Translation of e-mails using Mutt
by Leandro Lucarella on 2012- 09- 24 12:45 (updated on 2012- 10- 02 12:58)- with 0 comment(s)
Update
New translation script here, see the bottom of the post for a description of the changes.
I don't like to trust my important data to big companies like Google. That's why even when I have a GMail, I don't use it as my main account. I'm also a little old fashion for some things, and I like to use Mutt to check my e-mail.
But GMail have a very useful feature, at least it became very useful since I moved to a country which language I don't understand very well yet, that's not available in Mutt: translation.
But that's the good thing about free software and console programs, they are usually easy to hack to get whatever you're missing, so that's what I did.
The immediate solution in my mind was: download some program that uses Google Translate to translate stuff, and pipe messages through it using a macro. Simple, right? No. At least I couldn't find any script to do the translation, because Google Translate API is now paid.
So I tried to look for alternatives, first for some translation program that worked locally, but at least in Ubuntu's repositories I couldn't find anything. Then for online services alternatives, but nothing particularly useful either. So I finally found a guy that, doing some Firebuging, found how to use the free Google translate service. Using that example, I put together a 100 SLOC nice general Python script that you can use to translate stuff, piping them through it. Here is a trivial demonstration of the script (gt, short for Google Translate... Brilliant!):
$ echo hola mundo | gt hello world $ echo hallo Welt | gt --to fr Bonjour tout le monde
And here is the output of gt --help to get a better impression on the script's capabilities:
usage: gt [-h] [--from LANG] [--to LANG] [--input-file FILE]
[--output-file FILE] [--input-encoding ENC] [--output-encoding ENC]
Translate text using Google Translate.
optional arguments:
-h, --help show this help message and exit
--from LANG, -f LANG Translate from LANG language (e.g. en, de, es,
default: auto)
--to LANG, -t LANG Translate to LANG language (e.g. en, de, es, default:
en)
--input-file FILE, -i FILE
Get text to translate from FILE instead of stdin
--output-file FILE, -o FILE
Output translated text to FILE instead of stdout
--input-encoding ENC, -I ENC
Use ENC caracter encoding to read the input (default:
get from locale)
--output-encoding ENC, -O ENC
Use ENC caracter encoding to write the output
(default: get from locale)
You can download the script here, but be warned, I only tested it with Python 3.2. It's almost certain that it won't work with Python < 3.0, and there is a chance it won't work with Python 3.1 either. Please report success or failure, and patches to make it work with older Python versions are always welcome.
Ideally you shouldn't abuse Google's service through this script, if you need to translate massive texts every 50ms just pay for the service. For me it doesn't make any sense to do so, because I'm not using the service differently, when I didn't have the script I just copy&pasted the text to translate to the web. Another drawback of using the script is I couldn't find any way to make it work using HTTPS, so you shouldn't translate sensitive data (you shouldn't do so using the web either, because AFAIK it travels as plain text too).
Anyway, the final step was just to connect Mutt with the script. The solution I found is not ideal, but works most of the time. Just add these macros to your muttrc:
macro index,pager <Esc>t "v/plain\n|gt|less\n" "Translate the first plain text part to English" macro attach <Esc>t "|gt|less\n" "Translate to English"
Now using Esc t in the index or pager view, you'll see the first plain text part of the message translated from an auto-detected language to English in the default encoding. In the attachments view, Esc t will pipe the current part instead. One thing I don't know how to do (or if it's even possible) is to get the encoding of the part being piped to let gt know. For now I have to make the pipe manually for parts that are not in UTF-8 to call gt with the right encoding options. The results are piped through less for convenience. Of course you can write your own macros to translate to another language other than English or use a different default encoding. For example, to translate to Spanish using ISO-8859-1 encoding, just replace the macro with this one:
macro index,pager <Esc>t "v/plain\n|gt -tes -Iiso-8859-1|less\n" "Translate the first plain text part to Spanish"
Well, that's it! I hope is as useful to you as is being to me ;-)
Update
Since picking the right encoding for the e-mail started to be a real PITA, I decided to improve the script to auto-detect the encoding, or to be more specific, to try several popular encodings.
So, here is the help message for the new version of the script:
usage: gt [-h] [--from LANG] [--to LANG] [--input-file FILE]
[--output-file FILE] [--input-encoding ENC] [--output-encoding ENC]
Translate text using Google Translate.
optional arguments:
-h, --help show this help message and exit
--from LANG, -f LANG Translate from LANG language (e.g. en, de, es,
default: auto)
--to LANG, -t LANG Translate to LANG language (e.g. en, de, es, default:
en)
--input-file FILE, -i FILE
Get text to translate from FILE instead of stdin
--output-file FILE, -o FILE
Output translated text to FILE instead of stdout
--input-encoding ENC, -I ENC
Use ENC caracter encoding to read the input, can be a
comma separated list of encodings to try, LOCALE being
a special value for the user's locale-specified
preferred encoding (default: LOCALE,utf-8,iso-8859-15)
--output-encoding ENC, -O ENC
Use ENC caracter encoding to write the output
(default: LOCALE)
So now by default your locale's encoding, utf-8 and iso-8859-15 are tried by default (in that order). These are the defaults that makes more sense to me, you can change the default for the ones that makes sense to you by changing the script or by using -I option in your macro definition, for example:
macro index,pager <Esc>t "v/plain\n|gt -IMS-GREEK,IBM-1148,UTF-16BE|less\n"
Weird choice of defaults indeed :P
Querying N900 address book
by Leandro Lucarella on 2012- 07- 02 20:49 (updated on 2012- 07- 02 20:49)- with 0 comment(s)
Since there is not a lot of information on how to hack Maemo's address book to find some contacts with a mobile phone number, I'll share my findings.
Since setting up an environment to cross-compile for ARM is a big hassle, I decided to write this small test program in Python, (ab)using the wonderful ctypes module to avoid compiling at all.
Here is a very small script to use the (sadly proprietary) OSSO Addressbook library:
# This function get all the names in the address book with mobile phone numbers
# and print them. The code is Python but is as similar as C as possible.
def get_all_mobiles():
osso_ctx = osso_initialize("test_abook", "0.1", FALSE)
osso_abook_init(argc, argv, hash(osso_ctx))
roster = osso_abook_aggregator_get_default(NULL)
osso_abook_waitable_run(roster, g_main_context_default(), NULL)
contacts = osso_abook_aggregator_list_master_contacts(roster)
for contact in glist(contacts):
name = osso_abook_contact_get_display_name(contact)
# Somehow hackish way to get the EVC_TEL attributes
field = e_contact_field_id("mobile-phone")
attrs = e_contact_get_attributes(contact, field)
mobiles = []
for attr in glist(attrs):
types = e_vcard_attribute_get_param(attr, "TYPE")
for t in glist(types):
type = ctypes.c_char_p(t).value
# Remove this condition to get all phone numbers
# (not just mobile phones)
if type == "CELL":
mobiles.append(e_vcard_attribute_get_value(attr))
if mobiles:
print name, mobiles
# Python
import sys
import ctypes
# be sure to import gtk before calling osso_abook_init()
import gtk
import osso
osso_initialize = osso.Context
# Dynamic libraries bindings
glib = ctypes.CDLL('libglib-2.0.so.0')
g_main_context_default = glib.g_main_context_default
def glist(addr):
class _GList(ctypes.Structure):
_fields_ = [('data', ctypes.c_void_p),
('next', ctypes.c_void_p)]
l = addr
while l:
l = _GList.from_address(l)
yield l.data
l = l.next
osso_abook = ctypes.CDLL('libosso-abook-1.0.so.0')
osso_abook_init = osso_abook.osso_abook_init
osso_abook_aggregator_get_default = osso_abook.osso_abook_aggregator_get_default
osso_abook_waitable_run = osso_abook.osso_abook_waitable_run
osso_abook_aggregator_list_master_contacts = osso_abook.osso_abook_aggregator_list_master_contacts
osso_abook_contact_get_display_name = osso_abook.osso_abook_contact_get_display_name
osso_abook_contact_get_display_name.restype = ctypes.c_char_p
ebook = ctypes.CDLL('libebook-1.2.so.5')
e_contact_field_id = ebook.e_contact_field_id
e_contact_get_attributes = ebook.e_contact_get_attributes
e_vcard_attribute_get_value = ebook.e_vcard_attribute_get_value
e_vcard_attribute_get_value.restype = ctypes.c_char_p
e_vcard_attribute_get_param = ebook.e_vcard_attribute_get_param
# argc/argv adaption
argv_type = ctypes.c_char_p * len(sys.argv)
argv = ctypes.byref(argv_type(*sys.argv))
argc = ctypes.byref(ctypes.c_int(len(sys.argv)))
# C-ish aliases
NULL = None
FALSE = False
# Run the test
get_all_mobiles()
Here are some useful links I used as reference:
- http://wiki.maemo.org/PyMaemo/Accessing_APIs_without_Python_bindings
- http://wiki.maemo.org/Documentation/Maemo_5_Developer_Guide/Using_Generic_Platform_Components/Using_Address_Book_API
- http://maemo.org/api_refs/5.0/5.0-final/libebook/
- http://maemo.org/api_refs/5.0/5.0-final/libosso-abook/
- https://garage.maemo.org/plugins/scmsvn/viewcvs.php/releases/evolution-data-server/1.4.2.1-20091104/addressbook/libebook-dbus/?root=eds
- http://www.developer.nokia.com/Community/Discussion/showthread.php?200914-How-to-print-all-contact-names-in-N900-addressbook-Please-Help
How can you don't love FLOSS?
by Leandro Lucarella on 2010- 06- 12 00:11 (updated on 2010- 06- 12 00:11)- with 0 comment(s)
Let me tell you my story.
I'm moving to a new jabber server, so I had to migrate my contacts. I have several jabber accounts, collected all over the years (I started using jabber a long time ago, around 2001 [1]; in that days ICQ interoperability was an issue =P), with a bunch of contacts each, so manual migration was out of the question.
First I thought "this is gonna get ugly" so I thought about using some XMPP Python library to do the work talking directly to the servers, but then I remember 2 key facts:
- I use Psi, which likes XML a lot, and it has a roster cache in a file.
- I use mcabber, which has a FIFO for injecting commands via the command line.
Having this two facts in mind, the migration was as easy as a less than 25 SLOC Python script, without any external dependencies (just Python stdlib):
import sys
import xml.etree.ElementTree as et
def ns(s):
return '{http://psi-im.org/options}' + s
tree = et.parse(sys.argv[1])
accounts = tree.getroot()[0]
for account in accounts.getchildren():
roster_cache = account.find(ns('roster-cache'))
if roster_cache is None:
continue
for contact in roster_cache:
name = contact.findtext(ns('name')).strip().encode('utf-8')
jid = contact.findtext(ns('jid')).strip().encode('utf-8')
print '/add', jid, name
print '/roster search', jid
g = contact.find(ns('groups')).findtext(ns('item'))
if g is not None:
group = g.strip().encode('utf-8')
print '/move', group
Voilà!
Now all you have to do is know where your Psi accounts.xml file is (usually ~/.psi/profiles/<your_profile_name>/accounts.xml), and where your mcabber FIFO is (usually ~/.mcabber/mcabber.fifo, but maybe you have to configure mcabber first) and run:
python script.py /path/to/accounts.xml > /path/to/mcabber.fifo
You can omit the > /path/to/mcabber.fifo first if you have to take a peek at what mcabber commands will be executed, and if you are happy with the results run the full command to execute them.
The nice thing is it's very easy to customize if you have some notions of Python, for example, I didn't want to migrate one account; adding this line just below the for did the trick (the account is named Bad Account in the example):
if account.findtext(ns('name')).strip() == 'Bad Account':
continue
Adding similar simple lines you can filter unwanted users, or groups, or whatever.
And all of this is thanks to:
Thank god for that!
| [1] | A few people will be interested in this, but I think the ones that are will appreciate this link :) (in spanish): http://www.lugmen.org.ar/pipermail/lug-org/2001-December/004482.html |
Debugging C++ with less pain
by Leandro Lucarella on 2010- 05- 14 23:52 (updated on 2010- 05- 14 23:52)- with 0 comment(s)
It turns out GDB 7.0+ can be extended through Python scripts, for instance, to add pretty-printers. And it turns out GCC 4.5 comes with some good pretty-printers for GDB.
Do you want to see the result of that combination?
$ cat -n p.cpp
1
2 #include <string>
3 #include <vector>
4 #include <map>
5
6 int main()
7 {
8 std::string s = "hello world";
9 std::vector<std::string> v;
10 v.push_back(s);
11 v.push_back("nice");
12 std::map<std::string, std::vector<std::string> > m;
13 m[s] = v;
14 v.push_back("yeah");
15 m["lala"] = v;
16 return 1;
17 }
18
$ g++ -g -o p p.cpp
$ gdb -q ./p
(gdb) break 16
Breakpoint 1 at 0x400f86: file p.cpp, line 16.
(gdb) run
Starting program: /tmp/p
Breakpoint 1, main () at p.cpp:16
16 return 1;
(gdb) print m
$1 = std::map with 2 elements = {
["hello world"] = std::vector of length 2, capacity 2 = {"hello world", "nice"},
["lala"] = std::vector of length 3, capacity 3 = {"hello world", "nice", "yeah"}
}
(gdb)
Nice, ugh?
The only missing step is configuration, because most distribution don't do the integration themselves yet (or don't have packages with the scripts).
Here are 3 quick steps to make it all work:
$ mkdir ~/.gdb # can be stored anywhere really $ svn co svn://gcc.gnu.org/svn/gcc/trunk/libstdc++-v3/python ~/.gdb/python $ cat << EOT > ~/.gdbinit python import sys sys.path.insert(0, '/home/$HOME/.gdb/python') from libstdcxx.v6.printers import register_libstdcxx_printers register_libstdcxx_printers (None) end EOT
That's it!
If like to suffer once in a while you can get the raw values using /r:
(gdb) print /r m
$2 = {_M_t = {
_M_impl = {<std::allocator<std::_Rb_tree_node<std::pair<std::basic_string<char, std::char_traits<char>,
std::allocator<char> > const, std::vector<std::basic_string<char, std::char_traits<char>, std::allocator<char> >,
std::allocator<std::basic_string<char, std::char_traits<char>, std::allocator<char> > > > > > >> =
{<__gnu_cxx::new_allocator<std::_Rb_tree_node<std::pair<std::basic_string<char, std::char_traits<char>, std::allocator<char>
> const, std::vector<std::basic_string<char, std::char_traits<char>, std::allocator<char> >,
std::allocator<std::basic_string<char, std::char_traits<char>, std::allocator<char> > > > > > >> = {<No data fields>}, <No
data fields>},
_M_key_compare = {<std::binary_function<std::basic_string<char, std::char_traits<char>, std::allocator<char> >,
std::basic_string<char, std::char_traits<char>, std::allocator<char> >, bool>> = {<No data fields>}, <No data fields>},
_M_header = {
_M_color = std::_S_red, _M_parent = 0x6070b0, _M_left = 0x6070b0,
_M_right = 0x607190}, _M_node_count = 2}}}
Looks more familiar? I guess you won't miss it! =P
bpython
by Leandro Lucarella on 2009- 12- 03 14:56 (updated on 2009- 12- 03 14:56)- with 0 comment(s)
I'll just copy what the home page:
bpython is a fancy interface to the Python interpreter for Unix-like operating systems (I hear it works fine on OS X). It is released under the MIT License. It has the following features:
- In-line syntax highlighting.
- Readline-like autocomplete with suggestions displayed as you type.
- Expected parameter list for any Python function.
- "Rewind" function to pop the last line of code from memory and re-evaluate.
- Send the code you've entered off to a pastebin.
- Save the code you've entered to a file.
- Auto-indentation.
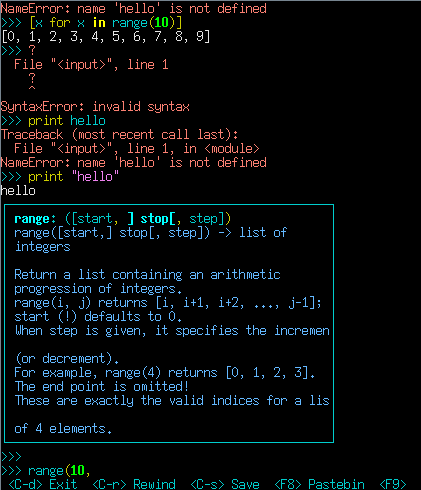
pybugz, a python and command line interface to Bugzilla
by Leandro Lucarella on 2009- 10- 16 14:14 (updated on 2009- 10- 16 14:14)- with 0 comment(s)
Tired of the clumsy Bugzilla web interface? Meet pybugz, a command line interface for Bugzilla.
An example workflow from the README file:
$ bugz search "version bump" --assigned liquidx@gentoo.org * Using http://bugs.gentoo.org/ .. * Searching for "version bump" ordered by "number" 101968 liquidx net-im/msnlib version bump 125468 liquidx version bump for dev-libs/g-wrap-1.9.6 130608 liquidx app-dicts/stardict version bump: 2.4.7 $ bugz get 101968 * Using http://bugs.gentoo.org/ .. * Getting bug 130608 .. Title : app-dicts/stardict version bump: 2.4.7 Assignee : liquidx@gentoo.org Reported : 2006-04-20 07:36 PST Updated : 2006-05-29 23:18:12 PST Status : NEW URL : http://stardict.sf.net Severity : enhancement Reporter : dushistov@mail.ru Priority : P2 Comments : 3 Attachments : 1 [ATTACH] [87844] [stardict 2.4.7 ebuild] [Comment #1] dushistov@----.ru : 2006-04-20 07:36 PST ... $ bugz attachment 87844 * Using http://bugs.gentoo.org/ .. * Getting attachment 87844 * Saving attachment: "stardict-2.4.7.ebuild" $ bugz modify 130608 --fixed -c "Thanks for the ebuild. Committed to portage"
Tucan {up,down}load manager for file hosting sites
by Leandro Lucarella on 2009- 10- 06 14:02 (updated on 2009- 10- 06 14:02)- with 0 comment(s)
Meet Tucan:

Tucan is a free and open source application designed for automatic management of downloads and uploads at hosting sites like Rapidshare.
The Python's algorithm
by Leandro Lucarella on 2008- 09- 08 02:05 (updated on 2008- 09- 08 02:05)- with 0 comment(s)
Python (at least CPython) uses reference counting, and since version 2.0 it includes a cycles freeing algorithm. It uses a generational approach, with 3 generations.
Python makes a distinction between atoms (strings and numbers mostly), which can't be part of cycles; and containers (tuples, lists, dictionaries, instances, classes, etc.), which can. Since it's unable to find all the roots, it keeps track of all the container objects (as a double linked list) and periodically look in them for cycles. If somebody survive the collection, is promoted to the next generation.
I think this works pretty well in real life programs (I never had problems with Python's GC -long pauses or such-, and I never heard complains either), and I don't see why it shouldn't work for D. Even more, Python have an issue with finalizers which don't exist in D because you don't have any warranties about finalization order in D already (and nobody seems to care, because when you need to have some order of finalization you should probably use some kind of RAII).