ZCT and cycles
by Leandro Lucarella on 2008- 08- 30 16:08 (updated on 2008- 08- 30 16:08)- with 0 comment(s)
There's not much to think about it (I think ;).
ZCT doesn't help in cycles reclaiming, because ZCT tracks cells with zero count, and cycles can't possibly have a zero count (even using deferred reference counting), because they are, by definition, inter-heap pointers.
Let's see a simple example:
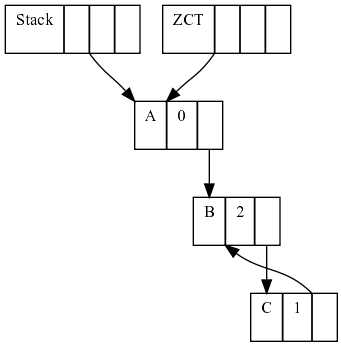
First, we have 3 heap cells, A pointed only by the (thus with rc 0 and added to the ZCT) and B pointed by A and in a cycle with C.
If sometime later, A stop pointing to B, the cycle B-C is not pointed by anything (the ZCT can't do anything about it either), so we lost track of the cycle.
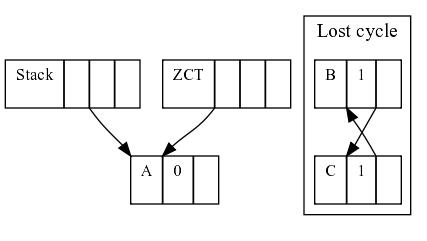
Does this mean that deferred reference counting is useless? I think not. It could still be useful to do some kind of incremental garbage collection, minimizing pauses for a lot of cases. As long as the ZCT reconciliation can find free cells, the pauses of GC would be as short as tracing only the stack, which I think it would be pretty short.
Mental note
See how often cycles are found in tipical D programs.
If the ZCT reconciliation can't find free cells, a full collection should be triggered, using a tracing collector to inspect both the stack and the heap. Alternatively, one can a potential cycle table to store cells which rc has been decremented to a value higher than zero, and then just trace those cells to look for cycles, but we will see this algorithm in more detail in the future.
Avoiding counter updates
by Leandro Lucarella on 2008- 08- 25 03:44 (updated on 2008- 08- 25 03:44)- with 0 comment(s)
The main drawback of reference counting (leaving cycle aside) probably is high overhead it imposes into the client program. Every pointer update has to manipulate the reference counters, for both the old and the new objects.
Function calls
This includes every object passed as argument to a function, which one can guess it would be a lot (every method call for example). However, this kind of rc updates can be easily optimized away. Let's see an example:
class SomeClass
{
void some_method() {}
}
void some_function(SomeClass o)
{
o.some_method();
}
void main()
{
auto o = new SomeClass;
some_function(o);
}
It's clear that o should live until the end of main(), and that there is no chance o could be garbage collected until main() finishes. To express this, is enough to have o's rc = 1. There is no need to increment it when some_function() is called, nor when some_method() is called.
So, theoretically (I really didn't prove it =) is not necessary to update object's rc when used as arguments.
Local pointers update
What about pointers in the stack? Most of the time, pointers updates are done in local variables (pointers in the stack, not in the heap). The GC book talks about 99% of pointers update done in local variables for Lisp and ML. I don't think D could have that much but I guess it could be pretty high too.
Mental note
Gather some statistics about the number of local pointers update vs. heap pointers update in D
Fortunately Deutsch and Bobrow created an algorithm to completely ignore local pointers update, at the cost of relaying on some kind of tracing collector, but that only have to trace the stack (which should be pretty small compared to the heap).
What the algorithm proposes is to use simple assignment when updating local pointers. Pointers living in the heap manipulates rc as usual, but when the count drops to 0, the object is added to a zero count table (ZCT) (and removed if some pointer update increments the counter again).
Finally, at some point (usually when you run out of memory), the ZCT has to be reconciled, doing some simple steps: trace the stack looking for pointers and incrementing their counters and remove any object with rc = 0. Finally, decrement all the counters of the objects pointer to by the stack pointers.
This technique seems to be a good mix of both reference counting and tracing collectors: small pauses (the stack is usually small), low overhead for counter manipulation. The only missing point is cycles. At first sight, if we need a tracing collector for cycles, this algorithm seems pretty useless because you have to trace all the heap and stack to free cycles, so the optimization is lost. Big pauses are here again.
I have the feeling I'm missing something and the ZCT could be useful when comes to reclaim cycles, but I have to think a little more about that.
Lazy freeing RC
by Leandro Lucarella on 2008- 08- 19 02:31 (updated on 2008- 08- 19 02:31)- with 0 comment(s)
The first optimization to analyze is a very simple one. What's the idea behind it lazy freeing? Just transfer some of the work of freeing unused cells to the allocation, making the collection even more interleaved with the mutator.
When you delete a cell, if it's counter drops to 0, instead of recursively free it, just add it to a free-list. Then, when a new cell has to be allocated, take it from the free-list, delete all its children (using the lazy delete, of course), and return that cell.
First drawback of this method: you loose finalization support, but as I said, most people don't care about that. So that's a non-problem. Second, allocation is not that fast anymore. But it's almost bounded. Why almost? Because it's O(N), being N the number of pointers to be deleted in that cell. This doesn't seems like a huge cost anyways (just decrement a counter and, maybe, add it to a free-list). Allocation is (usually) not bounded anyways (except for compacting collectors).
The big win? Bounded freeing. Really small pauses, with no extra costs.
Note
If you have a (simple) program that suffers from GC pauses that you think it could be easily converted to be reference counted (i.e. few pointer updates), please let me know if you want me to try to make it use lazy freeing RC to analyze the real impact on a real-life program.
Reference counting worth a try
by Leandro Lucarella on 2008- 08- 18 23:30 (updated on 2008- 08- 19 02:19)- with 0 comment(s)
Even when I said that reference counting (RC) will be hard in D, I think it worth a try because it's a really easy way to get incremental garbage collection; the collector activity is interleaved with the mutator. And besides it could be hard to add support to the compiler, it's doable by manually incrementing and decrementing the reference counters to evaluate it.
One of the biggest features of RC is its capability to identify garbage cells as soon as they become garbage (let cycles outside that statement =). The killer use for this is finalization support. Unfortunately this feature kills a lot of possible optimizations. On the other hand, D doesn't need finalization support very hard (with the scope statement and other possible RAII D techniques, I think nobody is missing it), so, lucky us, we can drop that feature and think about some optimizations.
RC can help too to all the fuzz about concurrency and sharing in D2 (it's trivial to know when an object is unshared), but that's a different story.
Note
By the way, I don't think RC can make it on his own (yes, because of cycles), but I think it can help a lot to make collection incremental, leaving just a very small ammount of work to a tracing collector.
Basic algorithms summary
by Leandro Lucarella on 2008- 08- 12 03:42 (updated on 2008- 08- 12 04:26)- with 6 comment(s)
Let's make a little summary about the big categories of garbage collection algorithms:
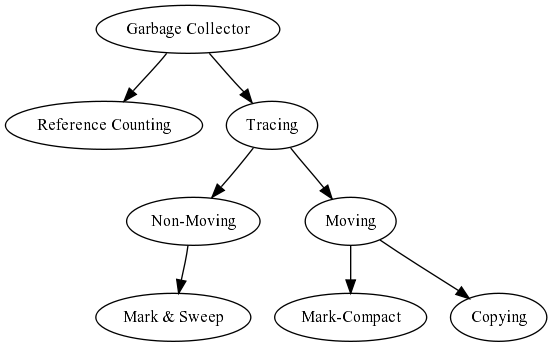
The first branch is reference counting vs. tracing garbage collectors. For D, reference counting is a really complicated choice, because to be (seriously) considered, the compilar/language have to change pretty much. However, one can make some manual bookkeeping to evaluate if this method has considerable advantages over the other to see if that extra work worth the effort.
Tracing garbage collectors is the easy way to go in D. Tracing comes in two flavors: moving and non-moving. Again, moving is hard in D, because all sort of nasty stuff can be done, but a lot more doable than reference counting. In the non-moving field, the major option is the good ol' mark & sweep (the algorithm used by the actual D garbage collector).
Going back to the moving ones, there are two big groups: copying and mark-compact. I don't like copying too much because it need at least double the residency of a program (remember, we are trying not to waste memory =). Mark-compact have some of the advantages of copying without this requirement.
Note
This is just one arbitrary categorization. There are a lot of other categories based on different topis, like: pauses (stop-the-world, incremental, concurrent, real-time), partitioning (generational, connectivity-based), pointer-awareness (precise, conservative) and probably a lot more that I don't even know.
Post your favorite paper!
by Leandro Lucarella on 2008- 08- 11 18:55 (updated on 2008- 08- 12 01:28)- with 1 comment(s)
DGC begins
by Leandro Lucarella on 2008- 08- 10 21:59 (updated on 2008- 08- 11 03:13)- with 2 comment(s)
Ok, here I am.
First of all, this is a blog. Second, this is a blog about my informatics engineering thesis, to finally finish my long long studies at FIUBA (Engineering Faculty of the Buenos Aires University, UBA): a wild try to improve the D Programming Language garbage collector.
But don't expect too much of this blog. It's just a public place where to write my mental notes (in my poor english), things I want to remember for some point in the future.
If you are still interested, here is my plan for the short term:
I'm reading (again) the bible of GC: Garbage Collection: Algorithms for Automatic Dynamic Memory Management by Rafael Lins (whom I had the pleasure to meet in person) and Richard Jones. I'll try to evaluate the posibility of using each and every technique in that book in the D GC, leaving here all my conclusions about it. What I really want in this first (serious) pass is, at least, to discard the algorithms that are clearly not suitable for D.