druntime developers FAQ
by Leandro Lucarella on 2008- 12- 05 11:38 (updated on 2008- 12- 05 11:38)- with 0 comment(s)
Improved druntime getting started documentation
by Leandro Lucarella on 2008- 12- 02 23:07 (updated on 2008- 12- 02 23:07)- with 0 comment(s)
I've expanded the druntime Getting Started documentation. I basically added all the information I've posted in this blog so far: how to change the GC implementation and rebuild phobos.
Testing druntime modifications
by Leandro Lucarella on 2008- 11- 30 03:51 (updated on 2008- 11- 30 03:51)- with 0 comment(s)
Now that we can compile druntime, we should be able to compile some programs that use our fresh, modified, druntime library.
Since DMD 2.021, druntime is built into phobos, so if we want to test some code we need to rebuild phobos too, to include our new druntime.
Since I'm particularly interested in the GC, let's say we want to use the GC stub implementation (instead of the basic default).
We can add a simple "init" message to see that something is actually happening. For example, open src/gc/stub/gc.d and add this import:
private import core.sys.posix.unistd: write;
Then, in the gc_init() function add this line:
write(1, "init\n".ptr, 5);
Now, we must tell druntime we want to use the stub GC implementation. Edit dmd-posix.mak, search for DIR_GC variable and change it from basic to stub:
DIR_GC=gc/stub
Great, now recompile druntime.
Finally, go to your DMD installation, and edit src/phobos/linux.mak. Search for the DRUNTIME variable and set it to the path to your newly generated libdruntime.a (look in the druntime lib directory). For me it's something like:
DRUNTIME=/home/luca/tesis/druntime/lib/libdruntime.a
Now recompile phobos. I have to do this, because my DMD compiler is named dmd2:
make -f linux.mak DMD=dmd2
Now you can compile some trivial D program (compile it in the src druntime directory so its dmd.conf is used to search for the libraries and imports) and see how "init" get printed when the program starts. For example:
druntime/src$ cat hello.d
import core.sys.posix.unistd: write;
void main()
{
write(1, "hello!\n".ptr, 7);
}
druntime/src$ dmd2 -L-L/home/luca/tesis/dmd2/lib hello.d
druntime/src$ ./hello
init
hello!
Note that I passed my DMD compiler's lib path so it can properly find the newly created libphobos2.a.
druntime build system
by Leandro Lucarella on 2008- 11- 26 02:28 (updated on 2008- 11- 26 02:28)- with 0 comment(s)
I have to be honest on this one. I'm not crazy about the druntime build system. I know there are a lot of other more important thing to work on, but I can't help myself, and if I'm not comfortable with the build system, I get too much distracted, so I have no choice but to try to improve it a little =)
First, I don't like the HOME environment variable override hack in build-dmd.sh (I won't talk about the Windows build because I don't have Windows, so I can't test it).
So I've made a simple patch to tackle this. It just adds a dmd.conf configuration file in each directory owning a makefile. I think it's a fair price to pay adding this extra files to be hable to just use make and get rid of the build-dmd.sh script.
I've added a ticket on this and another related ticket with a patch too.
Getting started with druntime
by Leandro Lucarella on 2008- 11- 25 02:27 (updated on 2008- 11- 25 02:27)- with 0 comment(s)
I've added a brief draft about how to get started in the druntime wiki, which I plan to expand a little in the future.
I hope somebody find it useful.
BTW, the -version=Posix fix is now included in the main repo.
My druntime repository
by Leandro Lucarella on 2008- 11- 24 02:17 (updated on 2008- 11- 24 02:17)- with 0 comment(s)
I've finally published my own git druntime repository. It has both branches, the one for D2 (the svn trunk, called master in my repo) and the one for D1 (D1.0 in svn, d1 in my repo).
For now, there are only changes in the master branch.
Hacking druntime
by Leandro Lucarella on 2008- 11- 22 16:38 (updated on 2009- 03- 28 20:17)- with 0 comment(s)
I've been reading the source code of the druntime, and it's time to get my hands dirty and do some real work.
First I have to do to start hacking it is build it and start trying things out. There is no documentation at all yet, so I finally bothered Sean Kelly and asked him how to get started.
Here is what I had to do to get druntime compiled:
First of all, I'll introduce my environment and tools. I'll use DMD because there's no other option for now (druntime doesn't have support for GDC, but Sean says it's coming soon, and LDC will not be included until the support it's added to Tango runtime).
The trunk in the druntime repository is for D2, but there is a branch for D1 too.
I use Debian (so you'll see some apt stuff here) and I love git, and there's is no way I will go back to subversion. Fortunately there is git-svn, so that's what I'm gonna use =)
Now, what I did step by step.
Get the git goodies:
sudo aptitude install git-core git-svn
Make a directory where to put all the D-related stuff:
mkdir ~/d cd ~/d
Get D2 (bleeding edge version) and unpack it:
wget http://ftp.digitalmars.com/dmd.2.026.zip unzip dmd.2.020.zip # "install" the D2 compiler rm -fr dm dmd/linux/bin/{sc.ini,readme.txt,*.{exe,dll,hlp}} # cut the fat chmod a+x dmd/linux/bin/{dmd,rdmd,dumpobj,obj2asm} # make binaries executable mv dmd dmd2 # reserve the dmd directory for D1 compilerMake it accessible, for example:
echo '#!/bin/sh' > ~/bin/dmd2 # reserve dmd name for the D1 compiler echo 'exec ~/d/dmd2/linux/bin/dmd "$@"' >> ~/bin/dmd2 chmod a+x ~/bin/dmd2
Get D1 and install it too:
wget http://ftp.digitalmars.com/dmd.1.041.zip unzip dmd.1.036.zip rm -fr dm dmd/linux/bin/{sc.ini,readme.txt,*.{exe,dll,hlp}} chmod a+x dmd/linux/bin/{dmd,rdmd,dumpobj,obj2asm} echo '#!/bin/sh' > ~/bin/dmd echo 'exec ~/d/dmd/linux/bin/dmd "$@"' >> ~/bin/dmd chmod a+x ~/bin/dmdGet druntime for D1 and D2 as separated repositories (you can get all in one git repository using git branches but since I'll work on both at the same time I prefer to use two separated repositories):
git svn clone http://svn.dsource.org/projects/druntime/branches/D1.0 \ druntime git svn clone http://svn.dsource.org/projects/druntime/trunk druntime2
Build druntime for D1:
cd druntime bash build-dmd.sh cd -
Build druntime for D2.
This one is a little trickier. The trunk version have some changes for a feature that is not yet released (this being changed from a pointer to a reference for structs). Fortunately this is well isolated in a single commit, so reverting this change is really easy, first, get the abbreviated hash for the commit 44:
cd druntime2 git log --grep='trunk@44' --pretty=format:%h
This should give you a small string (mine is cae2326). Now, revert that change:
git revert cae2326
Done! You now have that change reverted, we can remove this new commit later when the new version of DMD that implements the this change appear.
But this is not all. Then I find a problem about redefining the Posix version:
Error: version identifier 'Posix' is reserved and cannot be set
To fix this you just have to remove the -version=Posix from build-dmd.sh.
But there is still one more problem, but this is because I have renamed the bianries to have both dmd and dmd2. The compiler we have to use to build things is called dmd2 for me, but build-dmd.sh don't override properly the DC environment variable when calling make, so dmd is used instead.
This is a simple and quick fix:
diff --git a/src/build-dmd.sh b/src/build-dmd.sh old mode 100644 new mode 100755 index d6be599..8f3b163 --- a/src/build-dmd.sh +++ b/src/build-dmd.sh @@ -11,9 +11,10 @@ goerror(){ exit 1 } -make clean -fdmd-posix.mak || goerror -make lib doc install -fdmd-posix.mak || goerror -make clean -fdmd-posix.mak || goerror +test -z "$DC" && DC=dmd +make DC=$DC clean -fdmd-posix.mak || goerror +make DC=$DC lib doc install -fdmd-posix.mak || goerror +make DC=$DC clean -fdmd-posix.mak || goerror chmod 644 ../import/*.di || goerror export HOME=$OLDHOME(to apply the patch just copy&paste it to fix.patch and then do git apply fix.patch; that should do the trick)
Now you can do something like this to build druntime for D2:
export DC=dmd2 bash build-dmd.sh
That's it for now. I'll be publishing my druntime (git) repository soon with this changes (and probably submitting some patches to upstream) so stay tuned ;)
Richard Jones GC book figures
by Leandro Lucarella on 2008- 10- 22 00:21 (updated on 2008- 10- 22 01:01)- with 0 comment(s)
Yesterday Richard Jones announced the publication of all the figures of the GC book he co-authored.
This is very nice news indeed =)
PS: Yes, I'm still alive, just very busy =( I took a look at the D's GC, but I'm waiting too for all the fuzz about the new druntime to settle a little to ask Sean Kelly some questions about it's internals
Mark-Sweep
by Leandro Lucarella on 2008- 09- 16 02:25 (updated on 2008- 09- 16 02:25)- with 0 comment(s)
After a busy week (unfortunately not working on my thesis), I'll move on to mark-sweep algorithms (I've covered the basic reference counting stuff for now).
The GC book start with some obvious optimizations about making the marking phase non recursive using an explicit stack and methods to handle stack overflow.
Since current D's GC is mark-sweep, I think I have to take a (deeper) look at it now, to see what optimizations is actually using (I don't think D GC is using the primitive recursive algorithm) and take that as the base ground to look for improvements.
The Python's algorithm
by Leandro Lucarella on 2008- 09- 08 02:05 (updated on 2008- 09- 08 02:05)- with 0 comment(s)
Python (at least CPython) uses reference counting, and since version 2.0 it includes a cycles freeing algorithm. It uses a generational approach, with 3 generations.
Python makes a distinction between atoms (strings and numbers mostly), which can't be part of cycles; and containers (tuples, lists, dictionaries, instances, classes, etc.), which can. Since it's unable to find all the roots, it keeps track of all the container objects (as a double linked list) and periodically look in them for cycles. If somebody survive the collection, is promoted to the next generation.
I think this works pretty well in real life programs (I never had problems with Python's GC -long pauses or such-, and I never heard complains either), and I don't see why it shouldn't work for D. Even more, Python have an issue with finalizers which don't exist in D because you don't have any warranties about finalization order in D already (and nobody seems to care, because when you need to have some order of finalization you should probably use some kind of RAII).
Partial mark and sweep cycle reclamation
by Leandro Lucarella on 2008- 09- 07 18:26 (updated on 2008- 09- 07 18:26)- with 0 comment(s)
This is a more polished version of the last idea about adding a backup tracing GC to collect cycles. We just trace the areas of the heap that can potentially store cycles (instead of tracing all the heap).
So, how do we know which areas may have cycles? When a reference counter is decremented, if it becomes zero, it can't possibly part of a cycle, but when the counter is decremented 1 or more, you never know. So the basics for the algorithm is to store cells which counters have been decremented to 1 or more, and then make a local (partial) mark and sweep to the cell accessible from it.
The trick is to use the reference counters. In the marking phase, the reference counters are decremented as the connectivity graph is traversed. When the marking phase is done, any cell with counter higher than zero is reference from outside the partial graph analyzed, so it must survive (as well as all the cells reachable from it).
Note
The worst case for a partial scan, is to scan the whole heap. But this should be extremely rare.
There are a lot of flavors of this algorithm, but all are based on the same principle, and most of the could be suitable for D.
Backup tracing collector for rc cycles reclamation
by Leandro Lucarella on 2008- 09- 07 04:05 (updated on 2009- 04- 02 21:42)- with 0 comment(s)
The simpler way to reclaim cycles is to use a backup tracing garbage collector. But this way, even when GC frequency could be much lower, the infomation of reference counters are not used, and pauses can be very long (depending on the backup algorithm used).
I think some kind of mixture between RC and tracing GC could be done so I wont discard this option just yet, but I think more specialized algorithms can do better in this case.
Discarded cycles reclamation algorithms
by Leandro Lucarella on 2008- 09- 07 03:50 (updated on 2008- 09- 07 03:50)- with 0 comment(s)
Finally, we address the cyclic structures reclaimation when doing reference counting. But I think there are some algorithms that are clearly unsuitable for D.
All the manual techniques (manually avoiding or breaking cycles or using weak pointers) are unacceptable, because it throws the problem again to the programmer. So I will consider only the options that keep the memory management automatic.
There are several specific cycles reclamation algorithms for functional languages too (like Friedman and Wise), but of course they are unsuitable for D because of the asumptios they make.
Bobrow proposed a general technique, in which a cyclic structure is reference counted as a whole (instead of reference counting their individual cells) but I find this impractical for D too, because it needs programmer intervention (marking "group" of cells).
Limited reference counting
by Leandro Lucarella on 2008- 09- 03 01:33 (updated on 2008- 09- 03 01:33)- with 0 comment(s)
Another optimization proposed by the GC book is limiting the reference count field to something smaller than a word. This is just a space optimization, consisting in use something shorter than a word, and marking the cell sticky if an overflow is detected. Sticky cell's reference counters are not updated any more and can be only reclaimed by some sort of tracing collection.
I don't think one word per cell is a big concern for D, but if it is, this optimization is completely doable without extra effort (because I don't see a reference counting implementation in D without some sort of backup tracing collector).
Mental note
Gather some statistics about cell sizes in D, to see if a word is really a big overhead.
ZCT and cycles
by Leandro Lucarella on 2008- 08- 30 16:08 (updated on 2008- 08- 30 16:08)- with 0 comment(s)
There's not much to think about it (I think ;).
ZCT doesn't help in cycles reclaiming, because ZCT tracks cells with zero count, and cycles can't possibly have a zero count (even using deferred reference counting), because they are, by definition, inter-heap pointers.
Let's see a simple example:
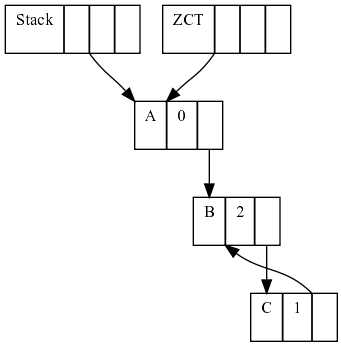
First, we have 3 heap cells, A pointed only by the (thus with rc 0 and added to the ZCT) and B pointed by A and in a cycle with C.
If sometime later, A stop pointing to B, the cycle B-C is not pointed by anything (the ZCT can't do anything about it either), so we lost track of the cycle.
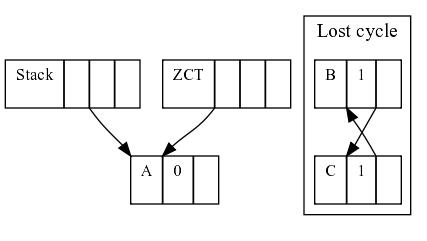
Does this mean that deferred reference counting is useless? I think not. It could still be useful to do some kind of incremental garbage collection, minimizing pauses for a lot of cases. As long as the ZCT reconciliation can find free cells, the pauses of GC would be as short as tracing only the stack, which I think it would be pretty short.
Mental note
See how often cycles are found in tipical D programs.
If the ZCT reconciliation can't find free cells, a full collection should be triggered, using a tracing collector to inspect both the stack and the heap. Alternatively, one can a potential cycle table to store cells which rc has been decremented to a value higher than zero, and then just trace those cells to look for cycles, but we will see this algorithm in more detail in the future.
Avoiding counter updates
by Leandro Lucarella on 2008- 08- 25 03:44 (updated on 2008- 08- 25 03:44)- with 0 comment(s)
The main drawback of reference counting (leaving cycle aside) probably is high overhead it imposes into the client program. Every pointer update has to manipulate the reference counters, for both the old and the new objects.
Function calls
This includes every object passed as argument to a function, which one can guess it would be a lot (every method call for example). However, this kind of rc updates can be easily optimized away. Let's see an example:
class SomeClass
{
void some_method() {}
}
void some_function(SomeClass o)
{
o.some_method();
}
void main()
{
auto o = new SomeClass;
some_function(o);
}
It's clear that o should live until the end of main(), and that there is no chance o could be garbage collected until main() finishes. To express this, is enough to have o's rc = 1. There is no need to increment it when some_function() is called, nor when some_method() is called.
So, theoretically (I really didn't prove it =) is not necessary to update object's rc when used as arguments.
Local pointers update
What about pointers in the stack? Most of the time, pointers updates are done in local variables (pointers in the stack, not in the heap). The GC book talks about 99% of pointers update done in local variables for Lisp and ML. I don't think D could have that much but I guess it could be pretty high too.
Mental note
Gather some statistics about the number of local pointers update vs. heap pointers update in D
Fortunately Deutsch and Bobrow created an algorithm to completely ignore local pointers update, at the cost of relaying on some kind of tracing collector, but that only have to trace the stack (which should be pretty small compared to the heap).
What the algorithm proposes is to use simple assignment when updating local pointers. Pointers living in the heap manipulates rc as usual, but when the count drops to 0, the object is added to a zero count table (ZCT) (and removed if some pointer update increments the counter again).
Finally, at some point (usually when you run out of memory), the ZCT has to be reconciled, doing some simple steps: trace the stack looking for pointers and incrementing their counters and remove any object with rc = 0. Finally, decrement all the counters of the objects pointer to by the stack pointers.
This technique seems to be a good mix of both reference counting and tracing collectors: small pauses (the stack is usually small), low overhead for counter manipulation. The only missing point is cycles. At first sight, if we need a tracing collector for cycles, this algorithm seems pretty useless because you have to trace all the heap and stack to free cycles, so the optimization is lost. Big pauses are here again.
I have the feeling I'm missing something and the ZCT could be useful when comes to reclaim cycles, but I have to think a little more about that.
Lazy freeing RC
by Leandro Lucarella on 2008- 08- 19 02:31 (updated on 2008- 08- 19 02:31)- with 0 comment(s)
The first optimization to analyze is a very simple one. What's the idea behind it lazy freeing? Just transfer some of the work of freeing unused cells to the allocation, making the collection even more interleaved with the mutator.
When you delete a cell, if it's counter drops to 0, instead of recursively free it, just add it to a free-list. Then, when a new cell has to be allocated, take it from the free-list, delete all its children (using the lazy delete, of course), and return that cell.
First drawback of this method: you loose finalization support, but as I said, most people don't care about that. So that's a non-problem. Second, allocation is not that fast anymore. But it's almost bounded. Why almost? Because it's O(N), being N the number of pointers to be deleted in that cell. This doesn't seems like a huge cost anyways (just decrement a counter and, maybe, add it to a free-list). Allocation is (usually) not bounded anyways (except for compacting collectors).
The big win? Bounded freeing. Really small pauses, with no extra costs.
Note
If you have a (simple) program that suffers from GC pauses that you think it could be easily converted to be reference counted (i.e. few pointer updates), please let me know if you want me to try to make it use lazy freeing RC to analyze the real impact on a real-life program.
Reference counting worth a try
by Leandro Lucarella on 2008- 08- 18 23:30 (updated on 2008- 08- 19 02:19)- with 0 comment(s)
Even when I said that reference counting (RC) will be hard in D, I think it worth a try because it's a really easy way to get incremental garbage collection; the collector activity is interleaved with the mutator. And besides it could be hard to add support to the compiler, it's doable by manually incrementing and decrementing the reference counters to evaluate it.
One of the biggest features of RC is its capability to identify garbage cells as soon as they become garbage (let cycles outside that statement =). The killer use for this is finalization support. Unfortunately this feature kills a lot of possible optimizations. On the other hand, D doesn't need finalization support very hard (with the scope statement and other possible RAII D techniques, I think nobody is missing it), so, lucky us, we can drop that feature and think about some optimizations.
RC can help too to all the fuzz about concurrency and sharing in D2 (it's trivial to know when an object is unshared), but that's a different story.
Note
By the way, I don't think RC can make it on his own (yes, because of cycles), but I think it can help a lot to make collection incremental, leaving just a very small ammount of work to a tracing collector.
Basic algorithms summary
by Leandro Lucarella on 2008- 08- 12 03:42 (updated on 2008- 08- 12 04:26)- with 6 comment(s)
Let's make a little summary about the big categories of garbage collection algorithms:
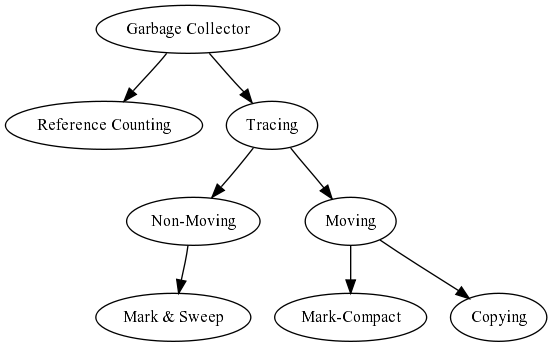
The first branch is reference counting vs. tracing garbage collectors. For D, reference counting is a really complicated choice, because to be (seriously) considered, the compilar/language have to change pretty much. However, one can make some manual bookkeeping to evaluate if this method has considerable advantages over the other to see if that extra work worth the effort.
Tracing garbage collectors is the easy way to go in D. Tracing comes in two flavors: moving and non-moving. Again, moving is hard in D, because all sort of nasty stuff can be done, but a lot more doable than reference counting. In the non-moving field, the major option is the good ol' mark & sweep (the algorithm used by the actual D garbage collector).
Going back to the moving ones, there are two big groups: copying and mark-compact. I don't like copying too much because it need at least double the residency of a program (remember, we are trying not to waste memory =). Mark-compact have some of the advantages of copying without this requirement.
Note
This is just one arbitrary categorization. There are a lot of other categories based on different topis, like: pauses (stop-the-world, incremental, concurrent, real-time), partitioning (generational, connectivity-based), pointer-awareness (precise, conservative) and probably a lot more that I don't even know.
Post your favorite paper!
by Leandro Lucarella on 2008- 08- 11 18:55 (updated on 2008- 08- 12 01:28)- with 1 comment(s)
DGC begins
by Leandro Lucarella on 2008- 08- 10 21:59 (updated on 2008- 08- 11 03:13)- with 2 comment(s)
Ok, here I am.
First of all, this is a blog. Second, this is a blog about my informatics engineering thesis, to finally finish my long long studies at FIUBA (Engineering Faculty of the Buenos Aires University, UBA): a wild try to improve the D Programming Language garbage collector.
But don't expect too much of this blog. It's just a public place where to write my mental notes (in my poor english), things I want to remember for some point in the future.
If you are still interested, here is my plan for the short term:
I'm reading (again) the bible of GC: Garbage Collection: Algorithms for Automatic Dynamic Memory Management by Rafael Lins (whom I had the pleasure to meet in person) and Richard Jones. I'll try to evaluate the posibility of using each and every technique in that book in the D GC, leaving here all my conclusions about it. What I really want in this first (serious) pass is, at least, to discard the algorithms that are clearly not suitable for D.