TypeInfo, static data and the GC
by Leandro Lucarella on 2010- 08- 16 00:39 (updated on 2010- 08- 16 00:39)- with 0 comment(s)
The D compiler doesn't provide any information on the static data that the GC must scan, so the runtime/GC have to use OS-dependant tricks to get that information.
Right now, in Linux, the GC gets the static data to scan from the libc's variables __data_start and _end, from which are not much information floating around except for some e-mail from Hans Boehm to the binutils mainling list.
There is a lot of stuff in the static data that doesn't need to be scanned, most notably the TypeInfo, which is a great portion of the static data. C libraries static data, for example, would be scanned too, when it makes no sense to do so.
I noticed CDGC has more than double the static data the basic GC has, just because of TypeInfo (I use about 5 or so more types, one of them is a template, which makes the bloat bigger).
The voronoi test goes from 21KB to 26KB of static data when using CDGC.
It would be nice if the compiler could group all the static that must really be scanned (programs static variables) together and make its limits available to the GC. It would be even nicer to leave static variables that have no pointers out of that group, and even much more nicer to create a pointer map like the one in the patch for precise scanning to allow precise heap scanning. Then only the scan should be scanned in full conservative mode.
I reported a bug with this issue so it doesn't get lost.
Type information at the end of the block considered harmful
by Leandro Lucarella on 2010- 08- 07 17:24 (updated on 2010- 08- 09 13:22)- with 0 comment(s)
Yes, I know I'm not Dijkstra, but I always wanted to do a considered harmful essay =P
And I'm talking about a very specific issue, so this will probably a boring reading for most people :)
This is about my research in D garbage collection, the CDGC, and related to a recent post and the precise heap scanning patch.
I've been playing with the patch for a couple of weeks now, and even when some of the tests in my benchmark became more stable, other tests had the inverse effect, and other tests even worsen their performance.
The extra work done by the patch should not be too significant compared with the work it avoids by no scanning things that are no pointers, so the performance, intuitively speaking, should be considerably increased for test that have a lot of false pointers and for the other tests, at least not be worse or less stable. But that was not what I observed.
I finally got to investigate this issue, and found out that when the precise version was clearly slower than the Tango basic collector, it was due to a difference in the number of collections triggered by the test. Sometimes a big difference, and sometimes with a lot of variation. The number usually never approached to the best value achieved by the basic collector.
For example, the voronoi test with N = 30_000, the best run with the basic collector triggered about 60 collections, varying up to 90, while the precise scanning triggered about 80, with very little variation. Even more, if I ran the tests using setarch to avoid heap addresses randomization (see the other post for details), the basic collector triggered about 65 collections always, while the precise collector still triggered 80, so there was something wrong with the precise scanning independently of the heap addresses.
So the suspicions I had about storing the type information pointer at the end of the block being the cause of the problem became even more suspicious. So I added an option to make the precise collector conservative. The collection algorithm, that changed between collectors, was untouched, the precise collector just don't store the type information when is configured in conservative mode, so it scans all the memory as if it didn't had type information. The results where almost the same as the basic collector, so the problem really was the space overhead of storing the type information in the same blocks the mutator stores it's data.
It looks like the probability of keeping blocks alive incorrectly because of false pointer, even when they came just from the static data and the stack (and other non-precise types, like unions) is increased significantly because of the larger blocks.
The I tried to strip the programs (all the test were using programs with debug info to ease the debugging when I brake the GC :), and the number of collections decreased considerably in average, and the variation between runs too. So it looks like that in the scanned static data are included the debug symbols or there is something else adding noise. This for both precise and conservative scanning, but the effect is worse with precise scanning. Running the programs without heap address randomization (setarch -R), usually decreases the number of collections and the variance too.
Finally, I used a very naïve (but easy) way of storing the type information pointers outside the GC scanned blocks, wasting 25% of space just to store this information (as explained in a comment to the bug report), but I insist, that overhead is outside the GC scanned blocks, unlike the small overhead imposed by storing a pointer at the end of that blocks. Even with such high memory overhead, the results were surprising, the voronoi number of collections doing precise scanning dropped to about 68 (very stable) and the total runtime was a little smaller than the best basic GC times, which made less collections (and were more unstable between runs).
Note that there are still several test that are worse for the CDGC (most notably Dil, the only real-life application :), there are plenty of changes between both collectors and I still didn't look for the causes.
I'll try to experiment with a better way of storing the type information pointers outside the GC blocks, probably using a hash table.
At last but not least, here are some figures (basic is the Tango basic collector, cdgc is the CDGC collector with the specified modifications):
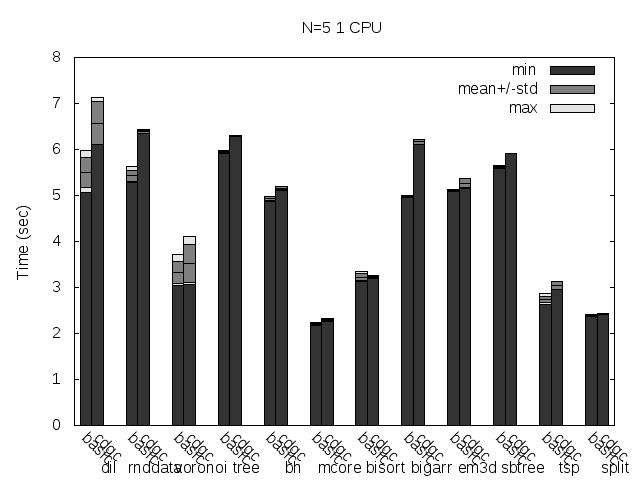
Precise scanning patch doing conservative scanning (not storing the type information at all).
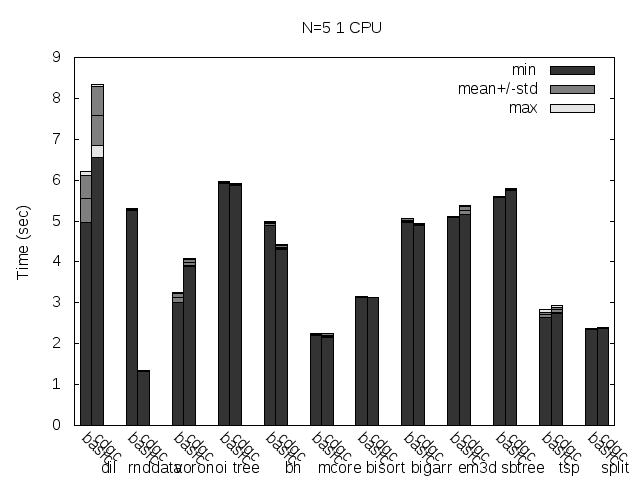
Precise scanning storing the type information at the end of the GC blocks.
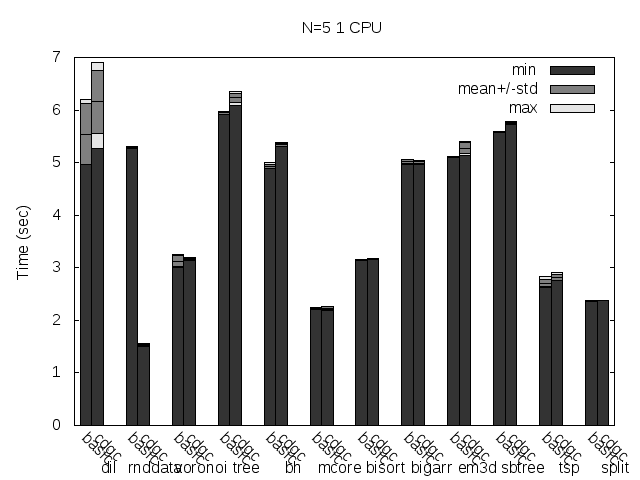
Precise scanning storing the type information outside the GC blocks.
Here are the same tests, but with the binaries stripped:
Precise scanning patch doing conservative scanning (not storing the type information at all). Stripped.
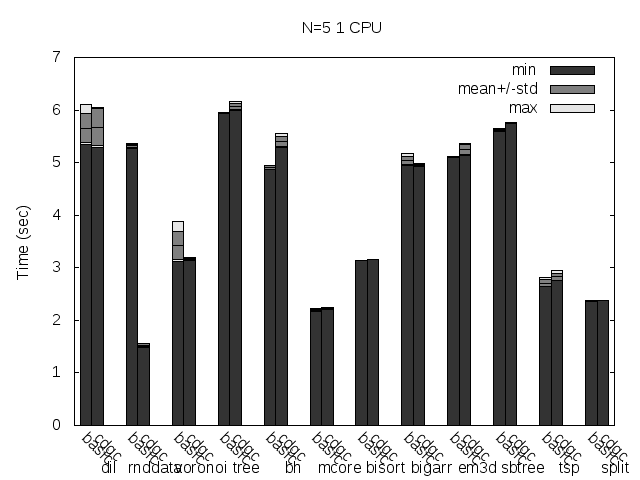
Precise scanning storing the type information at the end of the GC blocks. Stripped.
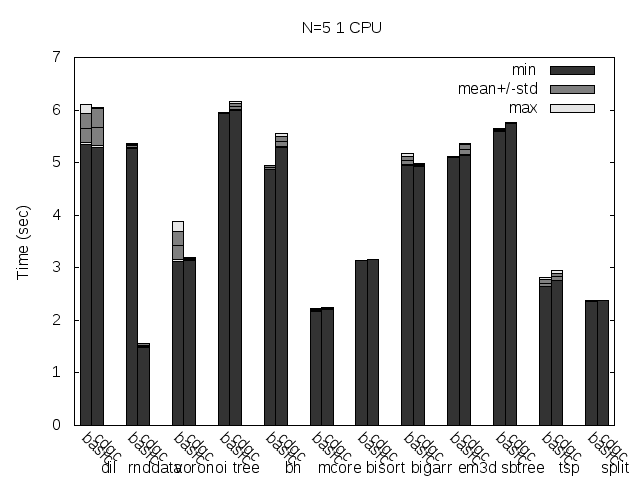
Precise scanning storing the type information outside the GC blocks. Stripped.
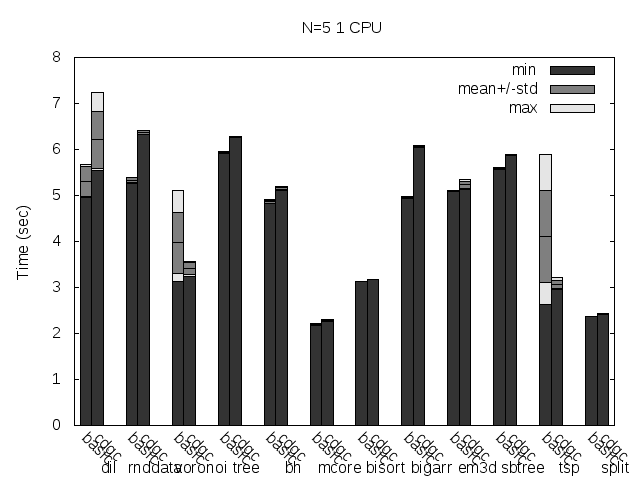
Here are the same tests as above, but disabling Linux heap addresses randomization (setarch -R):
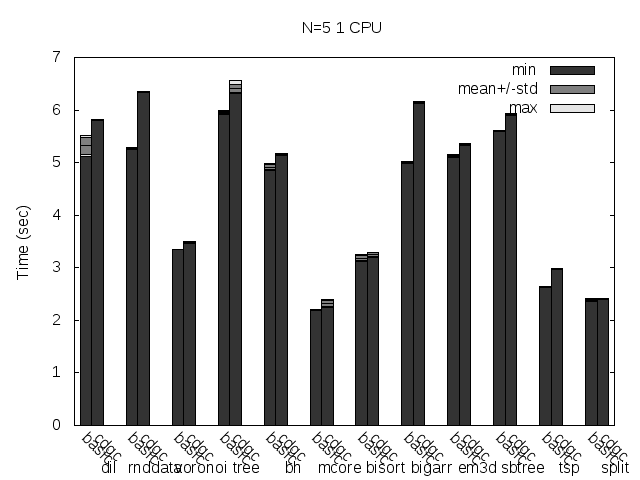
Precise scanning patch doing conservative scanning (not storing the type information at all). Stripped. No addresses randomization.
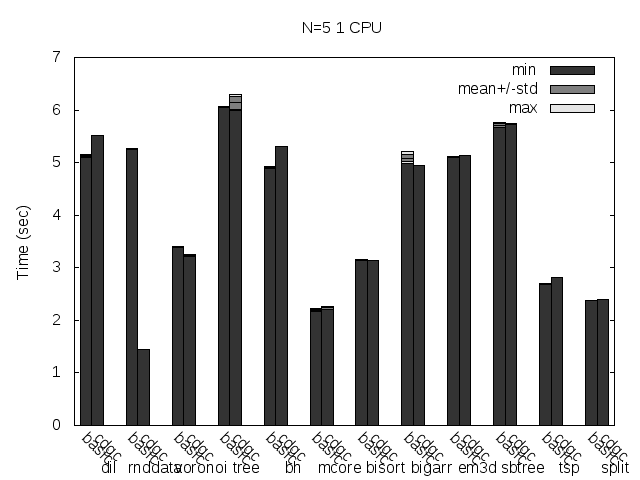
Precise scanning storing the type information at the end of the GC blocks. Stripped. No addresses randomization.
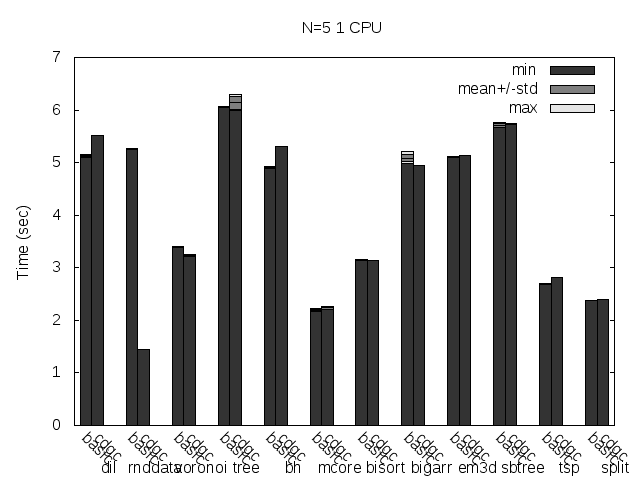
Precise scanning storing the type information outside the GC blocks. Stripped. No addresses randomization.
Update
I noticed that the plots doesn't always reflect 100% what's stated in the text, that is because the text was written with another run results and it seems like the tested programs are very sensitive to the heap and binary addresses the kernel assign to the program.
Anyway, what you can see in the plots very clear is how stripping the binaries changes the results a lot and how the performance is particularly improved when storing the type information pointer outside the GC'ed memory when the binaries are not stripped.
Patch to make D's GC partially precise
by Leandro Lucarella on 2009- 11- 06 14:43 (updated on 2009- 11- 06 23:09)- with 0 comment(s)
David Simcha has announced a couple of weeks ago that he wanted to work on making the D's GC partially precise (only the heap). I was planning to do it myself eventually because it looked like something doable with not much work that could yield a big performance gain, and particularly useful to avoid memory leaks due to false pointers (which can keep huge blocks of data artificially alive). But I didn't had the time and I had other priorities.
Anyway, after some discussion, he finally announced he got the patch, which he added as a bug report. The patch is being analyzed for inclusion, but the main problem now is that it is not integrated with the new operator, so if you want to get precise heap scanning, you have to use a custom function to allocate (that creates a map of the type to allocate at compile-time to pass the information about the location of the pointers to the GC).
I'm glad David could work on this and I hope this can be included in D2, since is a long awaited feature of the GC.
Update
David Schima has been just added to the list of Phobos developers. Maybe he can integrate his work on associative arrays too.