Truly concurrent GC using eager allocation
by Leandro Lucarella on 2010- 09- 10 03:01 (updated on 2010- 09- 10 03:01)- with 0 comment(s)
Finally, I got the first version of CDGC with truly concurrent garbage collection, in the sense that all the threads of the mutator (the program itself) can run in parallel with the collector (well, only the mark phase to be honest :).
You might want to read a previous post about CDGC where I achieved some sort of concurrency by making only the stop-the-world time very short, but the thread that triggered the collection (and any other thread needing any GC service) had to wait until the collection finishes. The thread that triggered the collection needed to wait for the collection to finish to fulfill the memory allocation request (it was triggered because the memory was exhausted), while any other thread needing any GC service needed to acquire the global GC lock (damn global GC lock!).
To avoid this issue, I took a simple approach that I call eager allocation, consisting on spawn the mark phase concurrently but allocating a new memory pool to be able to fulfill the memory request instantly. Doing so, not only the thread that triggered the collection can keep going without waiting the collection to finish, the global GC lock is released and any other thread can use any GC service, and even allocate more memory, since a new pool was allocated.
If the memory is exhausted again before the collection finishes, a new pool is allocated, so everything can keep running. The obvious (bad) consequence of this is potential memory bloat. Since the memory usage is minimized from time to time, this effect should not be too harmful though, but let's see the results, there are plenty of things to analyze from them (a lot not even related to concurrency).
First, a couple of comments about the plots:
- Times of Dil are multiplied by a factor of 0.1 in all the plots, times of rnddata are too, but only in the pause time and stop-the-world plots. This is only to make the plots more readable.
- The unreadable labels rotated 45 degrees say: stw, fork and ea. Those stand for Stop-the-world (the basic collector), fork only (concurrent but without eager allocation) and eager allocation respectively. You can click on the images to see a little more readable SVG version.
- The plots are for one CPU-only because using more CPUs doesn't change much (for these plots).
- The times were taken from a single run, unlike the total run time plots I usually post. Since a single run have multiple collections, the information about min, max, average and standard deviation still applies for the single run.
- Stop-the-world time is the time no mutator thread can run. This is not related to the global GC lock, is time the threads are really really paused (this is even necessary for the forking GC to take a snapshot of threads CPU registers and stacks). So, the time no mutator thread can do any useful work might be much bigger than this time, because the GC lock. This time is what I call Pause time. The maximum pause time is probably the most important variable for a GC that tries to minimize pauses, like this one. Is the maximum time a program will stay totally unresponsive (important for a server, a GUI application, a game or any interactive application).

The stop-the-world time is reduced so much that you can hardly see the times of the fork and ea configuration. It's reduced in all tests by a big margin, except for mcore and the bigarr. For the former it was even increased a little, for the later it was reduced but very little (but only for the ea* configuration, so it might be a bad measure). This is really measuring the Linux fork() time. When the program manages so little data that the mark phase itself is so fast that's faster than a fork(), this is what happens. The good news is, the pause times are small enough for those cases, so no harm is done (except from adding a little more total run time to the program).
Note the Dil maximum stop-the-world time, it's 0.2 seconds, looks pretty big, uh? Well, now remember that this time was multiplied by 0.1, the real maximum stop-the-world for Dil is 2 seconds, and remember this is the minimum amount of time the program is unresponsive! Thank god it's not an interactive application :)
Time to take a look to the real pause time:

OK, this is a little more confusing... The only strong pattern is that pause time is not changed (much) between the swt and fork configurations. This seems to make sense, as both configurations must wait for the whole collection to finish (I really don't know what's happening with the bh test).
For most tests (7), the pause time is much smaller for the ea configuration, 3 tests have much bigger times for it, one is bigger but similar (again mcore) and then is the weird case of bh. The 7 tests where the time is reduced are the ones that seems to make sense, that's what I was looking for, so let's see what's happening with the remaining 3, and for that, let's take a look at the amount of memory the program is using, to see if the memory bloat of allocating extra pools is significant.
| Test | Maximum heap size (MB) | ||
|---|---|---|---|
| Program | stw | ea | ea/stw |
| dil | 216 | 250 | 1.16 |
| rnddata | 181 | 181 | 1 |
| voronoi | 16 | 30 | 1.88 |
| tree | 7 | 114 | 16.3 |
| bh | 80 | 80 | 1 |
| mcore | 30 | 38 | 1.27 |
| bisort | 30 | 30 | 1 |
| bigarr | 11 | 223 | 20.3 |
| em3d | 63 | 63 | 1 |
| sbtree | 11 | 122 | 11.1 |
| tsp | 63 | 63 | 1 |
| split | 39 | 39 | 1 |
See any relations between the plot and the table? I do. It looks like some programs are not being able to minimize the memory usage, and because of that, the sweep phase (which still have to run in a mutator thread, taking the global GC lock) is taking ages. An easy to try approach is to trigger the minimization of the memory usage not only at when big objects are allocated (like it is now), but that could lead to more mmap()/munmap()s than necessary. And there still problems with pools that are kept alive because a very small object is still alive, which is not solved by this.
So I think a more long term solution would be to introduce what I call early collection too. Meaning, trigger a collection before the memory is exhausted. That would be the next step in the CDGC.
Finally, let's take a look at the total run time of the test programs using the basic GC and CDGC with concurrent marking and eager allocation. This time, let's see what happens with 2 CPUs (and 25 runs):

Wow! It looks like this is getting really juicy (with exceptions, as usual :)! Dil time is reduced to about 1/3, voronoi is reduced to 1/10!!! Split and mcore have both their time considerably reduced, but that's because another small optimization (unrelated to what we are seeing today), so forget about those two. Same for rnddata, which is reduced because of precise heap scanning. But other tests increased its runtime, most notably bigarr takes almost double the time. Looking at the maximum heap size table, one can find some answers for this too. Another ugly side of early allocation.
For completeness, let's see what happens with the number of collections triggered during the program's life. Here is the previous table with this new data added:
| Test | Maximum heap size (MB) | Number of collections | ||||
|---|---|---|---|---|---|---|
| Program | stw | ea | ea/stw | stw | ea | ea/stw |
| dil | 216 | 250 | 1.16 | 62 | 50 | 0.81 |
| rnddata | 181 | 181 | 1 | 28 | 28 | 1 |
| voronoi | 16 | 30 | 1.88 | 79 | 14 | 0.18 |
| tree | 7 | 114 | 16.3 | 204 | 32 | 0.16 |
| bh | 80 | 80 | 1 | 27 | 27 | 1 |
| mcore | 30 | 38 | 1.27 | 18 | 14 | 0.78 |
| bisort | 30 | 30 | 1 | 10 | 10 | 1 |
| bigarr | 11 | 223 | 20.3 | 305 | 40 | 0.13 |
| em3d | 63 | 63 | 1 | 14 | 14 | 1 |
| sbtree | 11 | 122 | 11.1 | 110 | 33 | 0.3 |
| tsp | 63 | 63 | 1 | 14 | 14 | 1 |
| split | 39 | 39 | 1 | 7 | 7 | 1 |
See how the number of collections is practically reduced proportionally to the increase of the heap size. When the increase in size explodes, even when the number of collections is greatly reduced, the sweep time take over and the total run time is increased. Specially in those tests where the program is almost only using the GC (as in sbtree and bigarr). That's why I like the most Dil and voronoi as key tests, they do quite a lot of real work beside asking for memory or using other GC services.
This confirms that the performance gain is not strictly related to the added concurrency, but because of a nice (finally! :) side-effect of eager allocation: removing some pressure from the GC by increasing the heap size a little (Dil gets 3x boost in run time for as little as 1.16x of memory usage; voronoi gets 10x at the expense of almost doubling the heap, I think both are good trade-offs). This shows another weak point of the GC, sometimes the HEAP is way too tight, triggering a lot of collections, which leads to a lot of GC run time overhead. Nothing is done right now to keep a good heap occupancy ratio.
But is there any real speed (in total run time terms) improvement because of the added concurrency? Let's see the run time for 1 CPU:

It looks like there is, specially for my two favourite tests: both Dil and voronoi get a 30% speed boost! That's not bad, not bad at all...
If you want to try it, the repository has been updated with this last changes :). If you do, please let me know how it went.
CDGC first breath
by Leandro Lucarella on 2010- 08- 23 02:03 (updated on 2010- 08- 23 02:03)- with 0 comment(s)
I'm glad to announce that now, for the first time, CDGC means Concurrent D Garbage Collector, as I have my first (extremely raw and unoptimized) version of the concurrent GC running. And I have to say, I'm very excited and happy with the results from the very small benchmark I did.
The stop-the-world (pause) time was reduced by 2 orders of magnitude for the average, the standard deviation and, probably the more important, the maximum (these are the results for a single run, measuring the pause time for all the collections in that run). This is good news for people needing (soft) real-time in D, even when using the GC. Where the standard D GC have a pause time of 100ms, the CDGC have a pause time of 1ms.
The total run-time of the program was increased a little though, but not as much as the pause time was reduced. Only a 12% performance loss was measured, but this is just the first raw unoptimized version of the CDGC.
All this was measured with the voronoi benchmark, with -n 30000. Here are some plots:
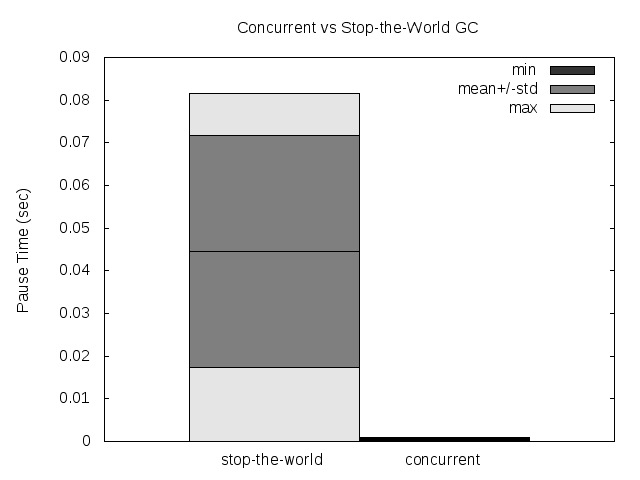
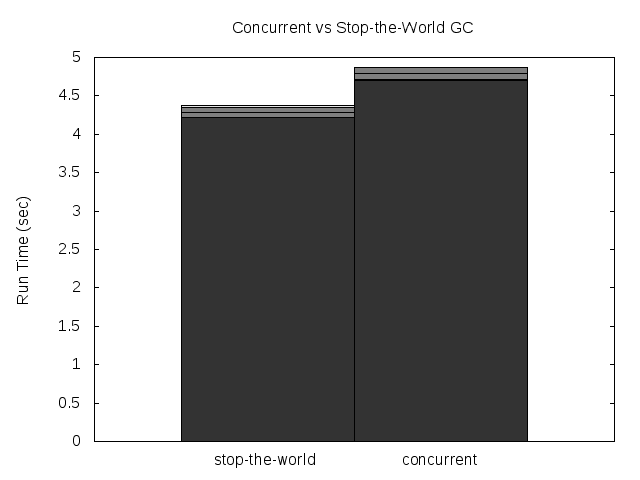
Please note that the GC still has a global lock, so if 2 threads needs to allocate while the collection is running, both will be paused anyways (I have a couple of ideas on how to try to avoid that).
The idea about how to make the GC concurrent is based on the paper Nonintrusive Cloning Garbage Collector with Stock Operating System Support. I'm particularly excited by the results because the reduction of the pause time in the original paper were less than 1 order of magnitude better than their stop-the-world collector, so the preliminary results of the CDGC are much better than I expected.