Recursive vs. iterative marking
by Leandro Lucarella on 2010- 08- 30 00:54 (updated on 2010- 08- 30 00:54)- with 0 comment(s)
After a small (but important) step towards making the D GC truly concurrent (which is my main goal), I've been exploring the possibility of making the mark phase recursive instead of iterative (as it currently is).
The motivation is that the iterative algorithm makes several passes through the entire heap (it doesn't need to do the full job on each pass, it processes only the newly reachable nodes found in the previous iteration, but to look for that new reachable node it does have to iterate over the entire heap). The number of passes is the same as the connectivity graph depth, the best case is where all the heap is reachable through the root set, and the worse is when the heap is a single linked list. The recursive algorithm, on the other hand, needs only a single pass but, of course, it has the problem of potentially consuming a lot of stack space (again, the recurse depth is the same as the connectivity graph depth), so it's not paradise either.
To see how much of a problem is the recurse depth in reality, first I've implemented a fully recursive algorithm, and I found it is a real problem, since I had segmentation faults because the (8MiB by default in Linux) stack overflows. So I've implemented an hybrid approach, setting a (configurable) maximum recurse depth for the marking phase. If the maximum depth is reached, the recursion is stopped and nodes that should be scanned deeply than that are queued to scanned in the next iteration.
Here are some results showing how the total run time is affected by the maximum recursion depth:
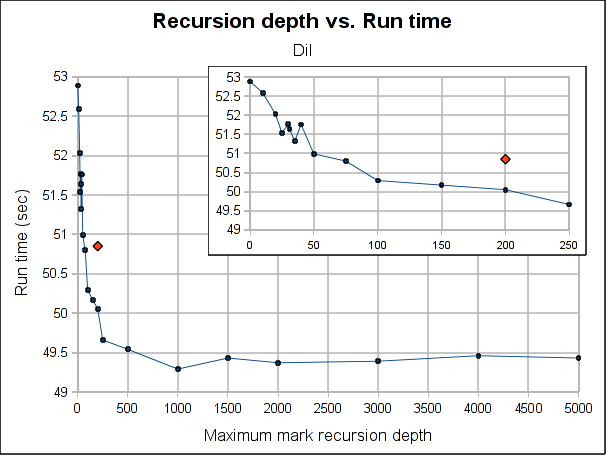
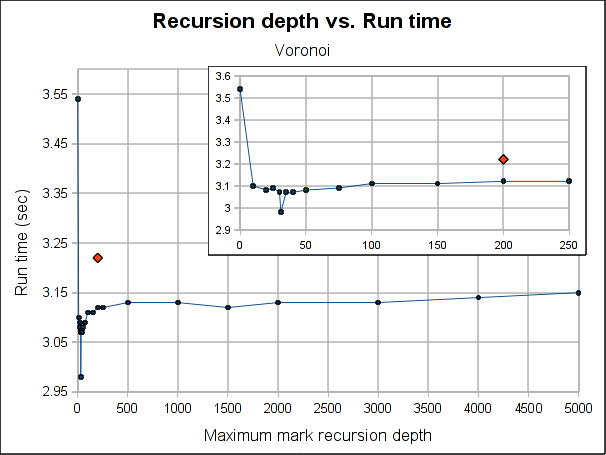
The red dot is how the pure iterative algorithm currently performs (it's placed arbitrarily in the plot, as the X-axis doesn't make sense for it).
The results are not very conclusive. Even when the hybrid approach performs better for both Dil and Voronoi when the maximum depth is bigger than 75, the better depth is program specific. Both have its worse case when depth is 0, which makes sense, because is paying the extra complexity of the hybrid algorithm with using its power. As soon as we leave the 0 depth, a big drop is seen, for Voronoi big enough to outperform the purely iterative algorithm, but not for Dil, which matches it near 60 and clearly outperforms it at 100.
As usual, Voronoi challenges all logic, as the best depth is 31 (it was a consistent result among several runs). Between 20 and 50 there is not much variation (except for the magic number 31) but when going beyond that, it worsen slowly but constantly as the depth is increased.
Note that the plots might make the performance improvement look a little bigger than it really is. The best case scenario the gain is 7.5% for Voronoi and 3% for Dil (which is probably better measure for the real world). If I had to choose a default, I'll probably go with 100 because is where both get a performance gain and is still a small enough number to ensure no segmentation faults due to stack exhaustion is caused (only) by the recursiveness of the mark phase (I guess a value of 1000 would be reasonable too, but I'm a little scared of causing inexplicable, magical, mystery segfaults to users). Anyway, for a value of 100, the performance gain is about 1% and 3.5% for Dil and Voronoi respectively.
So I'm not really sure if I should merge this change or not. In the best case scenarios (which requires a work from the user to search for the better depth for its program), the performance gain is not exactly huge and for a reasonable default value is so little that I'm not convinced the extra complexity of the change (because it makes the marking algorithm a little more complex) worth it.
Feel free to leave your opinion (I would even appreciate it if you do :).