Presenting CDGC
by Leandro Lucarella on 2010- 07- 28 21:48 (updated on 2010- 07- 28 21:48)- with 0 comment(s)
I've just published the git repository of my D GC implementation: CDGC. The name stands for Concurrent D Garbage Collector but right now you may call it Configurable D Garbage Collector, as there is no concurrency at all yet, but the GC is configurable via environment variables :)
It's based on the Tango (0.99.9) basic GC, there are only few changes at the moment, probably the bigger ones are:
- Runtime configurability using environment variables.
- Logging of malloc()s and collections to easily get stats about time and space consumed by the GC (option malloc_stats_file [str] and collect_stats_file [str]).
- Precise heap scanning based on the patches published in bug 3463 (option conservative [bool]).
- Runtime configurable debug features (option mem_stomp [bool] and sentinel [bool]).
- Other non user-visible cleanups.
The configuration is done via the D_GC_OPTS environment variable, and the format is:
D_GC_OPTS=opt1=value:opt2=value:bool_opt:opt3=value
Where opt1, opt2, opt3 and bool_opt are option names and value is their respective values. Boolean options can omit the value (which means true) or use a value of 0 or 1 to express false and true respectively. String options have no limitations, except they can't have the : char in their values and they have a maximum value length (255 at this moment).
At the moment is a little slower than the Tango basic GC, because the precise scanning is done very naively and a lot of calls to findPool() are done. This will change in the future.
There is a lot of work to be done (cleanup, optimization and the concurrent part :), but I'm making it public because maybe someone could want to adapt some of the ideas or follow the development.
Understanding the current GC
by Leandro Lucarella on 2009- 01- 04 20:37 (updated on 2009- 04- 09 22:53)- with 1 comment(s)
Oh, yeah! A new year, a new air, and the same thesis =)
After a little break, I'm finally starting to analyze the current D (druntime) GC (basic) implementation in depth.
First I want to say I found the code really, but really, hard to read and follow. Things are split in several parts without apparent reason, which make it really hard to understand and it's pretty much undocumented.
I hope I can fully understand it in some time to be able to make a full rewrite of it (in a first pass, conserving the main design).
Overview
I'll start with a big picture overview, and then I'll try to describe each component with more detail.
The implementation in split in several files:
- gcstats.d
- I didn't took a look at this one yet, but I guess it's about stats =).
- gcbits.d
- A custom bitset implementation for collector bit/flags (mark, scan, etc.).
- gcalloc.d
- A wrapper for memory allocation with several versions (malloc, win32, mmap and valloc). 4 functions are provided: map, unmap, commit and decommit. The (de)commit stuff if because (in Sean Kelly's words) Windows has a 2-phase allocation process. You can reserve the address space via map and unmap, but the virtual memory isn't actually created until you call commit. So decommit gets rid of the virtual memory but retains ownership of the address space.
- gcx.d
- The real GC implementation, split in 2 main classes/structs: GC and Gcx. GC seems to be a thin wrapper over Gcx that only provides the allocation logic (alloc/realloc/free) and Gcx seems to be the responsible for the real GC work (and holding the memory).
- gc.d
- This is just a thin wrapper over gcx.d to adapt it to the druntime GC interface.
The Gcx struct is where most magic happens. It holds the GC memory organized in pools. It holds the information about roots, the stack and free list, but in this post I'll focus in the memory pools:
Pool Concept
A pool is a group of pages, each page has a bin size (Bins) and host a fixed number of bins (PAGESIZE / Bins, for example, if Bins == 1024 and PAGESIZE == 4096, the page holds 4 bins).
Each bin has some bits of information:
- mark
- Setted when the Bin is visited by the mark phase.
- scan
- Setted when the Bin is has been visited by the mark phase (the mark bit is set) but it has pointers yet to be scanned.
- free
- Setted when the Bin is free (linked to a free list).
- final
- The object stored in this bin has a destructor that must be called when freed.
- noscan
- This bin should be not scanned by the collector (it has no pointers).
+----------------------------------------+-----+-----------------+ | Page 0 (bin size: Bins) | ... | Page (npages-1) | | | | | | +--------+-----+---------------------+ | | | | | Bin 0 | ... | Bin (PAGESIZE/Bins) | | | | | +--------+-----+---------------------+ | | | | | mark | ... | | | | | | | scan | ... | | | | ... | | | free | ... | ... | | | | | | final | ... | | | | | | | noscan | ... | | | | | | +--------+-----+---------------------+ | | | +----------------------------------------+-----+-----------------+
Pool Implementation
A single chunk of memory is allocated for the whole pool, the baseAddr points to the start of the chunk, the topAddr, to the end. A pagetable holds the bin size (Bins) of each page
. ,-- baseAddr topAddr --,
| ncommitted = i |
| |
|--- committed pages ---,------ uncommitted pages -------|
V | V
+--------+--------+-----+--------+-----+-----------------+
memory | Page 0 | Page 1 | ... | Page i | ... | Page (npages-1) |
+--------+--------+-----+--------+-----+-----------------+
/\ /\ /\ /\ /\ /\
|| || || || || ||
+--------+--------+-----+--------+-----+-----------------+
pagetable | Bins 0 | Bins 1 | ... | Bins i | ... | Bins (npages-1) |
(bin size) +--------+--------+-----+--------+-----+-----------------+
The bin size can be one of:
- B_XXX
- The XXX is a power of 2 from 16 to 4096. The special name B_PAGE is used for the size 4096.
- B_PAGEPLUS
- The whole page is a continuation of a large object (the first page of a large object has size B_PAGE).
- B_FREE
- The page is completely free.
- B_UNCOMMITED
- The page is not committed yet.
- B_MAX
- Not really a value, used for iteration or allocation. Pages can't have this value.
The information bits are stored in a custom bit set (GCBits). npages * PAGESIZE / 16 bits are allocated (since the smallest bin is 16 bytes long) and each bit is addressed using this formula:
bit(pointer) = (pointer - baseAddr) / 16
This means that a bit is reserved each 16 bytes. For large bin sizes, a lot of bits are wasted.
The minimum pool size is 256 pages. With 4096 bytes pages, that is 1 MiB.
The GCBits implementation deserves another post, it's a little complex and I still don't understand why.
Mark-Sweep
by Leandro Lucarella on 2008- 09- 16 02:25 (updated on 2008- 09- 16 02:25)- with 0 comment(s)
After a busy week (unfortunately not working on my thesis), I'll move on to mark-sweep algorithms (I've covered the basic reference counting stuff for now).
The GC book start with some obvious optimizations about making the marking phase non recursive using an explicit stack and methods to handle stack overflow.
Since current D's GC is mark-sweep, I think I have to take a (deeper) look at it now, to see what optimizations is actually using (I don't think D GC is using the primitive recursive algorithm) and take that as the base ground to look for improvements.
Reference counting worth a try
by Leandro Lucarella on 2008- 08- 18 23:30 (updated on 2008- 08- 19 02:19)- with 0 comment(s)
Even when I said that reference counting (RC) will be hard in D, I think it worth a try because it's a really easy way to get incremental garbage collection; the collector activity is interleaved with the mutator. And besides it could be hard to add support to the compiler, it's doable by manually incrementing and decrementing the reference counters to evaluate it.
One of the biggest features of RC is its capability to identify garbage cells as soon as they become garbage (let cycles outside that statement =). The killer use for this is finalization support. Unfortunately this feature kills a lot of possible optimizations. On the other hand, D doesn't need finalization support very hard (with the scope statement and other possible RAII D techniques, I think nobody is missing it), so, lucky us, we can drop that feature and think about some optimizations.
RC can help too to all the fuzz about concurrency and sharing in D2 (it's trivial to know when an object is unshared), but that's a different story.
Note
By the way, I don't think RC can make it on his own (yes, because of cycles), but I think it can help a lot to make collection incremental, leaving just a very small ammount of work to a tracing collector.
Basic algorithms summary
by Leandro Lucarella on 2008- 08- 12 03:42 (updated on 2008- 08- 12 04:26)- with 6 comment(s)
Let's make a little summary about the big categories of garbage collection algorithms:
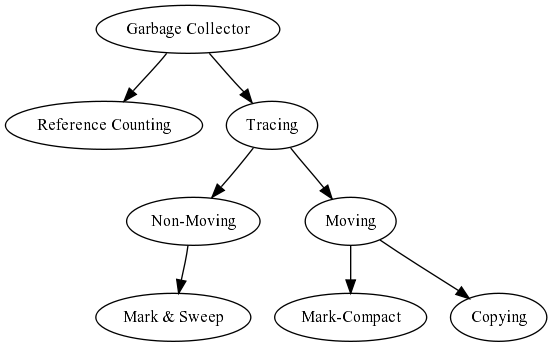
The first branch is reference counting vs. tracing garbage collectors. For D, reference counting is a really complicated choice, because to be (seriously) considered, the compilar/language have to change pretty much. However, one can make some manual bookkeeping to evaluate if this method has considerable advantages over the other to see if that extra work worth the effort.
Tracing garbage collectors is the easy way to go in D. Tracing comes in two flavors: moving and non-moving. Again, moving is hard in D, because all sort of nasty stuff can be done, but a lot more doable than reference counting. In the non-moving field, the major option is the good ol' mark & sweep (the algorithm used by the actual D garbage collector).
Going back to the moving ones, there are two big groups: copying and mark-compact. I don't like copying too much because it need at least double the residency of a program (remember, we are trying not to waste memory =). Mark-compact have some of the advantages of copying without this requirement.
Note
This is just one arbitrary categorization. There are a lot of other categories based on different topis, like: pauses (stop-the-world, incremental, concurrent, real-time), partitioning (generational, connectivity-based), pointer-awareness (precise, conservative) and probably a lot more that I don't even know.
DGC begins
by Leandro Lucarella on 2008- 08- 10 21:59 (updated on 2008- 08- 11 03:13)- with 2 comment(s)
Ok, here I am.
First of all, this is a blog. Second, this is a blog about my informatics engineering thesis, to finally finish my long long studies at FIUBA (Engineering Faculty of the Buenos Aires University, UBA): a wild try to improve the D Programming Language garbage collector.
But don't expect too much of this blog. It's just a public place where to write my mental notes (in my poor english), things I want to remember for some point in the future.
If you are still interested, here is my plan for the short term:
I'm reading (again) the bible of GC: Garbage Collection: Algorithms for Automatic Dynamic Memory Management by Rafael Lins (whom I had the pleasure to meet in person) and Richard Jones. I'll try to evaluate the posibility of using each and every technique in that book in the D GC, leaving here all my conclusions about it. What I really want in this first (serious) pass is, at least, to discard the algorithms that are clearly not suitable for D.