/write); that allocation asked for a new fresh couple of pages to the OS (that's why you see a mmap).
From (c) to (e) you can see a sequence of several mprotect, that are cells being swept by a collection (protecting the cells against read/write so if the mutator tries to touch them, a SIGSEGV is on the way).
From (f) to (g) you can see another sequence of mprotect, this time giving the mutator permission to touch that pages, so that's gc_malloc() recycling the recently swept cells.
(d) shows the cell allocated in (a) being swept. Why the address is not the same (this time is 0xb7a2f000 instead of 0xb7a2e000)? Because, as you remember, the first page is used for the cell header, so the data should be at 0xb7a2e000 + 4096, which is exactly 0xb7a2f000, the start of the memory block that the sweep phase (and gc_free() for that matter) was protecting.
Finally we see the program getting his nice SIGSEGV and dumping a nice little core for touching what it shouldn't.
Then I opened the core with GDB and did something like this [3]:
Program terminated with signal 11, Segmentation fault.
(a) #0 0x08079a96 in getDispatchFunction ()
(gdb) print $pc
(b) $1 = (void (*)()) 0x8079a96 <getDispatchFunction+30>
(gdb) disassemble $pc
Dump of assembler code for function
getDispatchFunction:
0x08079a78 <getDispatchFunction+0>: push %ebp
0x08079a79 <getDispatchFunction+1>: mov %esp,%ebp
0x08079a7b <getDispatchFunction+3>: sub $0x8,%esp
0x08079a7e <getDispatchFunction+6>: push %ebx
0x08079a7f <getDispatchFunction+7>: push %esi
0x08079a80 <getDispatchFunction+8>: mov %eax,-0x4(%ebp)
0x08079a83 <getDispatchFunction+11>: mov -0x4(%ebp),%eax
0x08079a86 <getDispatchFunction+14>: call 0x80bccb4 <objectInvariant>
0x08079a8b <getDispatchFunction+19>: push $0xb9
0x08079a90 <getDispatchFunction+24>: mov 0x8(%ebp),%edx
0x08079a93 <getDispatchFunction+27>: add $0xa,%edx
(c) 0x08079a96 <getDispatchFunction+30>: movzwl (%edx),%ecx
[...]
(gdb) print /x $edx
(d) $2 = 0xb7a2f000
First, in (a), GDB tells where the program received the SIGSEGV. In (b) I print the program counter register to get a more readable hint on where the program segfaulted. It was at getDispatchFunction+30, so I disassemble that function to see that the SIGSEGV was received when doing movzwl (%edx),%ecx (moving the contents of the ECX register to the memory pointed to by the address in the register EDX) at (c). In (d) I get the value of the EDX register, and it's 0xb7a2f000. Do you remember that value? Is the data address for the cell at 0xb7a2e000, the one that was recently swept (and mprotected). That's not good for business.
This is the offending method (at dil/src/ast/Visitor.d):
Node function(Visitor, Node) getDispatchFunction()(Node n)
{
return cast(Node function(Visitor, Node))dispatch_vtable[n.kind];
}
Since I can't get any useful information from GDB (I can't even get a proper backtrace [4]) except for the mangled function name (because the wrong debug information produced by DMD), I had to split that function into smaller functions to confirm that the problem was in n.kind (I guess I could figure that out by eating some more assembly, but I'm not that well trained at eating asm yet =). This means that the Node instance n is the one prematurely freed.
This is particularly weird, because it looks like the node is being swept, not prematurely freed using an explicit delete. So it seems like the GC is missing some roots (or there are non-aligned pointers or weird stuff like that). The fact that this works fine with the Tango basic collector is intriguing too. One thing I can come up with to explain why it works in the basic collector is because it makes a lot less collections than the naive GC (the latter is really lame =). So maybe the rootless object becomes really free before the basic collector has a chance to run a collection and because of that the problem is never detected.
I spent over 10 days now investigating this issue (of course this is not near a full-time job for me so I can only dedicate a couple of days a week to this =), and I still can't find a clear cause for this problem, but I'm a little inclined towards a Dil bug, so I reported one =). So we'll see how this evolves; for now I'll just make gc_free() a NOP to continue my testing...
| [1] | Please let me know if you have any working, real, Tango-based D application suitable for GC benchmarks (i.e., using the GC and easily scriptable to run it automatically). |
| [2] | all being running Dil without arguments to get the right help message =) |
| [3] | I have shortened the name of the functions because they were huge, cryptic, mangled names =). The real name of getDispatchFunction is _D3dil3ast7Visitor7Visitor25__T19getDispatchFunctionZ19getDispatchFunctionMFC3dil3ast4Node4NodeZPFC3dil3ast7Visitor7VisitorC3dil3ast4Node4NodeZC3dil3ast4Node4Node (is not much better when demangled: class dil.ast.Node.Node function(class dil.ast.Visitor.Visitor, class dil.ast.Node.Node)* dil.ast.Visitor.Visitor.getDispatchFunction!().getDispatchFunction(class dil.ast.Node.Node) =). The real name of objectInvariant is D9invariant12_d_invariantFC6ObjectZv and has no demagled name that I know of, but I guessed is the Object class invariant. |
| [4] | Here is what I get from GDB: (gdb) bt #0 0x08079a96 in getDispatchFunction () #1 0xb78d5000 in ?? () #2 0xb789d000 in ?? () Backtrace stopped: previous frame inner to this frame (corrupt stack?) (function name unmangled and shortened for readbility) |
Allocations graphs
by Leandro Lucarella on 2009- 08- 27 00:54 (updated on 2009- 08- 27 00:54)- with 0 comment(s)
Here are a set of improved statistics graphs, now including allocation statistics. All the data is plotted together and using the same timeline to ease the analysis and comparison.
Again, all graphs (as the graph title says), are taken using the Naive GC (stats code still not public yet :) and you can find the code for it in my D GC benchmark repository.
This time the (big) graphs are in EPS format because I could render them in PNG as big as I wanted and I didn't had the time to fix that =S







The graphs shows the same as in the previous post with the addition of allocation time (how long it took to perform the allocation) and space (how many memory has been requested), which are rendered in the same graph, and an histogram of cell sizes. The histogram differentiates cells with and without the NO_SCAN bit, which might be useful in terms on seeing how bad the effect of false positives could be.
You can easily see how allocation time peeks match allocations that triggered a collection for example, and how bad can it be the effect of false positives, even when almost all the heap (99.99%) has the NO_SCAN bit (see rnd_data_2).
Graphs
by Leandro Lucarella on 2009- 08- 18 03:26 (updated on 2009- 08- 18 03:26)- with 0 comment(s)
It's been exactly 3 months since the last post. I spent the last months writing my thesis document (in Spanish), working, and being unproductive because of the lack of inspiration =)
But in the last couple of days I decided to go back to the code, and finish the statistics gathering in the Naive GC (the new code is not published yet because it needs some polishing). Here are some nice graphs from my little D GC benchmark:







The graphs shows the space and time costs for each collection in the programs life. The collection time is divided in the time spent in the malloc() that triggered the collection, the time spent in the collection itself, and the time the world has to be stopped (meaning the time all the threads were paused because of the collection). The space is measured before and after the collection, and the total memory consumed by the program is divided in 4 areas: used space, free space, wasted space (space that the user can't use but it's not used by the collector either) and overhead (space used by the collector itself).
As you can see, the naive collector pretty much sucks, specially for periods of lots of allocation (since it just allocated what it's asked in the gc_malloc() call if the collection failed).
The next step is to modify the Tango's Basic collector to gather the same data and see how things are going with it.
Naive GC fixes
by Leandro Lucarella on 2009- 05- 17 22:09 (updated on 2009- 05- 17 22:09)- with 0 comment(s)
I haven't been posting very often lately because I decided to spend some time writing my thesis document (in Spanish), which was way behind my current status, encouraged by my code-wise bad weekend =P.
Alberto Bertogli was kind enough to review my Naive GC implementation and sent me some patches, improving the documentation (amending my tarzanesque English =) and fixing a couple of (nasty) bugs [1] [2].
I'm starting to go back to the code, being that LDC is very close to a new release and things are starting to settle a little, so I hope I can finish the statistics gathering soon.
Debug is hell
by Leandro Lucarella on 2009- 05- 04 03:24 (updated on 2009- 05- 04 03:24)- with 0 comment(s)
Warning
Rant ahead.
If Matt Groeing would ever written a garbage collector I'm sure he would made a book in the Life in Hell series called Debug is Hell.
You can't rely on anything: unit tests are useless, they depend on your code to run and you can't get a decent backtrace ever using a debugger (the runtime calls seems to hidden to the debugger). I don't know if the last one is a compiler issue (I'm using DMD right now because my LDC copy broken =( ).
Add that to the fact that GNU Gold doesn't work, DMD doesn't work, Tango doesn't work [*] and LDC doesn't work, and that it's already hard to debug in D because most of the mainstream tools (gdb, binutils, valgrind) don't support the language (can't demangle D symbols for instance) and you end up with a very hostile environment to work with.
Anyway, it was a very unproductive weekend, my statistics gathering code seems to have some nasty bug and I'm not being able to find it.
PS: I want to apologize in advance to the developers of GNU Gold, DMD, Tango and LDC because they make great software, much less crappier than mine (well, to be honest I'm not so sure about DMD ;-P), it's just a bad weekend. Thank you for your hard work, guys =)
| [*] | Tango trunk is supposed to be broken for Linux |
Statistics, benchmark suite and future plans
by Leandro Lucarella on 2009- 05- 02 01:43 (updated on 2009- 05- 02 01:43)- with 4 comment(s)
I'm starting to build a benchmark suite for D. My benchmarks and programs request was a total failure (only Leonardo Maffi offered me a small trivial GC benchmark) so I have to find my own way.
This is a relative hard task, I went through dsource searching for real D programs (written using Tango, I finally desisted in making Phobos work in LDC because it would be a very time consuming task) and had no much luck either. Most of the stuff there are libraries, the few programs are: not suitable for an automated benchmark suite (like games), abandoned or work with Phobos.
I found only 2 candidates:
I just tried dack for now (I tried MiniD a while ago but had some compilation errors, I have to try again). Web-GMUI seems like a nice maintained candidate too, but being a client to monitor other BitTorrent clients, seems a little hard to use in automated benchmarks.
For a better usage of the benchmark suite, I'm adding some statistics gathering to my Naive GC implementation, and I will add that too to the Tango basic GC implementation. I will collect this data for each and every collection:
- Collection time
- Stop-the-world time (time all the threads were suspended)
- Current thread suspension time (this is the same as Collection time in both Naive and Tango Basic GC implementations, but it won't be that way in my final implementation)
- Heap memory used by the program
- Free heap memory
- Memory overhead (memory used by the GC not usable by the program)
The three last values will be gathered after and before the collection is made.
Anyway, if you know any program that can be suitable for use in an automated benchmark suite that uses Tango, please, please let me know.
Naive Garbage Collector
by Leandro Lucarella on 2009- 04- 27 01:49 (updated on 2009- 04- 27 01:49)- with 0 comment(s)
I was working in a naive garbage collector implementation for D, as a way to document the process of writing a GC for D.
From the Naive Garbage Collector documentation:
The idea behind this implementation is to document all the bookkeeping and considerations that has to be taken in order to implement a garbage collector for D.
The garbage collector algorithm itself is extremely simple so focus can be held in the specifics of D, and not the algorithm. A completely naive mark and sweep algorithm is used, with a recursive mark phase. The code is extremely inefficient in order to keep the code clean and easy to read and understand.
Performance is, as expected, horrible, horrible, horrible (2 orders of magnitude slower than the basic GC for the simple Tango GC Benchmark) but I think it's pretty good as documentation =)
I have submitted the implementation to Tango in the hope that it gets accepted. A git repository is up too.
{kind=link}
If you want to try it out with LDC, you have to put the files into the naive directory in tango/lib/gc and edit the file runtime/CMakeLists.txt and search/replace "basic" for "naive". Then you have to search for the line:
file(GLOB GC_D ${RUNTIME_GC_DIR}/*.d)
And replace it with:
file(GLOB GC_D ${RUNTIME_GC_DIR}/gc/*.d)
Comments and reviews are welcome, and please let me know if you try it =)
Immix mark-region garbage collector
by Leandro Lucarella on 2009- 04- 25 20:39 (updated on 2009- 04- 25 20:39)- with 0 comment(s)
Yesterday Fawzi Mohamed pointed me to a Tango forums post (<rant>god! I hate forums</rant> =) where Keith Nazworth announces he wants to start a new GC implementation in his spare time.
He wants to progressively implement the Immix Garbage Collector.
I read the paper and it looks interesting, and it looks like it could use the parallelization I plan to add to the current GC, so maybe our efforts can be coordinated to leave the possibility to integrate both improvements together in the future.
A few words about the paper: the heap organization is pretty similar to the one in the current GC implementation, except Immix proposes that pages should not be divided in fixed-size bins, but do pointer bump variable sized allocations inside a block. Besides that, all other optimizations that I saw in the paper are somehow general and can be applied to the current GC at some point (but some of them maybe don't fit as well). Among these optimizations are: opportunistic moving to avoid fragmentation, parallel marking, thread-local pools/allocator and generations. Almost all of the optimizations can be implemented incrementally, starting with a very basic collector which is not very far from the actual one.
There were some discussion on adding the necessary hooks to the language to allow a reference counting based garbage collector in the newsgroup (don't be fooled by the subject! Is not about disabling the GC =) and weak references implementation. There's a lot of discussion about GC lately in D, which is really exciting!
Guaranteed finalization support
by Leandro Lucarella on 2009- 04- 19 17:03 (updated on 2009- 04- 19 17:03)- with 0 comment(s)
There was some discussion going on about what I found in my previous post. Unfortunately the discussion diverged a lot, and lots of people seems to defend not guaranteed finalization for no reason, or arguing that finalization is supposed to be used with RAII.
I find all the arguments very weak, at least for convincing me that the current specs are not broken (if finalizers shouldn't be used with objects with its lifetime determined by the GC, then don't let that happen).
The current specs allow a D implementation with a GC that don't call finalizers for collected objects at all! So any D program relying on that is actually broken.
Anyways, from all the possible solutions to this problem, I think the better is just to provide guaranteed finalization, at least at program exit. That is doable (and easily doable by the way).
I filed a bug report about this, but unfortunately, seeing how the discussion at the news group went, I'm very skeptic about this being fixed at all.
Object finalization
by Leandro Lucarella on 2009- 04- 18 15:18 (updated on 2009- 04- 18 15:18)- with 0 comment(s)
I'm writing a trivial naive (but fully working) GC implementation. The idea is:
- Improve my understanding about how a GC is written from the ground up
- Ease the learning curve for other people wanting to learn how to write a D GC
- Serve as documentation (will be fully documented)
- Serve as a benchmarking base (to see how better is an implementation compared to the dumbest and simplest implementation ever =)
There is a lot of literature on GC algorithms, but there is almost no literature of the particularities on implementing a GC in D (how to handle the stack, how finalize an object, etc.). The idea of this GC implementation is to tackle this. The collection and allocation algorithms are really simple so you can pay attention to the other stuff.
The exercise is already paying off. Implementing this GC I was able to see some details I missed when I've done the analysis of the current implementation.
For example, I completely missed finalization. The GC stores for each cell a flag that indicates when an object should be finalized, and when the memory is swept it calls rt_finalize() to take care of the business. That was easy to add to my toy GC implementation.
Then I was trying to decide if all memory should be released when the GC is terminated or if I could let the OS do that. Then I remembered finalization, so I realized I should at least call the finalizers for the live objects. So I went see how the current implementation does that.
It turns out it just calls a full collection (you have an option to not collect at all, or to collect excluding roots from the stack, using the undocumented gc_setTermCleanupLevel() and gc_gsetTermCleanupLevel() functions). So if there are still pointers in the static data or in the stack to objects with finalizers, those finalizers are never called.
I've searched the specs and it's a documented feature that D doesn't guarantee that all objects finalizers get called:
The garbage collector is not guaranteed to run the destructor for all unreferenced objects. Furthermore, the order in which the garbage collector calls destructors for unreference objects is not specified. This means that when the garbage collector calls a destructor for an object of a class that has members that are references to garbage collected objects, those references may no longer be valid. This means that destructors cannot reference sub objects.
I knew that ordering was not guaranteed so you can't call other finalizer in a finalizer (and that make a lot of sense), but I didn't knew about the other stuff. This is great for GC implementors but not so nice for GC users ;)
I know that the GC, being conservative, has a lot of limitations, but I think this one is not completely necessary. When the program ends, it should be fairly safe to call all the finalizers for the live objects, referenced or not.
In this scheme, finalization is as reliable as UDP =)
Understanding the current GC, conclusion
by Leandro Lucarella on 2009- 04- 11 19:36 (updated on 2009- 04- 11 19:36)- with 0 comment(s)
Now that I know fairly deeply the implementation details about the current GC, I can compare it to the techniques exposed in the GC Book.
Tri-colour abstraction
Since most literature speaks in terms of the tri-colour abstraction, now it's a good time to translate how this is mapped to the D GC implementation.
As we all remember, each cell (bin) in D has several bits associated to them. Only 3 are interesting in this case:
- mark
- scan
- free (freebits)
So, how we can translate this bits into the tri-colour abstraction?
- Black
Cells that were marked and scanned (there are no pointer to follow) are coloured black. In D this cells has the bits:
mark = 1 scan = 0 free = 0
- Grey
Cells that has been marked, but they have pointers to follow in them are coloured grey. In D this cells has the bits:
mark = 1 scan = 1 free = 0
- White
Cells that has not been visited at all are coloured white (all cells should be colored white before the marking starts). In D this cells has the bits:
mark = 0 scan = X
Or:
free = 1
The scan bit is not important in this case (but in D it should be 0 because scan bits are cleared before the mark phase starts). The free bit is used for the cells in the free list. They are marked before other cells get marked with bits mark=1 and free=1. This way the cells in the free list don't get scanned (mark=1, scan=0) and are not confused with black cells (free=1), so they can be kept in the free list after the mark phase is done. I think this is only necessary because the free list is regenerated.
Improvements
Here is a summary of improvements proposed by the GC Book, how the current GC is implemented in regards to this improvements and what optimization opportunities can be considered.
Mark stack
The simplest version of the marking algorithm is recursive:
mark(cell)
if not cell.marked
cell.marked = true
for child in cell.children
mark(child)
The problem here is, of course, stack overflow for very deep heap graphs (and the space cost).
The book proposes using a marking stack instead, and several ways to handle stack overflow, but all these are only useful for relieving the symptom, they are not a cure.
As a real cure, pointer reversal is proposed. The idea is to use the very same pointers to store the mark stack. This is constant in space, and needs only one pass through the help, so it's a very tempting approach. The bad side is increased complexity and probably worse cache behavior (writes to the heap dirties the entire heap, and this can kill the cache).
Current implementation
The D GC implementation does none of this. Instead it completes the mark phase by traversing the heap (well, not really the heap, only the bit sets) in several passes, until no more data to scan can be found (all cells are painted black or white). While the original algorithm only needs one pass through the heap, this one need several. This trades space (and the complexity of stack overflow handling) for time.
Optimization opportunities
This seems like a fair trade-off, but alternatives can be explored.
Bitmap marking
The simplest mark-sweep algorithm suggests to store marking bits in the very own cells. This can be very bad for the cache because a full traversal should be done across the entire heap. As an optimization, a bitmap can be used, because they are much small and much more likely to fit in the cache, marking can be greatly improved using them.
Current implementation
Current implementation uses bitmaps for mark, scan, free and other bits. The bitmap implementation is GCBits and is a general approach.
The bitmap stores a bit for each 16 bytes chunks, no matter what cell size (Bins, or bin size) is used. This means that 4096/16 = 256 bits (32 bytes) are used for each bitmap for every page in the GC heap. Being 5 bitmaps (mark, scan, freebits, finals and noscan), the total spaces per page is 160 bytes. This is a 4% space overhead in bits only.
This wastes some space for larger cells.
Optimization opportunities
The space overhead of bitmaps seems to be fairly small, but each byte counts for the mark phase because of the cache. A heap with 64 MiB uses 2.5 MiB in bitmaps. Modern processors come with about that much cache, and a program using 64 MiB doesn't seems very rare. So we are pushing the limits here if we want our bitmaps to fit in the cache to speed up the marking phase.
I think there is a little room for improvement here. A big object, lets say it's 8 MiB long, uses 640 KiB of memory for bitmaps it doesn't need. I think some specialized bitmaps can be used for large object, for instance, to minimize the bitmaps space overhead.
There are some overlapping bits too. mark=0 and scan=1 can never happen for instance. I think it should be possible to use that combination for freebits, and get rid of an entire bitmap.
Lazy sweep
The sweep phase is done generally right after the mark phase. Since normally the collection is triggered by an allocation, this can be a little disrupting for the thread that made that allocation, that has to absorb all the sweeping itself.
Another alternative is to do the sweeping incrementally, by doing it lazy. Instead of finding all the white cells and linking them to the free list immediately, this is done on each allocation. If there is no free cells in the free list, a little sweeping is done until new space can be found.
This can help minimize pauses for the allocating thread.
Current implementation
The current implementation does an eager sweeping.
Optimization opportunities
The sweeping phase can be made lazy. The only disadvantage I see is (well, besides extra complexity) that could make the heap more likely to be fragmented, because consecutive requests are not necessarily made on the same page (a free() call can add new cells from another page to the free list), making the heap more sparse, (which can be bad for the cache too). But I think this is only possible if free() is called explicitly, and this should be fairly rare in a garbage collected system, so I guess this could worth trying.
Lazy sweeping helps the cache too, because in the sweep phase, you might trigger cache misses when linking to the free list. When sweeping lazily, the cache miss is delayed until it's really necessary (the cache miss will happen anyway when you are allocating the free cell).
Conclusion
Even when the current GC is fairly optimized, there is plenty of room for improvements, even preserving the original global design.
Understanding the current GC, the end
by Leandro Lucarella on 2009- 04- 11 04:46 (updated on 2009- 04- 15 04:10)- with 0 comment(s)
In this post I will take a closer look at the Gcx.mark() and Gcx.fullcollect() functions.
This is a simplified version of the mark algorithm:
mark(from, to)
changes = 0
while from < to
pool = findPool(from)
offset = from - pool.baseAddr
page_index = offset / PAGESIZE
bin_size = pool.pagetable[page_index]
bit_index = find_bit_index(bin_size, pool, offset)
if not pool.mark.test(bit_index)
pool.mark.set(bit_index)
if not pool.noscan.test(bit_index)
pool.scan.set(bit_index)
changes = true
from++
anychanges |= changes // anychanges is global
In the original version, there are some optimizations and the find_bit_index() function doesn't exist (it does some bit masking to find the right bit index for the bit set). But everything else is pretty much the same.
So far, is evident that the algorithm don't mark the whole heap in one step, because it doesn't follow pointers. It just marks a consecutive chunk of memory, assuming that pointers can be at any place in that memory, as long as they are aligned (from increments in word-sized steps).
fullcollect() is the one in charge of following pointers, and marking chunks of memory. It does it in an iterative way (that's why mark() informs about anychanges (when new pointer should be followed to mark them, or, speaking in the tri-colour abstraction, when grey cells are found).
fullcollect() is huge, so I'll split it up in smaller pieces for the sake of clarity. Let's see what are the basic blocks (see the second part of this series):
fullcollect()
thread_suspendAll()
clear_mark_bits()
mark_free_list()
rt_scanStaticData(mark)
thread_scanAll(mark, stackTop)
mark_root_set()
mark_heap()
thread_resumeAll()
sweep()
Generaly speaking, all the functions that have some CamelCasing are real functions and the ones that are all_lowercase and made up by me.
Let's see each function.
- thread_suspendAll()
- This is part of the threads runtime (found in src/common/core/thread.d). A simple peak at it shows it uses SIGUSR1 to stop the thread. When the signal is caught it pushes all the registers into the stack to be sure any pointers there are scanned in the future. The threads waits for SIGUSR2 to resume.
- clear_mark_bits()
foreach pool in pooltable pool.mark.zero() pool.scan.zero() pool.freebits.zero()- mark_free_list()
foreach n in B_16 .. B_PAGE foreach node in bucket pool = findPool(node) pool.freebits.set(find_bit_index(pool, node)) pool.mark.set(find_bit_index(pool, node))- rt_scanStaticData(mark)
- This function, as the name suggests, uses the provided mark function callback to scan the program's static data.
- thread_scanAll(mark, stackTop)
- This is another threads runtime function, used to mark the suspended threads stacks. I does some calculation about the stack bottom and top, and calls mark(bottom, top), so at this point we have marked all reachable memory from the stack(s).
- mark_root_set()
mark(roots, roots + nroots) foreach range in ranges mark(range.pbot, range.ptop)- mark_heap()
This is where most of the marking work is done. The code is really ugly, very hard to read (mainly because of bad variable names) but what it does it's relatively simple, here is the simplified algorithm:
// anychanges is global and was set by the mark()ing of the // stacks and root set while anychanges anychanges = 0 foreach pool in pooltable foreach bit_pos in pool.scan if not pool.scan.test(bit_pos) continue pool.scan.clear(bit_pos) // mark as already scanned bin_size = find_bin_for_bit(pool, bit_pos) bin_base_addr = find_base_addr_for_bit(pool, bit_pos) if bin_size < B_PAGE // small object bin_top_addr = bin_base_addr + bin_size else if bin_size in [B_PAGE, B_PAGEPLUS] // big object page_num = (bin_base_addr - pool.baseAddr) / PAGESIZE if bin == B_PAGEPLUS // search for the base page while pool.pagetable[page_num - 1] != B_PAGE page_num-- n_pages = 1 while page_num + n_pages < pool.ncommitted and pool.pagetable[page_num + n_pages] == B_PAGEPLUS n_pages++ bin_top_addr = bin_base_addr + n_pages * PAGESIZE mark(bin_base_addr, bin_top_addr)The original algorithm has some optimizations for proccessing bits in clusters (skips groups of bins without the scan bit) and some kind-of bugs too.
Again, the functions in all_lower_case don't really exist, some pointer arithmetics are done in place for finding those values.
Note that the pools are iterated over and over again until there are no unvisited bins. I guess this is a fair price to pay for not having a mark stack (but I'm not really sure =).
- thread_resumeAll()
- This is, again, part of the threads runtime and resume all the paused threads by signaling a SIGUSR2 to them.
- sweep()
mark_unmarked_free() rebuild_free_list()
- mark_unmarked_free()
This (invented) function looks for unmarked bins and set the freebits bit on them if they are small objects (bin size smaller than B_PAGE) or mark the entire page as free (B_FREE) in case of large objects.
This step is in charge of executing destructors too (through rt_finalize() the runtime function).
- rebuild_free_list()
This (also invented) function first clear the free list (bucket) and then rebuild it using the information collected in the previous step.
As usual, only bins with size smaller than B_PAGE are linked to the free list, except if the pages they belong to have all the bins freed, in which case the page is marked with the special B_FREE bin size. The same goes for big objects freed in the previous step.
I think rebuilding the whole free list is not necessary, the new free bins could be just linked to the existing free list. I guess this step exists to help reducing fragmentation, since the rebuilt free list group bins belonging to the same page together.
Understanding the current GC, part IV
by Leandro Lucarella on 2009- 04- 10 21:33 (updated on 2009- 04- 10 21:33)- with 0 comment(s)
What about freeing? Well, is much simpler than allocation =)
GC.free(ptr) is a thread-safe wrapper for GC.freeNoSync(ptr).
GC.freeNoSync(ptr) gets the Pool that ptr belongs to and clear its bits. Then, if ptr points to a small object (bin size smaller than B_PAGE), it simply link that bin to the free list (Gcx.bucket). If ptr is a large object, the number of pages used by the object is calculated then all the pages marked as B_FREE (done by Pool.freePages(start, n_pages)).
Then, there is reallocation, which is a little more twisted than free, but doesn't add much value to the analysis. It does what you think it should (maybe except for a possible bug) using functions already seen in this post or in the previous ones.
Understanding the current GC, part III
by Leandro Lucarella on 2009- 04- 10 05:28 (updated on 2009- 04- 10 05:28)- with 0 comment(s)
In the previous post we focused on the Gcx object, the core of the GC in druntime (and Phobos and Tango, they are all are based on the same implementation). In this post we will focus on allocation, which a little more complex than it should be in my opinion.
It was not an easy task to follow how allocation works. A GC.malloc() call spawns into this function calls:
GC.malloc(size, bits)
|
'---> GC.mallocNoSync(size, bits)
|
|---> Gcx.allocPage(bin_size)
| |
| '---> Pool.allocPages(n_pages)
| |
| '---> Pool.extendPages(n_pages)
| |
| '---> os_mem_commit(addr, offset, size)
|
|---> Gcx.fullcollectshell()
|
|---> Gcx.newPool(n_pages)
| |
| '---> Pool.initialize(n_pages)
| |
| |---> os_mem_map(mem_size)
| |
| '---> GCBits.alloc(bits_size)
|
'---> Gcx.bigAlloc(size)
|
|---> Pool.allocPages(n_pages)
| '---> (...)
|
|---> Gcx.fullcollectshell()
|
|---> Gcx.minimize()
| |
| '---> Pool.Dtor()
| |
| |---> os_mem_decommit(addr, offset, size)
| |
| |---> os_mem_map(addr, size)
| |
| '---> GCBits.Dtor()
|
'---> Gcx.newPool(n_pages)
'---> (...)
Doesn't look so simple, ugh?
The map/commit differentiation of Windows doesn't exactly help simplicity. Note that Pool.initialize() maps the memory (reserve the address space) while Pool.allocPages() (through Pool.extendPages()) commit the new memory (ask the OS to actually reserve the virtual memory). I don't know how good is this for Windows (or put in another way, how bad could it be for Windows if all mapped memory gets immediately committed), but it adds a new layer of complexity (that's not even needed in Posix OSs). The whole branch starting at Gcx.allocPage(bin_size) would be gone if this distinction it's not made. Besides this, it worsen Posix OSs performance, because there are some non-trivial lookups to handle this non-existing non-committed pages, even when the os_mem_commit() and os_mem_decommit() functions are NOP and can be optimized out, the lookups are there.
Mental Note
See if getting rid of the commit()/decommit() stuff improves Linux performance.
But well, let's forget about this issue for now and live with it. Here is a summary of what all this functions do.
Note
I recommend to give another read to the (updated) previous posts of this series, specially if you are not familiar with the Pool concept and implementation.
- GC.malloc(size, bits)
- This is just a wrapper for multi-threaded code, it takes the GCLock if necessary and calls GC.mallocNoSync(size, bits).
- GC.mallocNoSync(size, bits)
This function has 2 different algorithms for small objects (less than a page of 4KiB) and another for big objects.
It does some common work for both cases, like logging and adding a sentinel for debugging purposes (if those feature are enabled), finding the bin size (bin_size) that better fits size (and cache the result as an optimization for consecutive calls to malloc with the same size) and setting the bits (NO_SCAN, NO_MOVE, FINALIZE) to the allocated bin.
- Small objects (bin_size < B_PAGE)
- Looks at the free list (Gcx.bucket) trying to find a page with the minimum bin size that's equals or bigger than size. If it can't succeed, it calls Gcx.allocPage(bin_size) to find room in uncommitted pages. If there still no room for the requested amount of memory, it triggers a collection (Gcx.fullcollectshell()). If there is still no luck, Gcx.newPage(1) is called to ask the OS for more memory. Then it calls again Gcx.allocPage(bin_size) (remember the new memory is just mmap'ped but not commit'ed) and if there is no room in the free list still, an out of memory error is issued.
- Big objects (B_PAGE and B_PAGEPLUS)
- It simply calls Gcx.bigAlloc(size) and issue an out of memory error if that call fails to get the requested memory.
- Gcx.allocPage(bin_size)
- This function linearly search the pooltable for a Pool with an allocable page (i.e. a page already mapped by not yet committed). This is done through a call to Pool.allocPages(1). If a page is found, its bin size is set to bin_size via the Pool's pagetable, and all the bins of that page are linked to the free list (Gcx.bucket).
- Pool.allocPages(n_pages)
- Search for n_pages consecutive free pages (B_FREE) in the committed pages (pages in the pagetable with index up to ncommited). If they're not found, Pool.extendPages(n_pages) is called to commit some more mapped pages to fulfill the request.
- Pool.extendPages(n_pages)
- Commit n_pages already mapped pages (calling os_mem_commit()), setting them as free (B_FREE) and updating the ncommited attribute. If there are not that many uncommitted pages, it returns an error.
- Gcx.newPool(n_pages)
- This function adds a new Pool to the pooltable. It first adjusts the n_pages variable using various rules (for example, it duplicates the current allocated memory until 8MiB are allocated and then allocates 8MiB pools always, unless more memory is requested in the first place, of course). Then a new Pool is created with the adjusted n_pages value and it's initialized calling to Pool.initialize(n_pages), the pooltable is resized to fit the new number of pools (npools) and sorted using Pool.opCmp() (which uses the baseAddr to compare). Finally the minAddr and maxAddr attributes are updated.
- Pool.initialize(n_pages)
- Initializes all the Pool attributes, mapping the requested number of pages (n_pages) using os_mem_map(). All the bit sets (mark, scan, freebits, noscan) are allocated (using GCBits.alloc()) to n_pages * PAGESIZE / 16 bits and the pagetable too, setting all bins to B_UNCOMMITTED and ncommitted to 0.
- Gcx.bigAlloc(size)
This is the weirdest function by far. There are very strange things, but I'll try to explain what I understand from it (what I think it's trying to do).
It first make a simple lookup in the pooltable for n_pages consecutive pages in any existing Pool (calling Pool.allocPages(n_pages) as in Gcx.allocPage()). If this fails, it runs a fullcollectshell() (if not disabled) then calls to minimize() (to prevent bloat) and then create a new pool (calling newPool() followed by Pool.allocPages()). If all that fails, it returns an error. If something succeed, the bin size for the first page is set to B_PAGE and the remaining pages are set to B_PAGEPLUS (if any). If there is any unused memory at the end, it's initialized to 0 (to prevent false positives when scanning I guess).
The weird thing about this, is that a lot of lookups into the pooltable are done in certain condition, but I think they are not needed because there are no changes that can make new room.
I don't know if this is legacy code that never got updated and have a lot of useless lookups or if I'm getting something wrong. Help is welcome!
There is not much to say about os_mem_xxx(), Gcx.minimize() and Gcx.fullcollectshell() functions, they were briefly described in the previous posts of this series. Pool.Dtor() just undo what was done in Pool.initialize().
A final word about the free list (Gcx.bucket). It's just a simple linked list. It uses the first size_t bytes of the free bin to point to the next free bin (there's always room for a pointer in a bin because their minimum size is 16 bytes). A simple structure is used to easy this:
struct List {
List *next;
}
Then, the memory cell is casted to this structure to use the next pointer, like this:
p = gcx.bucket[bin] gcx.bucket[bin] = (cast(List*) p).next
I really have my doubts if this is even a little less cryptic than:
p = gcx.bucket[bin] gcx.bucket[bin] = *(cast(void**) p)
But what the hell, this is no really important =)
Understanding the current GC, part II
by Leandro Lucarella on 2009- 04- 06 00:00 (updated on 2009- 04- 15 04:10)- with 0 comment(s)
Back to the analysis of the current GC implementation, in this post I will focus on the Gcx object structure and methods.
Gcx attributes
- Root set
- roots (nroots, rootdim)
- An array of root pointers.
- ranges (nranges, rangedim)
- An array of root ranges (a range of memory that should be scanned for root pointers).
- Beginning of the stack (stackBottom)
- A pointer to the stack bottom (assuming it grows up).
- Pool table (pooltable, npools)
- An array of pointers to Pool objects (the heap itself).
- Free list (bucket)
- A free list for each Bins size.
- Internal state
- anychanges
- Set if the marking of a range has actually marked anything (and then using in the full collection.
- inited
- Set if the GC has been initialized.
- Behaviour changing attributes
- noStack
- Don't scan the stack if activated.
- log
- Turn on logging if activated.
- disabled
- Don't run the collector if activated.
- Cache (for optimizations and such)
- p_cache, size_cache
- Querying the size of a heap object is an expensive task. This caches the last query as an optimization.
- minAddr, maxAddr
- All the heap is in this range. It's used as an optimization when looking if a pointer can be pointing into the heap (if the pointer is not in this range it can be safely discarded, but if it's in the range, a full search in the pooltable should be done).
Gcx main methods
- initialize()
- Initialization, set the Gcx object attributes to 0, except for the stackBottom (which is set to the address of a dummy local variable, this works because this function is one of the first functions called by the runtime) and the inited flag, that is set to 1. The log is initialized too.
- Dtor()
- Destruction, free all the memory.
- Root set manipulation
- addRoot(p), removeRoot(p), rootIter(dg)
- Add, remove and iterate over single root pointers.
- addRange(pbot, ptop), remove range(pbot), rangeIter(dg)
- Add, remove and iterate over root pointer ranges. This methods are almost the same as the previous ones, so the code duplication here can be improved here.
- Flags manipulation
Each Bin has some flags associated (as explained before). With this functions the user can manipulate some of them:
- FINALIZE: this pool has destructors to be called (final flag)
- NO_SCAN: this pool should not be scanned for pointers (noscan flag)
- NO_MOVE: this pool shouldn't be moved (not implemented)
- getBits(pool, biti)
- Get which of the flags specified by biti are set for the pool Pool.
- setBits(pool, mask)
- Set the flags specified by mask for the pool Pool.
- clrBits(pool, mask)
- Clear the flags specified by mask for the pool Pool.
- Searching
- findPool(p)
- Find the Pool object that pointer p is in.
- findBase(p)
- Find the base address of block containing pointer p.
- findSize(p)
- Find the size of the block pointed by p.
- getInfo(p)
- Get information on the pointer p. The information is composed of: base (the base address of the block), size (the size of the block) and attr (the flags associated to the block, as shown in Flag manipulation). This information is returned as a structure called the BlkInfo.
- findBin(size)
- Compute Bins (bin size) for an object of size size.
- Heap (pagetable) manipulation
The pooltable is kept sorted always.
- reserve(size)
- Allocate a new Pool of at least size bytes.
- minimize()
- Minimizes physical memory usage by returning free pools to the OS.
- bigAlloc(size)
- Allocate a chunk of memory that is larger than a page.
- newPool(npages)
- Allocate a new Pool with at least npages pages in it.
- allocPage(bin)
- Allocate a page of bin size.
- Collection
- mark(pbot, ptop)
This is the mark phase. It search a range of memory values and mark any pointers into the GC heap. The mark bit is set, and if the noscan bit is unset, the scan bit is activated (indicating that the block should be scanned for pointers, equivalent to coloring the cell grey in the tri-colour abstraction).
The mark phase is not recursive (nor a mark stack is used). Only the passed range is marked, pointers are not followed here.
That's why the anychanges flag is used, if anything has got marked, anychanges is set to true. The marking phase is done iteratively until no more blocks are marked, in which case we can safely assume that we marked all the live blocks.
- fullcollectshell()
- The purpose of the shell is to ensure all the registers get put on the stack so they'll be scanned.
- fullcollect(stackTop)
Collect memory that is not referenced by the program. The algorithm is something like this:
- Stop the world (all other threads)
- Clear all the mark/scan bits in the pools
- Manually mark each free list entry (bucket), so it doesn't get scanned
- mark() the static data
- mark() stacks and registers for each paused thread
- mark() the root set (both roots and ranges)
- mark() the heap iteratively until no more changes are detected (anychanges is false)
- Start the world (all other threads)
- Sweep (free up everything not marked)
- Free complete pages, rebuild free list
Note
This is a very summarized version of the algorithm, what I could understand from a quick look into the code, which is pretty much undocumented. A deeper analysis should be done in a following post.
TODO list
by Leandro Lucarella on 2009- 04- 05 06:42 (updated on 2009- 04- 05 06:42)- with 0 comment(s)
I've activated the issue tracker module in my D Garbage Collector Research project to be able to track my TODO list.
This is probably useful just for me, but maybe you can be interested in knowing what I will do next =)
GC optimization for contiguous pointers to the same page
by Leandro Lucarella on 2009- 04- 01 23:41 (updated on 2009- 04- 01 23:41)- with 0 comment(s)
This optimization had a patch, written by Vladimir Panteleev, sitting on Bugzilla (issue #1923) for a little more than an year now. It was already included in both Tango (issue #982) and DMD 2.x but DMD 1.x was missing it.
Fortunately is now included in DMD 1.042, released yesterday.
This optimization is best seen when you do word splitting of a big text (as shown in the post that triggered the patch):
import std.file, std.string;
void main() {
auto txt = cast(string) read("text.txt"); // 6.3 MiB of text
auto words = txt.split();
}
Now in words we have an array of slices (a contiguous area in memory filled with pointers) about the same size of the original text, as explained by Vladimir.
The GC heap is divided in (4KiB) pages, each page contains cells of a fixed type called bins. There are bin sizes of 16 (B_16) to 4096 (B_PAGE), incrementing in steps of power of 2 (32, 64, etc.). See Understanding the current GC for more details.
For large contiguous objects (like txt in this case) multiple pages are needed, and that pages contains only one bin of size B_PAGEPLUS, indicating that this object is distributed among several pages.
Now, back with the words array, we have a range of about 3 millions interior pointers into the txt contiguous memory (stored in about 1600 pages of bins with size B_PAGEPLUS). So each time the GC needs to mark the heap, it has to follow this 3 millions pointers and find out where is the beginning of that block to see its mark-state (if it's marked or not). Finding the beginning of the block is not that slow, but when you multiply it by 3 millions, it could get a little noticeable. Specially when this is done several times as the dynamic array of words grow and the GC collection is triggered several times, so this is kind of exponential.
The optimization consist in remembering the last page visited if the bin size was B_PAGE or B_PAGEPLUS, so if the current pointer being followed points to the last visited (cached) page, we can skip this lookup (and all the marking indeed, as we know we already visited that page).
Mercurial is not good enough
by Leandro Lucarella on 2009- 04- 01 02:55 (updated on 2009- 04- 01 02:55)- with 0 comment(s)
I started learning some Mercurial for interacting with the LDC repository, but I disliked it instantly. Sure, it's great when you come from SVN, but it's just too limited if you come from GIT (I can't live anymore without git rebase -i).
Fortunately there is fast-export. With it I can incrementally import the Mercurial repository in a GIT repository as easy as:
hg clone http://hg.dsource.org/projects/ldc ldc-hg mkdir ldc cd ldc git init hg-fast-export.sh -r my_local_hg_repo_clone
I'm very happy to be at home again =)
LDC
by Leandro Lucarella on 2009- 03- 29 18:56 (updated on 2009- 03- 29 18:56)- with 0 comment(s)
My original plan was to use GDC as my compiler of choice. This was mainly because DMD is not free and there is a chance that I need to put my hands in the compiler guts.
This was one or two years ago, now the situation has changed a lot. GDC is dead (there was no activity for a long time, and this added to the fact that GCC hacking is hard, it pretty much removes GDC from the scene for me).
OTOH, DMD now provides full source code of the back-end (the front-end was released under the GPL/Artistic licence long ago), but the license is really unclear about what can you do with it. Most of the license mostly tell you how you can never, never, never sue Digital Mars, but about what you can actually do, it's says almost nothing:
The Software is copyrighted and comes with a single user license, and may not be redistributed. If you wish to obtain a redistribution license, please contact Digital Mars.
You can't redistribute it, that's for sure. It says nothing about modifications. Anyways, I don't think Walter Bright mind to give me permission to modify it and use it for my personal project, but I prefer to have a software with a better license to work with (and I never was a big fan of Walter's coding either, so =P).
Fortunately there is a new alternative now: LDC. You should know by now that LDC is the DMD front-end code glued to the LLVM back-end, that there is an alpha release (with much of the main functionality finished), that it's completely FLOSS and that it's moving fast and getting better every day (a new release is coming soon too).
I didn't play with LLVM so far, but all I hear about it is that's a nice, easy to learn and work, compiler framework that is widely used, and getting better and better very fast too.
To build LDC just follow the nice instructions (I'm using Debian so I just had to aptitude install cmake cmake-curses-gui llvm-dev libconfig++6-dev mercurial and go directly to the LDC specific part). Now I just have to learn a little about Mercurial (coming from GIT it shouldn't be too hard), and maybe a little about LLVM and I'm good to go.
So LDC is my compiler of choice now. And it should be yours too =)
Collected newsgroup links
by Leandro Lucarella on 2009- 03- 29 04:05 (updated on 2009- 03- 29 04:05)- with 0 comment(s)
I've been monitoring and saving interesting (GC related mostly) posts from the D newsgroups. I saved all in a plain text file until today that I decided to add them to a page.
Please feel free to add any missing post that include interesting GC-related discussions.
Thanks!
D GC Benchmark Suite
by Leandro Lucarella on 2009- 03- 28 18:31 (updated on 2009- 03- 28 18:31)- with 0 comment(s)
I'm trying to make a benchmark suite to evaluate different GC implementations.
What I'm looking for is:
- Trivial benchmarks that stress corner cases or very specific scenarios. For example, I collected a few of this posted in the NG and other sources in the couple last years (most showing problems already solved):
- Working real-life programs, specially if they are GC-intensive (for example programs where pause times are a problem and they are visible to the user) and they are easy to get timings for (but not limited to that). Programs should be opensource in principle, but if they are not please contact me if you are willing to lend me the code for this research at least. I don't know yet if I will be targeting D1, D2 or both (probably D1), so feel free to submit anything. The only condition is the program should compile (and work) with the latest compiler/Tango versions.
Feel free to post trivial test or links to programs projects as comments or via e-mail.
Thanks!
Accurate Garbage Collection in an Uncooperative Environment
by Leandro Lucarella on 2009- 03- 21 20:23 (updated on 2009- 03- 22 03:05)- with 0 comment(s)
I just read Accurate Garbage Collection in an Uncooperative Environment paper.
Unfortunately this paper try to solve mostly problems D don't see as problems, like portability (targeting languages that emit C code instead of native machine code, like the Mercury language mentioned in the paper). Based on the problem of tracing the C stack in a portable way, it suggests to inject some code to functions to construct a linked list of stack information (which contains local variables information) to be able to trace the stack in an accurate way.
I think none of the ideas presented by this paper are suitable for D, because the GC already can trace the stack in D (in an unportable way, but it can), and it can get the type info from better places too.
In terms of (time) performance, benchmarks shows that is a little worse than Boehm (et al) GC, but they argue that Boehm has years of fine grained optimizations and it's tightly coupled with the underlying architecture while this new approach is almost unoptimized yet and it's completely portable.
The only thing it mentions that could apply to D (and any conservative GC in general) is the issues that compiler optimizations can introduce. But I'm not aware of any of this issues, so I can't say anything about it.
In case you wonder, I've added this paper to my papers playground page =)
Update
I think I missed the point with this paper. Current D GC can't possibly do accurate tracing of the stack, because there is no way to get a type info from there (I was thinking only in the heap, where some degree of accuracy is achieved by setting the noscan bit for a bin that don't have pointers, as mentioned in my previous post).
So this paper could help getting accurate GC into D, but it doesn't seems a great deal when you can add type information about local variables when emitting machine code instead of adding the shadow stack linked list. The only advantage I see is that I think it should be possible to implement the linked list in the front-end.
Understanding the current GC
by Leandro Lucarella on 2009- 01- 04 20:37 (updated on 2009- 04- 09 22:53)- with 1 comment(s)
Oh, yeah! A new year, a new air, and the same thesis =)
After a little break, I'm finally starting to analyze the current D (druntime) GC (basic) implementation in depth.
First I want to say I found the code really, but really, hard to read and follow. Things are split in several parts without apparent reason, which make it really hard to understand and it's pretty much undocumented.
I hope I can fully understand it in some time to be able to make a full rewrite of it (in a first pass, conserving the main design).
Overview
I'll start with a big picture overview, and then I'll try to describe each component with more detail.
The implementation in split in several files:
- gcstats.d
- I didn't took a look at this one yet, but I guess it's about stats =).
- gcbits.d
- A custom bitset implementation for collector bit/flags (mark, scan, etc.).
- gcalloc.d
- A wrapper for memory allocation with several versions (malloc, win32, mmap and valloc). 4 functions are provided: map, unmap, commit and decommit. The (de)commit stuff if because (in Sean Kelly's words) Windows has a 2-phase allocation process. You can reserve the address space via map and unmap, but the virtual memory isn't actually created until you call commit. So decommit gets rid of the virtual memory but retains ownership of the address space.
- gcx.d
- The real GC implementation, split in 2 main classes/structs: GC and Gcx. GC seems to be a thin wrapper over Gcx that only provides the allocation logic (alloc/realloc/free) and Gcx seems to be the responsible for the real GC work (and holding the memory).
- gc.d
- This is just a thin wrapper over gcx.d to adapt it to the druntime GC interface.
The Gcx struct is where most magic happens. It holds the GC memory organized in pools. It holds the information about roots, the stack and free list, but in this post I'll focus in the memory pools:
Pool Concept
A pool is a group of pages, each page has a bin size (Bins) and host a fixed number of bins (PAGESIZE / Bins, for example, if Bins == 1024 and PAGESIZE == 4096, the page holds 4 bins).
Each bin has some bits of information:
- mark
- Setted when the Bin is visited by the mark phase.
- scan
- Setted when the Bin is has been visited by the mark phase (the mark bit is set) but it has pointers yet to be scanned.
- free
- Setted when the Bin is free (linked to a free list).
- final
- The object stored in this bin has a destructor that must be called when freed.
- noscan
- This bin should be not scanned by the collector (it has no pointers).
+----------------------------------------+-----+-----------------+ | Page 0 (bin size: Bins) | ... | Page (npages-1) | | | | | | +--------+-----+---------------------+ | | | | | Bin 0 | ... | Bin (PAGESIZE/Bins) | | | | | +--------+-----+---------------------+ | | | | | mark | ... | | | | | | | scan | ... | | | | ... | | | free | ... | ... | | | | | | final | ... | | | | | | | noscan | ... | | | | | | +--------+-----+---------------------+ | | | +----------------------------------------+-----+-----------------+
Pool Implementation
A single chunk of memory is allocated for the whole pool, the baseAddr points to the start of the chunk, the topAddr, to the end. A pagetable holds the bin size (Bins) of each page
. ,-- baseAddr topAddr --,
| ncommitted = i |
| |
|--- committed pages ---,------ uncommitted pages -------|
V | V
+--------+--------+-----+--------+-----+-----------------+
memory | Page 0 | Page 1 | ... | Page i | ... | Page (npages-1) |
+--------+--------+-----+--------+-----+-----------------+
/\ /\ /\ /\ /\ /\
|| || || || || ||
+--------+--------+-----+--------+-----+-----------------+
pagetable | Bins 0 | Bins 1 | ... | Bins i | ... | Bins (npages-1) |
(bin size) +--------+--------+-----+--------+-----+-----------------+
The bin size can be one of:
- B_XXX
- The XXX is a power of 2 from 16 to 4096. The special name B_PAGE is used for the size 4096.
- B_PAGEPLUS
- The whole page is a continuation of a large object (the first page of a large object has size B_PAGE).
- B_FREE
- The page is completely free.
- B_UNCOMMITED
- The page is not committed yet.
- B_MAX
- Not really a value, used for iteration or allocation. Pages can't have this value.
The information bits are stored in a custom bit set (GCBits). npages * PAGESIZE / 16 bits are allocated (since the smallest bin is 16 bytes long) and each bit is addressed using this formula:
bit(pointer) = (pointer - baseAddr) / 16
This means that a bit is reserved each 16 bytes. For large bin sizes, a lot of bits are wasted.
The minimum pool size is 256 pages. With 4096 bytes pages, that is 1 MiB.
The GCBits implementation deserves another post, it's a little complex and I still don't understand why.
druntime developers FAQ
by Leandro Lucarella on 2008- 12- 05 11:38 (updated on 2008- 12- 05 11:38)- with 0 comment(s)
Improved druntime getting started documentation
by Leandro Lucarella on 2008- 12- 02 23:07 (updated on 2008- 12- 02 23:07)- with 0 comment(s)
I've expanded the druntime Getting Started documentation. I basically added all the information I've posted in this blog so far: how to change the GC implementation and rebuild phobos.
Testing druntime modifications
by Leandro Lucarella on 2008- 11- 30 03:51 (updated on 2008- 11- 30 03:51)- with 0 comment(s)
Now that we can compile druntime, we should be able to compile some programs that use our fresh, modified, druntime library.
Since DMD 2.021, druntime is built into phobos, so if we want to test some code we need to rebuild phobos too, to include our new druntime.
Since I'm particularly interested in the GC, let's say we want to use the GC stub implementation (instead of the basic default).
We can add a simple "init" message to see that something is actually happening. For example, open src/gc/stub/gc.d and add this import:
private import core.sys.posix.unistd: write;
Then, in the gc_init() function add this line:
write(1, "init\n".ptr, 5);
Now, we must tell druntime we want to use the stub GC implementation. Edit dmd-posix.mak, search for DIR_GC variable and change it from basic to stub:
DIR_GC=gc/stub
Great, now recompile druntime.
Finally, go to your DMD installation, and edit src/phobos/linux.mak. Search for the DRUNTIME variable and set it to the path to your newly generated libdruntime.a (look in the druntime lib directory). For me it's something like:
DRUNTIME=/home/luca/tesis/druntime/lib/libdruntime.a
Now recompile phobos. I have to do this, because my DMD compiler is named dmd2:
make -f linux.mak DMD=dmd2
Now you can compile some trivial D program (compile it in the src druntime directory so its dmd.conf is used to search for the libraries and imports) and see how "init" get printed when the program starts. For example:
druntime/src$ cat hello.d
import core.sys.posix.unistd: write;
void main()
{
write(1, "hello!\n".ptr, 7);
}
druntime/src$ dmd2 -L-L/home/luca/tesis/dmd2/lib hello.d
druntime/src$ ./hello
init
hello!
Note that I passed my DMD compiler's lib path so it can properly find the newly created libphobos2.a.
druntime build system
by Leandro Lucarella on 2008- 11- 26 02:28 (updated on 2008- 11- 26 02:28)- with 0 comment(s)
I have to be honest on this one. I'm not crazy about the druntime build system. I know there are a lot of other more important thing to work on, but I can't help myself, and if I'm not comfortable with the build system, I get too much distracted, so I have no choice but to try to improve it a little =)
First, I don't like the HOME environment variable override hack in build-dmd.sh (I won't talk about the Windows build because I don't have Windows, so I can't test it).
So I've made a simple patch to tackle this. It just adds a dmd.conf configuration file in each directory owning a makefile. I think it's a fair price to pay adding this extra files to be hable to just use make and get rid of the build-dmd.sh script.
I've added a ticket on this and another related ticket with a patch too.
Getting started with druntime
by Leandro Lucarella on 2008- 11- 25 02:27 (updated on 2008- 11- 25 02:27)- with 0 comment(s)
I've added a brief draft about how to get started in the druntime wiki, which I plan to expand a little in the future.
I hope somebody find it useful.
BTW, the -version=Posix fix is now included in the main repo.
My druntime repository
by Leandro Lucarella on 2008- 11- 24 02:17 (updated on 2008- 11- 24 02:17)- with 0 comment(s)
I've finally published my own git druntime repository. It has both branches, the one for D2 (the svn trunk, called master in my repo) and the one for D1 (D1.0 in svn, d1 in my repo).
For now, there are only changes in the master branch.
Hacking druntime
by Leandro Lucarella on 2008- 11- 22 16:38 (updated on 2009- 03- 28 20:17)- with 0 comment(s)
I've been reading the source code of the druntime, and it's time to get my hands dirty and do some real work.
First I have to do to start hacking it is build it and start trying things out. There is no documentation at all yet, so I finally bothered Sean Kelly and asked him how to get started.
Here is what I had to do to get druntime compiled:
First of all, I'll introduce my environment and tools. I'll use DMD because there's no other option for now (druntime doesn't have support for GDC, but Sean says it's coming soon, and LDC will not be included until the support it's added to Tango runtime).
The trunk in the druntime repository is for D2, but there is a branch for D1 too.
I use Debian (so you'll see some apt stuff here) and I love git, and there's is no way I will go back to subversion. Fortunately there is git-svn, so that's what I'm gonna use =)
Now, what I did step by step.
Get the git goodies:
sudo aptitude install git-core git-svn
Make a directory where to put all the D-related stuff:
mkdir ~/d cd ~/d
Get D2 (bleeding edge version) and unpack it:
wget http://ftp.digitalmars.com/dmd.2.026.zip unzip dmd.2.020.zip # "install" the D2 compiler rm -fr dm dmd/linux/bin/{sc.ini,readme.txt,*.{exe,dll,hlp}} # cut the fat chmod a+x dmd/linux/bin/{dmd,rdmd,dumpobj,obj2asm} # make binaries executable mv dmd dmd2 # reserve the dmd directory for D1 compilerMake it accessible, for example:
echo '#!/bin/sh' > ~/bin/dmd2 # reserve dmd name for the D1 compiler echo 'exec ~/d/dmd2/linux/bin/dmd "$@"' >> ~/bin/dmd2 chmod a+x ~/bin/dmd2
Get D1 and install it too:
wget http://ftp.digitalmars.com/dmd.1.041.zip unzip dmd.1.036.zip rm -fr dm dmd/linux/bin/{sc.ini,readme.txt,*.{exe,dll,hlp}} chmod a+x dmd/linux/bin/{dmd,rdmd,dumpobj,obj2asm} echo '#!/bin/sh' > ~/bin/dmd echo 'exec ~/d/dmd/linux/bin/dmd "$@"' >> ~/bin/dmd chmod a+x ~/bin/dmdGet druntime for D1 and D2 as separated repositories (you can get all in one git repository using git branches but since I'll work on both at the same time I prefer to use two separated repositories):
git svn clone http://svn.dsource.org/projects/druntime/branches/D1.0 \ druntime git svn clone http://svn.dsource.org/projects/druntime/trunk druntime2
Build druntime for D1:
cd druntime bash build-dmd.sh cd -
Build druntime for D2.
This one is a little trickier. The trunk version have some changes for a feature that is not yet released (this being changed from a pointer to a reference for structs). Fortunately this is well isolated in a single commit, so reverting this change is really easy, first, get the abbreviated hash for the commit 44:
cd druntime2 git log --grep='trunk@44' --pretty=format:%h
This should give you a small string (mine is cae2326). Now, revert that change:
git revert cae2326
Done! You now have that change reverted, we can remove this new commit later when the new version of DMD that implements the this change appear.
But this is not all. Then I find a problem about redefining the Posix version:
Error: version identifier 'Posix' is reserved and cannot be set
To fix this you just have to remove the -version=Posix from build-dmd.sh.
But there is still one more problem, but this is because I have renamed the bianries to have both dmd and dmd2. The compiler we have to use to build things is called dmd2 for me, but build-dmd.sh don't override properly the DC environment variable when calling make, so dmd is used instead.
This is a simple and quick fix:
diff --git a/src/build-dmd.sh b/src/build-dmd.sh old mode 100644 new mode 100755 index d6be599..8f3b163 --- a/src/build-dmd.sh +++ b/src/build-dmd.sh @@ -11,9 +11,10 @@ goerror(){ exit 1 } -make clean -fdmd-posix.mak || goerror -make lib doc install -fdmd-posix.mak || goerror -make clean -fdmd-posix.mak || goerror +test -z "$DC" && DC=dmd +make DC=$DC clean -fdmd-posix.mak || goerror +make DC=$DC lib doc install -fdmd-posix.mak || goerror +make DC=$DC clean -fdmd-posix.mak || goerror chmod 644 ../import/*.di || goerror export HOME=$OLDHOME(to apply the patch just copy&paste it to fix.patch and then do git apply fix.patch; that should do the trick)
Now you can do something like this to build druntime for D2:
export DC=dmd2 bash build-dmd.sh
That's it for now. I'll be publishing my druntime (git) repository soon with this changes (and probably submitting some patches to upstream) so stay tuned ;)
Richard Jones GC book figures
by Leandro Lucarella on 2008- 10- 22 00:21 (updated on 2008- 10- 22 01:01)- with 0 comment(s)
Yesterday Richard Jones announced the publication of all the figures of the GC book he co-authored.
This is very nice news indeed =)
PS: Yes, I'm still alive, just very busy =( I took a look at the D's GC, but I'm waiting too for all the fuzz about the new druntime to settle a little to ask Sean Kelly some questions about it's internals
Mark-Sweep
by Leandro Lucarella on 2008- 09- 16 02:25 (updated on 2008- 09- 16 02:25)- with 0 comment(s)
After a busy week (unfortunately not working on my thesis), I'll move on to mark-sweep algorithms (I've covered the basic reference counting stuff for now).
The GC book start with some obvious optimizations about making the marking phase non recursive using an explicit stack and methods to handle stack overflow.
Since current D's GC is mark-sweep, I think I have to take a (deeper) look at it now, to see what optimizations is actually using (I don't think D GC is using the primitive recursive algorithm) and take that as the base ground to look for improvements.
The Python's algorithm
by Leandro Lucarella on 2008- 09- 08 02:05 (updated on 2008- 09- 08 02:05)- with 0 comment(s)
Python (at least CPython) uses reference counting, and since version 2.0 it includes a cycles freeing algorithm. It uses a generational approach, with 3 generations.
Python makes a distinction between atoms (strings and numbers mostly), which can't be part of cycles; and containers (tuples, lists, dictionaries, instances, classes, etc.), which can. Since it's unable to find all the roots, it keeps track of all the container objects (as a double linked list) and periodically look in them for cycles. If somebody survive the collection, is promoted to the next generation.
I think this works pretty well in real life programs (I never had problems with Python's GC -long pauses or such-, and I never heard complains either), and I don't see why it shouldn't work for D. Even more, Python have an issue with finalizers which don't exist in D because you don't have any warranties about finalization order in D already (and nobody seems to care, because when you need to have some order of finalization you should probably use some kind of RAII).
Partial mark and sweep cycle reclamation
by Leandro Lucarella on 2008- 09- 07 18:26 (updated on 2008- 09- 07 18:26)- with 0 comment(s)
This is a more polished version of the last idea about adding a backup tracing GC to collect cycles. We just trace the areas of the heap that can potentially store cycles (instead of tracing all the heap).
So, how do we know which areas may have cycles? When a reference counter is decremented, if it becomes zero, it can't possibly part of a cycle, but when the counter is decremented 1 or more, you never know. So the basics for the algorithm is to store cells which counters have been decremented to 1 or more, and then make a local (partial) mark and sweep to the cell accessible from it.
The trick is to use the reference counters. In the marking phase, the reference counters are decremented as the connectivity graph is traversed. When the marking phase is done, any cell with counter higher than zero is reference from outside the partial graph analyzed, so it must survive (as well as all the cells reachable from it).
Note
The worst case for a partial scan, is to scan the whole heap. But this should be extremely rare.
There are a lot of flavors of this algorithm, but all are based on the same principle, and most of the could be suitable for D.
Backup tracing collector for rc cycles reclamation
by Leandro Lucarella on 2008- 09- 07 04:05 (updated on 2009- 04- 02 21:42)- with 0 comment(s)
The simpler way to reclaim cycles is to use a backup tracing garbage collector. But this way, even when GC frequency could be much lower, the infomation of reference counters are not used, and pauses can be very long (depending on the backup algorithm used).
I think some kind of mixture between RC and tracing GC could be done so I wont discard this option just yet, but I think more specialized algorithms can do better in this case.
Discarded cycles reclamation algorithms
by Leandro Lucarella on 2008- 09- 07 03:50 (updated on 2008- 09- 07 03:50)- with 0 comment(s)
Finally, we address the cyclic structures reclaimation when doing reference counting. But I think there are some algorithms that are clearly unsuitable for D.
All the manual techniques (manually avoiding or breaking cycles or using weak pointers) are unacceptable, because it throws the problem again to the programmer. So I will consider only the options that keep the memory management automatic.
There are several specific cycles reclamation algorithms for functional languages too (like Friedman and Wise), but of course they are unsuitable for D because of the asumptios they make.
Bobrow proposed a general technique, in which a cyclic structure is reference counted as a whole (instead of reference counting their individual cells) but I find this impractical for D too, because it needs programmer intervention (marking "group" of cells).
ZCT and cycles
by Leandro Lucarella on 2008- 08- 30 16:08 (updated on 2008- 08- 30 16:08)- with 0 comment(s)
There's not much to think about it (I think ;).
ZCT doesn't help in cycles reclaiming, because ZCT tracks cells with zero count, and cycles can't possibly have a zero count (even using deferred reference counting), because they are, by definition, inter-heap pointers.
Let's see a simple example:
First, we have 3 heap cells, A pointed only by the (thus with rc 0 and added to the ZCT) and B pointed by A and in a cycle with C.
If sometime later, A stop pointing to B, the cycle B-C is not pointed by anything (the ZCT can't do anything about it either), so we lost track of the cycle.
Does this mean that deferred reference counting is useless? I think not. It could still be useful to do some kind of incremental garbage collection, minimizing pauses for a lot of cases. As long as the ZCT reconciliation can find free cells, the pauses of GC would be as short as tracing only the stack, which I think it would be pretty short.
Mental note
See how often cycles are found in tipical D programs.
If the ZCT reconciliation can't find free cells, a full collection should be triggered, using a tracing collector to inspect both the stack and the heap. Alternatively, one can a potential cycle table to store cells which rc has been decremented to a value higher than zero, and then just trace those cells to look for cycles, but we will see this algorithm in more detail in the future.
Avoiding counter updates
by Leandro Lucarella on 2008- 08- 25 03:44 (updated on 2008- 08- 25 03:44)- with 0 comment(s)
The main drawback of reference counting (leaving cycle aside) probably is high overhead it imposes into the client program. Every pointer update has to manipulate the reference counters, for both the old and the new objects.
Function calls
This includes every object passed as argument to a function, which one can guess it would be a lot (every method call for example). However, this kind of rc updates can be easily optimized away. Let's see an example:
class SomeClass
{
void some_method() {}
}
void some_function(SomeClass o)
{
o.some_method();
}
void main()
{
auto o = new SomeClass;
some_function(o);
}
It's clear that o should live until the end of main(), and that there is no chance o could be garbage collected until main() finishes. To express this, is enough to have o's rc = 1. There is no need to increment it when some_function() is called, nor when some_method() is called.
So, theoretically (I really didn't prove it =) is not necessary to update object's rc when used as arguments.
Local pointers update
What about pointers in the stack? Most of the time, pointers updates are done in local variables (pointers in the stack, not in the heap). The GC book talks about 99% of pointers update done in local variables for Lisp and ML. I don't think D could have that much but I guess it could be pretty high too.
Mental note
Gather some statistics about the number of local pointers update vs. heap pointers update in D
Fortunately Deutsch and Bobrow created an algorithm to completely ignore local pointers update, at the cost of relaying on some kind of tracing collector, but that only have to trace the stack (which should be pretty small compared to the heap).
What the algorithm proposes is to use simple assignment when updating local pointers. Pointers living in the heap manipulates rc as usual, but when the count drops to 0, the object is added to a zero count table (ZCT) (and removed if some pointer update increments the counter again).
Finally, at some point (usually when you run out of memory), the ZCT has to be reconciled, doing some simple steps: trace the stack looking for pointers and incrementing their counters and remove any object with rc = 0. Finally, decrement all the counters of the objects pointer to by the stack pointers.
This technique seems to be a good mix of both reference counting and tracing collectors: small pauses (the stack is usually small), low overhead for counter manipulation. The only missing point is cycles. At first sight, if we need a tracing collector for cycles, this algorithm seems pretty useless because you have to trace all the heap and stack to free cycles, so the optimization is lost. Big pauses are here again.
I have the feeling I'm missing something and the ZCT could be useful when comes to reclaim cycles, but I have to think a little more about that.
Lazy freeing RC
by Leandro Lucarella on 2008- 08- 19 02:31 (updated on 2008- 08- 19 02:31)- with 0 comment(s)
The first optimization to analyze is a very simple one. What's the idea behind it lazy freeing? Just transfer some of the work of freeing unused cells to the allocation, making the collection even more interleaved with the mutator.
When you delete a cell, if it's counter drops to 0, instead of recursively free it, just add it to a free-list. Then, when a new cell has to be allocated, take it from the free-list, delete all its children (using the lazy delete, of course), and return that cell.
First drawback of this method: you loose finalization support, but as I said, most people don't care about that. So that's a non-problem. Second, allocation is not that fast anymore. But it's almost bounded. Why almost? Because it's O(N), being N the number of pointers to be deleted in that cell. This doesn't seems like a huge cost anyways (just decrement a counter and, maybe, add it to a free-list). Allocation is (usually) not bounded anyways (except for compacting collectors).
The big win? Bounded freeing. Really small pauses, with no extra costs.
Note
If you have a (simple) program that suffers from GC pauses that you think it could be easily converted to be reference counted (i.e. few pointer updates), please let me know if you want me to try to make it use lazy freeing RC to analyze the real impact on a real-life program.
Reference counting worth a try
by Leandro Lucarella on 2008- 08- 18 23:30 (updated on 2008- 08- 19 02:19)- with 0 comment(s)
Even when I said that reference counting (RC) will be hard in D, I think it worth a try because it's a really easy way to get incremental garbage collection; the collector activity is interleaved with the mutator. And besides it could be hard to add support to the compiler, it's doable by manually incrementing and decrementing the reference counters to evaluate it.
One of the biggest features of RC is its capability to identify garbage cells as soon as they become garbage (let cycles outside that statement =). The killer use for this is finalization support. Unfortunately this feature kills a lot of possible optimizations. On the other hand, D doesn't need finalization support very hard (with the scope statement and other possible RAII D techniques, I think nobody is missing it), so, lucky us, we can drop that feature and think about some optimizations.
RC can help too to all the fuzz about concurrency and sharing in D2 (it's trivial to know when an object is unshared), but that's a different story.
Note
By the way, I don't think RC can make it on his own (yes, because of cycles), but I think it can help a lot to make collection incremental, leaving just a very small ammount of work to a tracing collector.
Basic algorithms summary
by Leandro Lucarella on 2008- 08- 12 03:42 (updated on 2008- 08- 12 04:26)- with 6 comment(s)
Let's make a little summary about the big categories of garbage collection algorithms:
The first branch is reference counting vs. tracing garbage collectors. For D, reference counting is a really complicated choice, because to be (seriously) considered, the compilar/language have to change pretty much. However, one can make some manual bookkeeping to evaluate if this method has considerable advantages over the other to see if that extra work worth the effort.
Tracing garbage collectors is the easy way to go in D. Tracing comes in two flavors: moving and non-moving. Again, moving is hard in D, because all sort of nasty stuff can be done, but a lot more doable than reference counting. In the non-moving field, the major option is the good ol' mark & sweep (the algorithm used by the actual D garbage collector).
Going back to the moving ones, there are two big groups: copying and mark-compact. I don't like copying too much because it need at least double the residency of a program (remember, we are trying not to waste memory =). Mark-compact have some of the advantages of copying without this requirement.
Note
This is just one arbitrary categorization. There are a lot of other categories based on different topis, like: pauses (stop-the-world, incremental, concurrent, real-time), partitioning (generational, connectivity-based), pointer-awareness (precise, conservative) and probably a lot more that I don't even know.
Post your favorite paper!
by Leandro Lucarella on 2008- 08- 11 18:55 (updated on 2008- 08- 12 01:28)- with 1 comment(s)
DGC begins
by Leandro Lucarella on 2008- 08- 10 21:59 (updated on 2008- 08- 11 03:13)- with 2 comment(s)
Ok, here I am.
First of all, this is a blog. Second, this is a blog about my informatics engineering thesis, to finally finish my long long studies at FIUBA (Engineering Faculty of the Buenos Aires University, UBA): a wild try to improve the D Programming Language garbage collector.
But don't expect too much of this blog. It's just a public place where to write my mental notes (in my poor english), things I want to remember for some point in the future.
If you are still interested, here is my plan for the short term:
I'm reading (again) the bible of GC: Garbage Collection: Algorithms for Automatic Dynamic Memory Management by Rafael Lins (whom I had the pleasure to meet in person) and Richard Jones. I'll try to evaluate the posibility of using each and every technique in that book in the D GC, leaving here all my conclusions about it. What I really want in this first (serious) pass is, at least, to discard the algorithms that are clearly not suitable for D.