Basic algorithms summary
by Leandro Lucarella on 2008- 08- 12 03:42 (updated on 2008- 08- 12 04:26)- with 6 comment(s)
Let's make a little summary about the big categories of garbage collection algorithms:
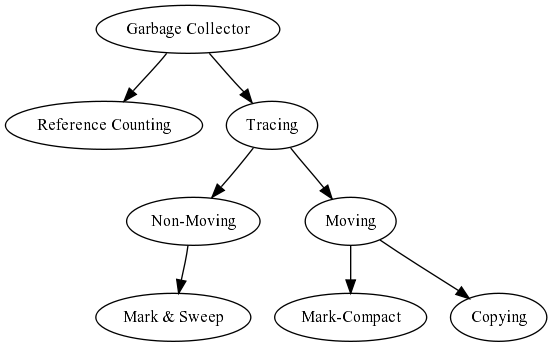
The first branch is reference counting vs. tracing garbage collectors. For D, reference counting is a really complicated choice, because to be (seriously) considered, the compilar/language have to change pretty much. However, one can make some manual bookkeeping to evaluate if this method has considerable advantages over the other to see if that extra work worth the effort.
Tracing garbage collectors is the easy way to go in D. Tracing comes in two flavors: moving and non-moving. Again, moving is hard in D, because all sort of nasty stuff can be done, but a lot more doable than reference counting. In the non-moving field, the major option is the good ol' mark & sweep (the algorithm used by the actual D garbage collector).
Going back to the moving ones, there are two big groups: copying and mark-compact. I don't like copying too much because it need at least double the residency of a program (remember, we are trying not to waste memory =). Mark-compact have some of the advantages of copying without this requirement.
Note
This is just one arbitrary categorization. There are a lot of other categories based on different topis, like: pauses (stop-the-world, incremental, concurrent, real-time), partitioning (generational, connectivity-based), pointer-awareness (precise, conservative) and probably a lot more that I don't even know.
Comment #1
by Leandro Lucarella on 2008-08-12 21:32Thanks for the paper! I've added it to my papers playground.
Basically with regions you get all the protection and abilities of GC, but without any of the overhead.
I didn't read it yet. This sounds unbelievably good. Really, I don't believe it =)
I hope you're right, though!
Some more thoughts I have on areas where D's GC might require some interesting features that aren't usually present in modern GC languages: real-time collection guarantees, O(1) region marking, multithreaded capabilities.
This is one of the big areas where I want to work. One of my primary goals is to minimize and guarantee bounds of GC pauses.
D is a system class language right, so in my opinion mark-sweep pauses are basically unacceptable.
There is a lot to do here. I don't think the standard (or Tango's) D GC even do lazy sweeping (if anyone can confirm before I get my hands dirty in the code, it would be appreciated =). But even when this can reduce pause time, it can't guarantee time bounds.
And in D, what do you get for your hard work of triumphantly parallelizing and algorithm? You get a kick in the nads that's what you get. Everytime collection occurs all of your threads pause.
I hear you bro! This is another big issue I want to tackle. The stop-the-world philosophy is unacceptable!
A lot of these issues are symptoms of tracing based mark-sweep, and I think a reference counting scheme would go a long way to making the GC more usable AND more efficient, but as you pointed out, wouldn't be easy to implement. Plus as we all know cycles can be a real problem.
This is why I don't want to completely discard reference counting. I don't think pure reference counting is the answer either, in the end is more time consuming than tracing GCs, but one of the most limiting features of RC (immediate memory reclamation/finalization) is not needed in D (I don't see anyone complaining about finalization guarantees when you have scope for example). So this leaves a lot of interesting possibilities for using RC just as a help for a tracing GC (you need a tracing backup anyways to reclaim cycles, so...).
I think partitioned GCs can help a lot too in reducing pauses, like generational or connectivity-based GCs. And I want to take a look too at static and dynamic analysis (connectivy-based needs some degree of static analysis), I think it can really improve the GC performance.
Thanks for all your comments! They are very much appreciated.
Comment #2
by Steve L on 2008-08-13 19:08Hi Leandro,
I'm very curious to see how your thesis turns out!
There is a lot to do here. I don't think the standard (or Tango's) D GC even do lazy sweeping (if anyone can confirm before I get my hands dirty in the code, it would be appreciated =).
Just out of curiosity, have you gotten in touch with Walter Bright to pick his brain a bit about the current state of GC in D?
Comment #3
by Paul Houle on 2008-08-13 19:55A generational copying collector doesn't necessarily double your residency requirements. Generational collectors have proven themselves to perform quite well for Java and C# and to be very good for functional programming styles.
Comment #4
by Leandro Lucarella on 2008-08-13 21:01Hi Steve!
I'm very curious to see how your thesis turns out!
Me too! =)
Just out of curiosity, have you gotten in touch with Walter Bright to pick his brain a bit about the current state of GC in D?
I don't think I did. I talked with Sean Kelly more than a year and a half ago (2007-01-03!) when I started but for some personal reasons I could pay much attention to my thesis until now =). I find Tango guys a little more accessible than Walter.
I haven't went down to the code just yet, but when I starting poking around the code, I guess I'll get in touch again with them, and possibly Walter too.
Comment #5
by Leandro Lucarella on 2008-08-13 21:07Hi Paul!
A generational copying collector doesn't necessarily double your residency requirements. Generational collectors have proven themselves to perform quite well for Java and C# and to be very good for functional programming styles.
According to Wikipedia, Microsoft implementation of the CLR is using mark-compact.
Anyways, do you have any source where I can read how a copying collector doesn't need double your residency requirements? Because I think this is pretty much tied to the basics of the algorithm. I know Java perform well with a copying collector, but I was talking about space complexity, not time =)
Java doesn't perform well in terms of space, I think.
Comment #0
by Tim Burrell on 2008-08-12 17:50Since you're doing GC research, have you thought of attempting to implement a region based memory management scheme? I am personally convinced that this a working region based memory management implementation would kick the pants off of GC.
Basically with regions you get all the protection and abilities of GC, but without any of the overhead. See: http://www.itu.dk/~mael/mypapers/pldi2002.pdf for more details.
Either way though, good luck. If any language's GC needs work D is definitely at the top of the list, so any improvements you make will be well received I'm sure.
Some more thoughts I have on areas where D's GC might require some interesting features that aren't usually present in modern GC languages: real-time collection guarantees, O(1) region marking, multithreaded capabilities.
D is a system class language right, so in my opinion mark-sweep pauses are basically unacceptable. D's GC is currently completely useless for any interactive purposes, you almost always have to resort to doing your own memory management. BUT, what if you could simple set the collector to guarantee it will terminate after n nanoseconds. You could partially perform GC whenever you can, and then at some point known to you you could schedule a full collect. Perfect!
Currently marking regions as untraceable is a linear time operation! This is horrible! Not only is the GC unusable for interactive applications but you can't even take the time to mark your regions as untraced and still use D's memory management syntax without overloading new and delete. If the marking operation was O(1) like it should be (some type of hash table perhaps?) this wouldn't be an issue. In case you're wondering I believe this to be an awful problem because writing your own new and delete handlers is even slower than just using malloc and free -- kind of makes using D a bit silly when C is ever handier, let alone C++ with its relatively efficient reference counted pointers.
And finally, multithreaded capabilities. The world is going multicore. Threads are everywhere. And in D, what do you get for your hard work of triumphantly parallelizing and algorithm? You get a kick in the nads that's what you get. Everytime collection occurs all of your threads pause.
A lot of these issues are symptoms of tracing based mark-sweep, and I think a reference counting scheme would go a long way to making the GC more usable AND more efficient, but as you pointed out, wouldn't be easy to implement. Plus as we all know cycles can be a real problem.
This is why I bring up region based mm... it wouldn't require core language modifications and could probably even be implemented as a user space library, although I'd have to think about that some more. Plus it'd be wicked fast, and would make for an interesting thesis / paper I think.